📝 Paper Summary
Domain-specific RAG (Music)
Benchmark creation
The authors introduce a specialized music vector database (MusWikiDB) and a globally diverse artist benchmark (ArtistMus) to enable effective retrieval-augmented question answering in the music domain, significantly outperforming general-purpose models.
Core Problem
General-purpose LLMs lack specific music knowledge, leading to hallucinations on artist details, while existing music benchmarks focus on theory or audio rather than the biographical and historical metadata users actually query.
Why it matters:
- LLMs frequently fail or hallucinate when asked about specific artist careers, discographies, or influences due to sparse pre-training data.
- Traditional fine-tuning is computationally expensive and struggles to keep up with dynamic music information (new albums, milestones).
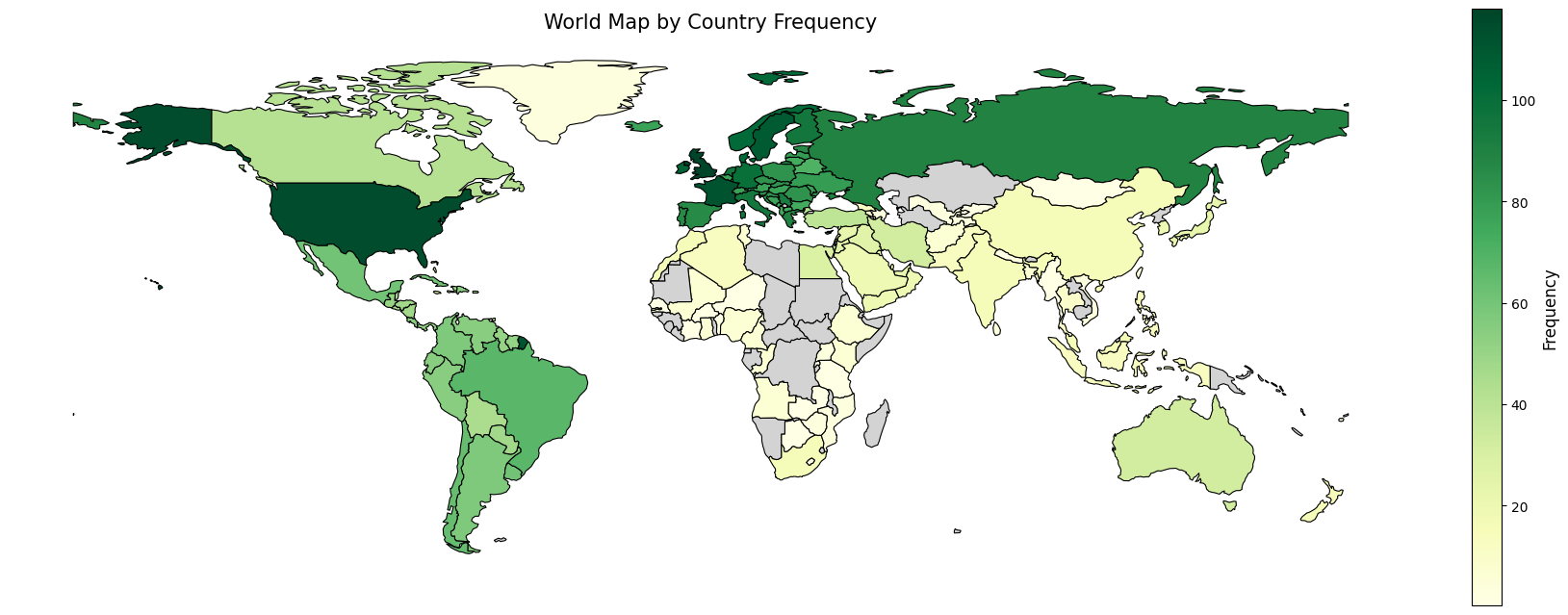
- Existing resources are Western-centric and lack the structured metadata needed to evaluate artist-centric reasoning across global regions.
Concrete Example:
When asking 'Which jazz artists influenced Thad Jones’s move to Copenhagen?', a standard LLM often provides generic or hallucinated responses. The proposed system retrieves specific biographical passages to answer accurately.
Key Novelty
MusWikiDB and ArtistMus Framework
- MusWikiDB: A specialized vector database of 3.2M passages derived from 144K music-specific Wikipedia pages, optimized for music retrieval rather than general knowledge.
- ArtistMus: A benchmark of 1,000 QA pairs covering 500 artists from 163 countries, balancing global representation to correct Western bias.
- Validates RAG-style fine-tuning on (context, question, answer) triples to improve both factual recall and contextual reasoning.
Architecture
The construction process of MusWikiDB and the RAG inference pipeline.
Evaluation Highlights
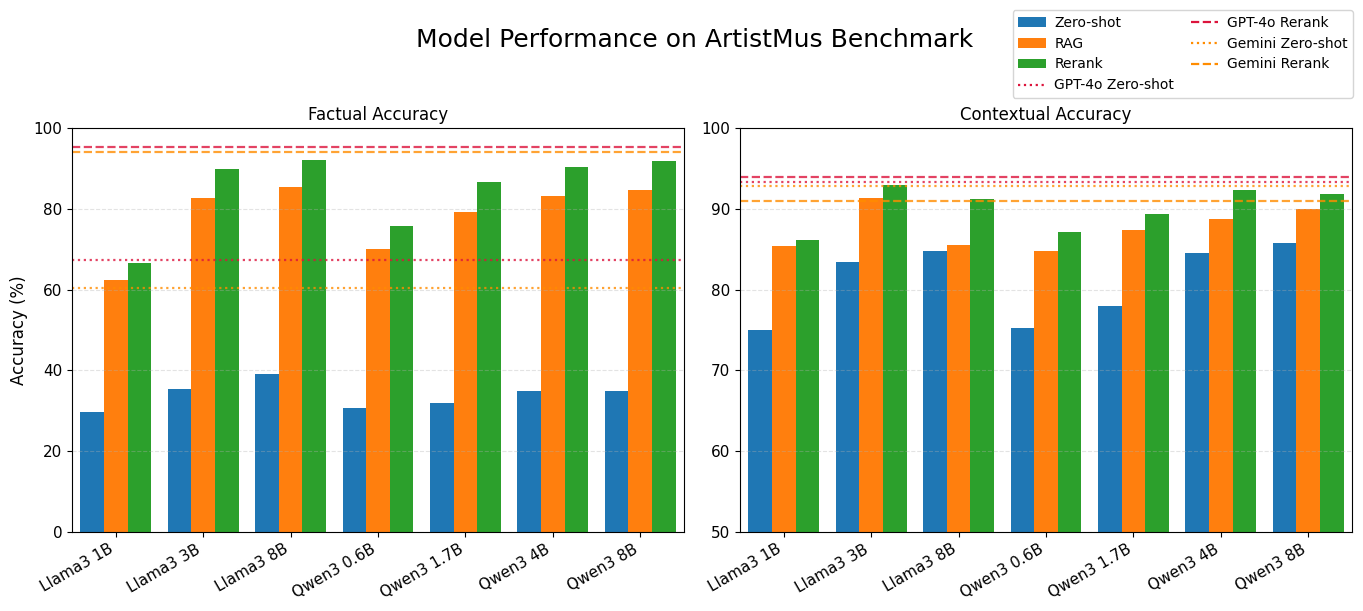
- Open-source models gain up to +56.8 percentage points in factual accuracy using RAG (Qwen3 8B: 35.0% → 91.8%).
- MusWikiDB retrieval yields +6 percentage points higher accuracy and 40% faster retrieval than using the general Wikipedia corpus.
- RAG-style fine-tuning on Llama 3.1 8B improves factual accuracy by +46.4 pp and outperforms standard QA fine-tuning on contextual reasoning.
Breakthrough Assessment
8/10
Addresses a significant gap in domain-specific RAG by providing both a dense retrieval corpus and a culturally diverse benchmark. The massive gains in factual accuracy demonstrate the necessity of domain-specific indexes.