📝 Paper Summary
Multi-agent
Web agents
Agent evolution
WINELL is an agentic framework that autonomously updates Wikipedia articles by inducing section-specific criteria, iteratively aggregating online information via multi-agent search, and generating precise edits using a model fine-tuned on historical human edits.
Core Problem
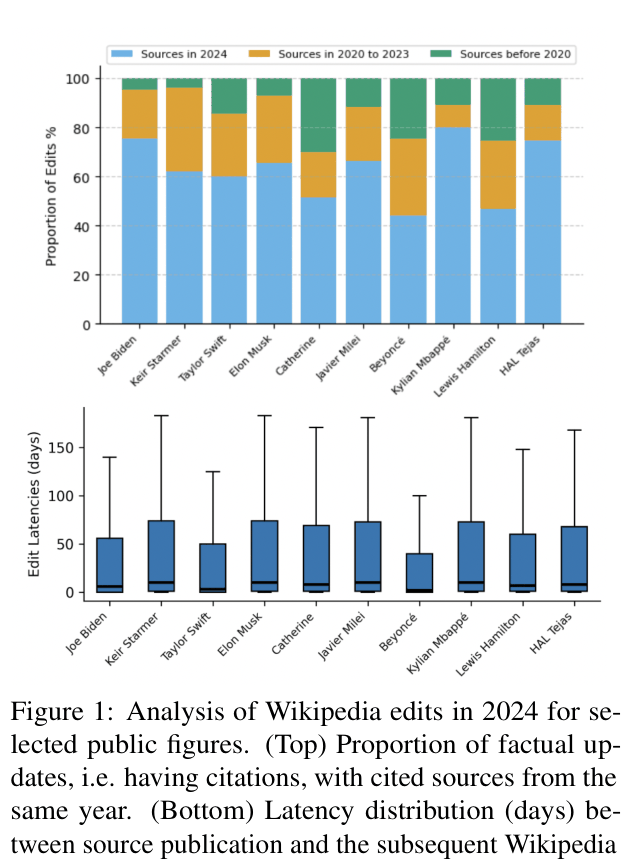
Wikipedia relies on manual edits, causing significant latency between the publication of new information and its incorporation into articles, especially for less popular pages.
Why it matters:
- Manual maintenance cannot keep up with the vast scale of evolving real-world information.
- Existing automated methods focus on infoboxes or assume facts are already given, rather than autonomously discovering and integrating full textual updates.
Key Novelty
An end-to-end agentic loop for 'Never-Ending' Wikipedia updating that combines structural analysis, iterative web search, and human-mimicking fine-grained editing.
- Induces 'Section Criteria' from the article structure to guide relevance.
- Uses a multi-agent 'Navigator-Extractor-Aggregator' loop to find and de-duplicate updates.
- Fine-tunes a specific 'Editor' model on historical human edits to replicate the style and neutrality of Wikipedia contributors.
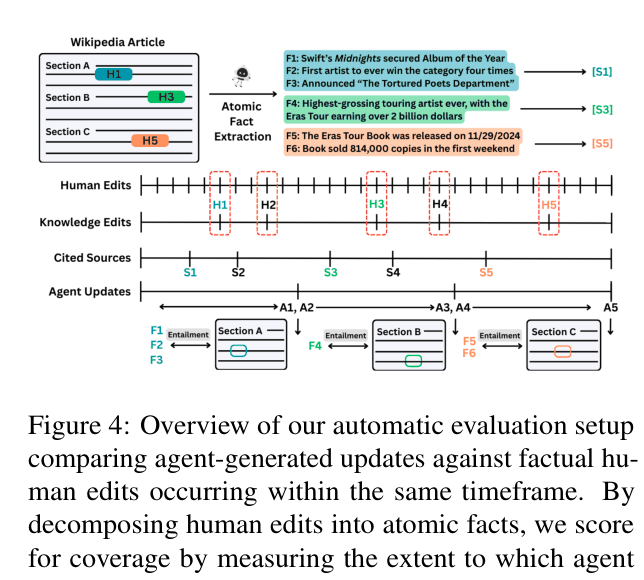
- Introduces an automatic evaluation methodology using historical human edits as ground truth.
Architecture
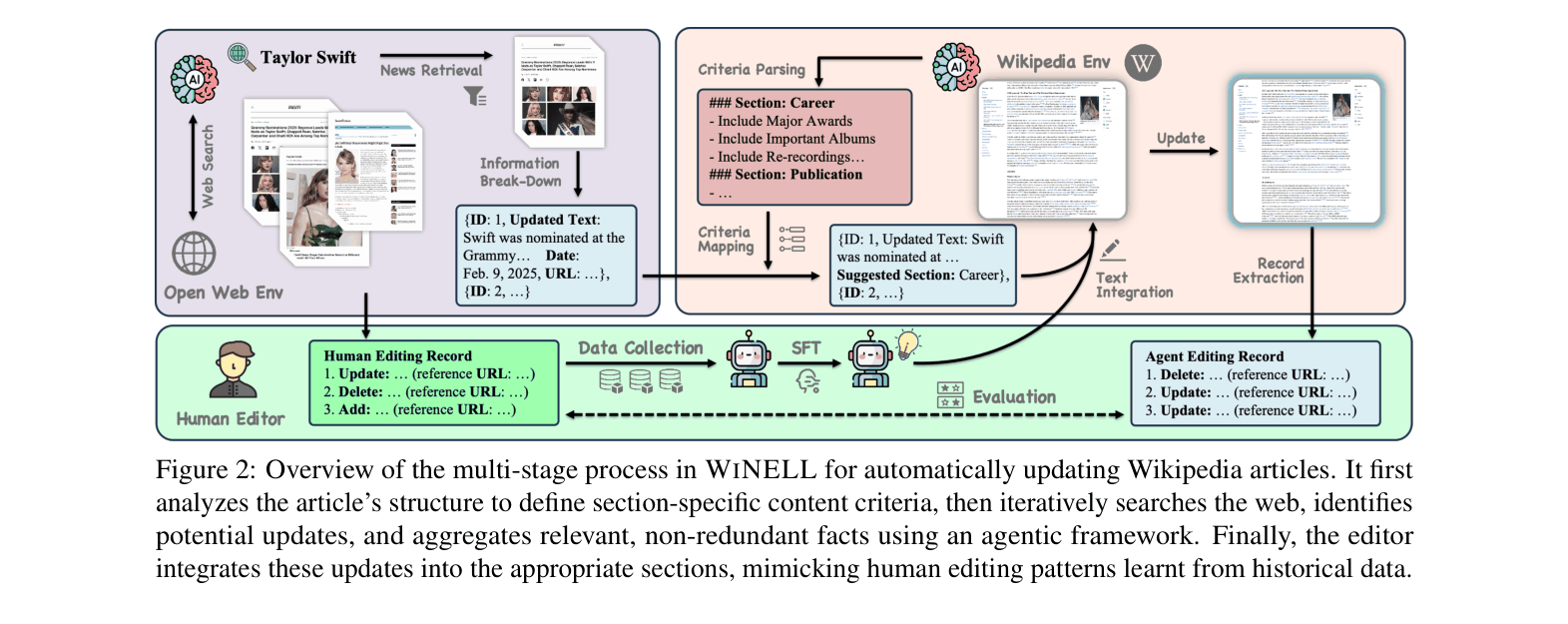
Overview of WINELL pipeline: Article -> Section Criteria -> Agentic Update Aggregation (Loop) -> Fine-Grained Editor -> Updated Article.
Evaluation Highlights
- Fine-grained Editor: The fine-tuned Llama-3.1-8B-Editor achieves 91.7% Key Facts Coverage with only 18.7% Commentary (noise) retention, outperforming GPT-4o (53.1% commentary retention).
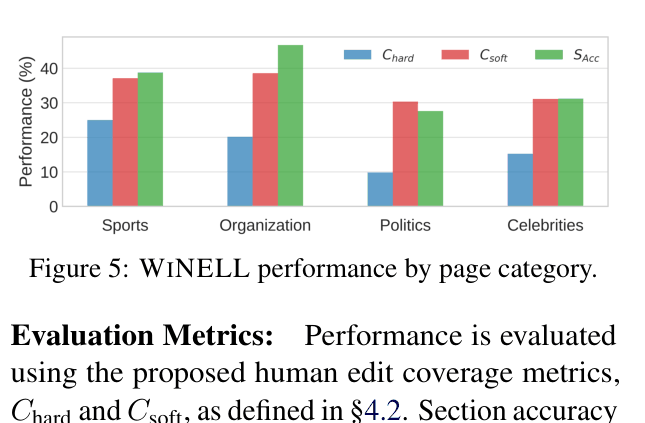
- End-to-End Coverage: WINELL achieves a Soft Coverage (capturing correct facts anywhere) of 34.4% compared to factual human edits.
- Ablation Impact: Removing the agentic search component drops Soft Coverage from 34.4% to 21.5%, showing the value of iterative information seeking.
- Human Evaluation: 68% of WINELL's suggested edits were accepted by experienced Wikipedia editors without revision.
Breakthrough Assessment
7/10
It represents a significant step towards autonomous knowledge base maintenance using agents. The evaluation methodology (simulating historical updates) is clever and rigorous. While current hard coverage (15.4%) shows room for improvement in precise placement, the framework successfully modernizes the NELL concept.