📝 Paper Summary
Modularized RAG pipeline
Representation Learning
Instruction Tuning
GRIT unifies generative and embedding capabilities into a single LLM by distinguishing tasks via instructions, achieving state-of-the-art performance on both without losing efficiency.
Core Problem
Current language models excel at either generation or embedding but not both; using generative models for embeddings yields poor performance, while embedding models lack generative capabilities.
Why it matters:
- RAG pipelines currently require separate models for retrieval and generation, doubling memory overhead and complicating infrastructure
- Using generative model hidden states for embeddings without specific tuning leads to poor retrieval performance
- Separate endpoints for generation and embedding increase load balancing and storage complexity for API providers
Concrete Example:
In a standard RAG setup, a user query must be processed by an embedding model to find context, then both query and context are processed by a separate generative model. This requires loading two large models and prevents caching computations between the retrieval and generation steps.
Key Novelty
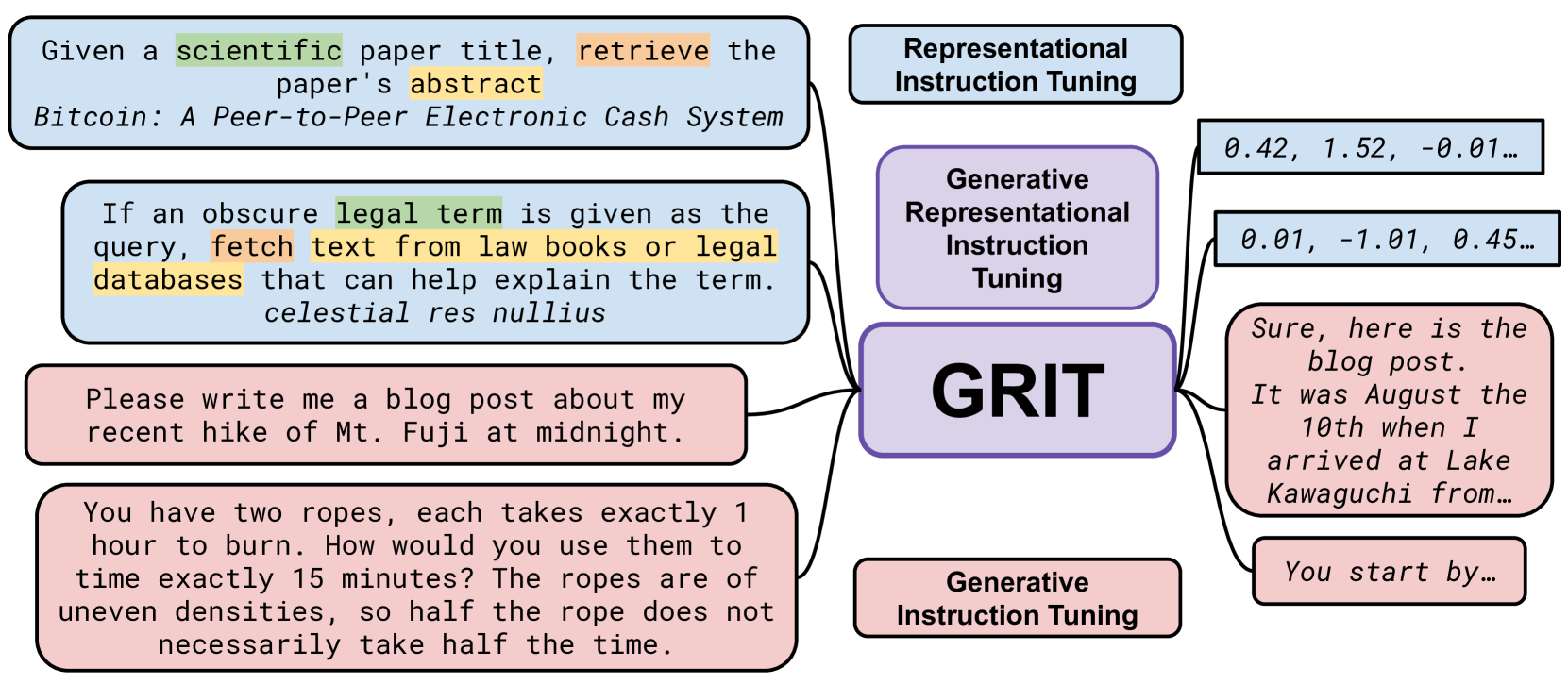
Generative Representational Instruction Tuning (GRIT)
- Trains a single LLM on both generative tasks (predict next token) and embedding tasks (contrastive loss on hidden states) simultaneously using distinguishing instructions
- Allows the same model weights to act as a dense retriever (via embedding instructions) and a generator (via generative instructions), enabling caching of internal states between steps
Architecture
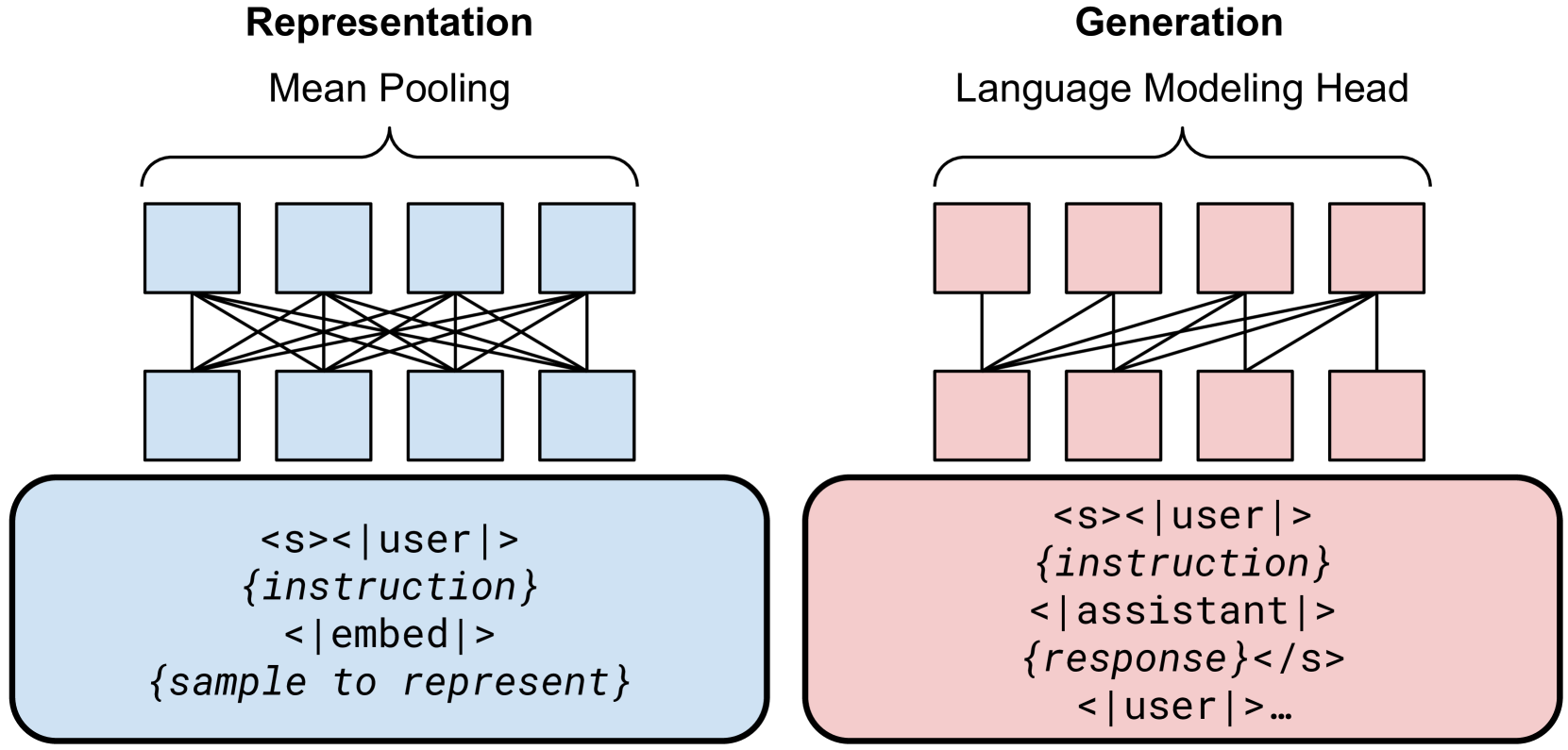
The unified training format for GRIT, showing how different instructions trigger different processing modes (Representation vs. Generation) within the same batch.
Evaluation Highlights
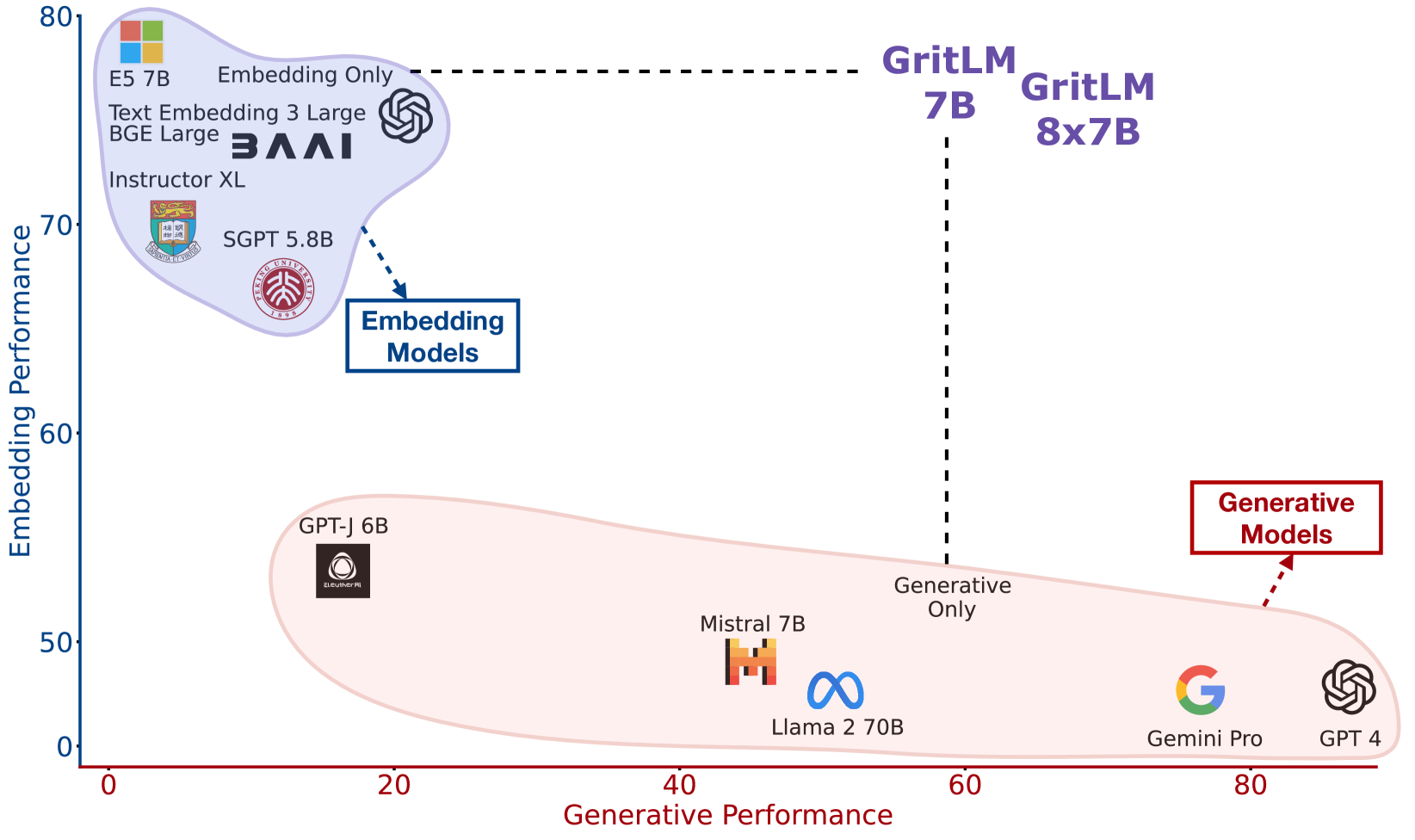
- GritLM 7B sets a new state-of-the-art on the Massive Text Embedding Benchmark (MTEB) among open models (score 66.8), outperforming larger models like Llama 2 70B used for embeddings
- Outperforms Llama 2 70B on generative tasks by >20% while matching embedding-only baselines
- Speeds up RAG inference by >60% for long documents by caching shared computations between the retrieval and generation phases
Breakthrough Assessment
9/10
Successfully unifies two distinct paradigms (generation and embedding) into one model with SOTA results on both. significantly simplifies RAG architecture and improves efficiency.