📝 Paper Summary
Knowledge internalization
Post-training optimization
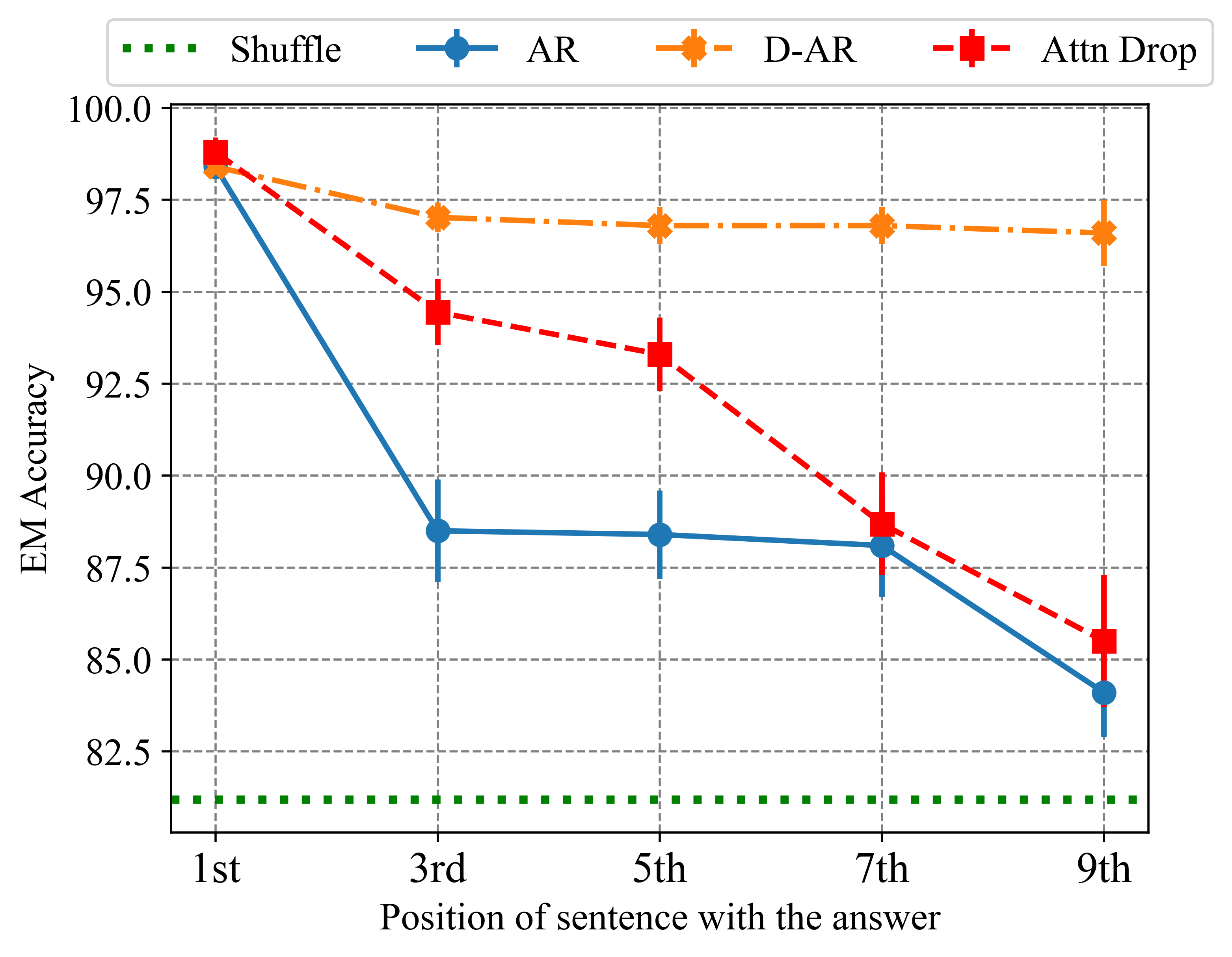
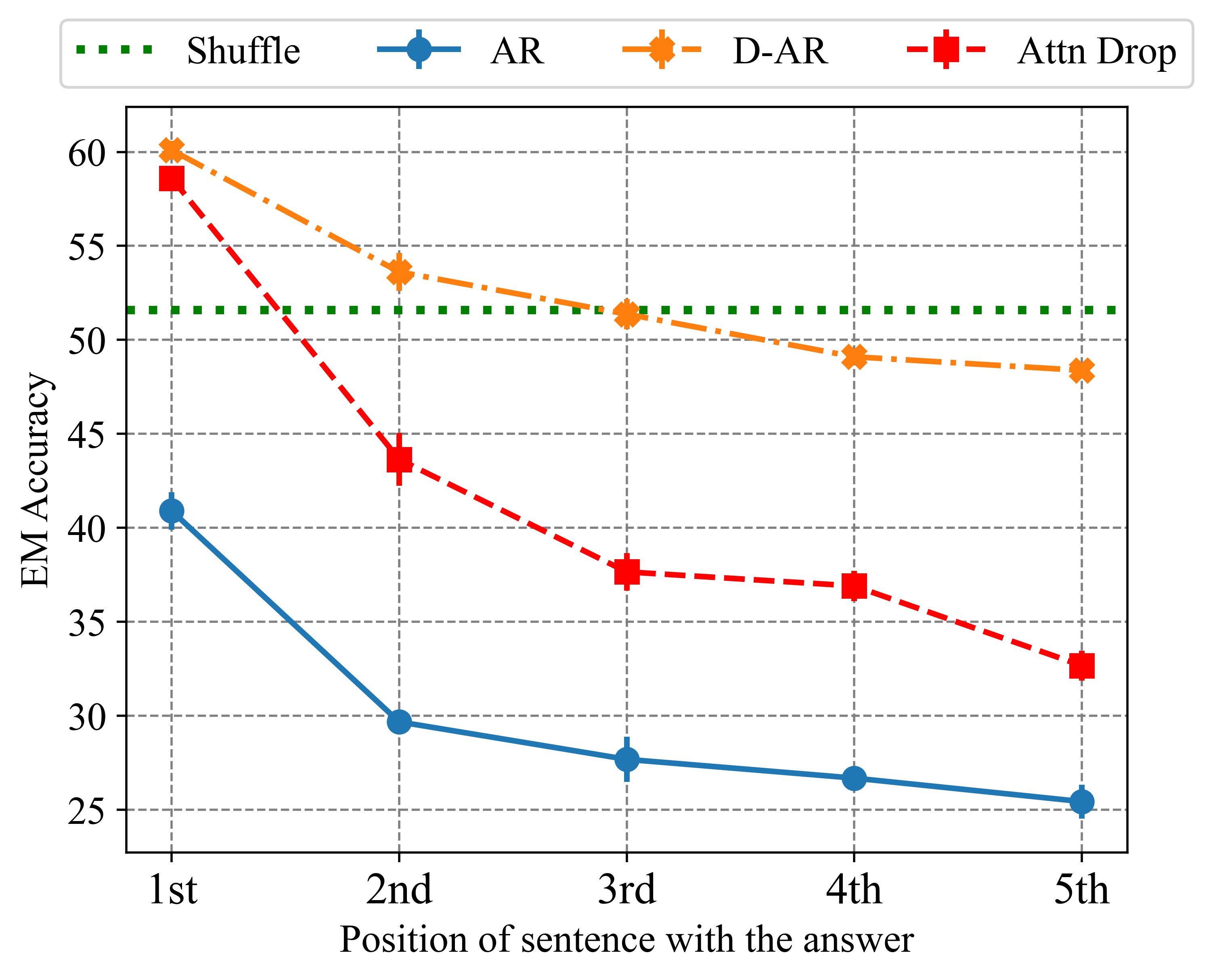
Standard auto-regressive fine-tuning creates a "perplexity curse" where models memorize document tokens sequentially but fail to extract facts located in the middle or end of documents.
Core Problem
Despite minimizing perplexity on training documents, fine-tuned LLMs often fail to answer questions about facts located in the middle or end of those documents.
Why it matters:
- Updating LLMs with new domains via fine-tuning is crucial, but standard methods fail to make that knowledge reliably extractable
- There is a disconnection between the training objective (predict next token given all history) and the inference need (retrieve specific fact given a short query)
- The "perplexity curse" suggests that low training loss does not guarantee effective knowledge acquisition
Concrete Example:
A model trained on a biography document accurately answers questions about the first sentence (e.g., birthday) but fails to answer questions about the last sentence (e.g., hobby), even though it can perfectly reconstruct the document text.
Key Novelty
Denoising Auto-Regressive (D-AR) training for knowledge internalization
- Demonstrates that the auto-regressive objective creates spurious correlations, causing models to rely on the entire preceding context to predict a fact rather than the fact itself
- Proposes randomly corrupting input tokens during training (Denoising Auto-Regressive) to break the rigid dependency on exact token sequences, forcing robust association between concepts
- Combines token corruption with sentence shuffling and attention dropout to further force the model to learn facts independent of their specific position in the training document
Architecture
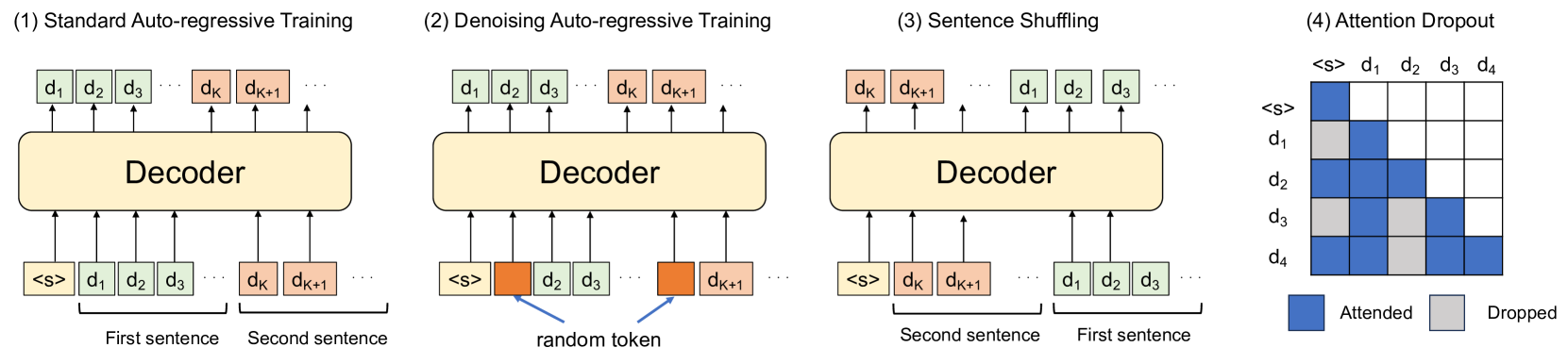
Illustration of three regularization techniques: Denoising Auto-Regressive (D-AR), Shuffling Sentences, and Attention Dropout
Evaluation Highlights
- Denoising Auto-Regressive (D-AR) training improves Exact Match accuracy by +39.7% over standard Auto-Regressive training on the Wiki2023+ film dataset
- D-AR training enables a 13B model to outperform a standard Auto-Regressive 70B model in retrieving facts from all document positions
- On the MedQuAD medical dataset, D-AR improves F1 scores by +5.7 points compared to standard fine-tuning
Breakthrough Assessment
7/10
Identifies a critical, under-explored failure mode in fine-tuning (positional bias in training data) and provides a simple, highly effective fix. The insight about the disconnect between perplexity and extractability is valuable.