📝 Paper Summary
Commonsense Reasoning
Knowledge Evaluation
Benchmark Construction
CoCo is an automatically constructed benchmark that evaluates whether LLMs consistently understand and apply commonsense knowledge rather than just memorizing it, revealing significant gaps between retrieval and reasoning.
Core Problem
Existing commonsense evaluations focus on downstream task performance, failing to distinguish whether correct answers stem from true understanding or rote memorization, and often suffer from data contamination.
Why it matters:
- High accuracy on standard benchmarks may mask a lack of genuine reasoning ability if models merely memorize the test set
- Current methods rely heavily on manual annotation, making large-scale, consistent evaluation of specific knowledge triples difficult
- Without measuring consistency, it is impossible to know if an LLM's reasoning failure is due to a lack of knowledge or an inability to apply it
Concrete Example:
A model might correctly answer a complex reasoning question about 'PersonX playing football', yet fail to answer a simple direct question about the specific effect (getting tired) that validates it knows the underlying fact.
Key Novelty
Consistency of Commonsense (CoCo) Benchmark
- Constructs a three-tier evaluation (Memorization, Comprehension, Application) derived from the same underlying Atomic knowledge triples
- Reverses the typical evaluation direction: starts with atomic facts from a Knowledge Graph, then generates conceptual and multi-hop reasoning questions based on those specific facts
- Introduces consistency metrics (e.g., FAISCORE) that only credit reasoning success if the model also demonstrates possession of the prerequisite atomic knowledge
Architecture
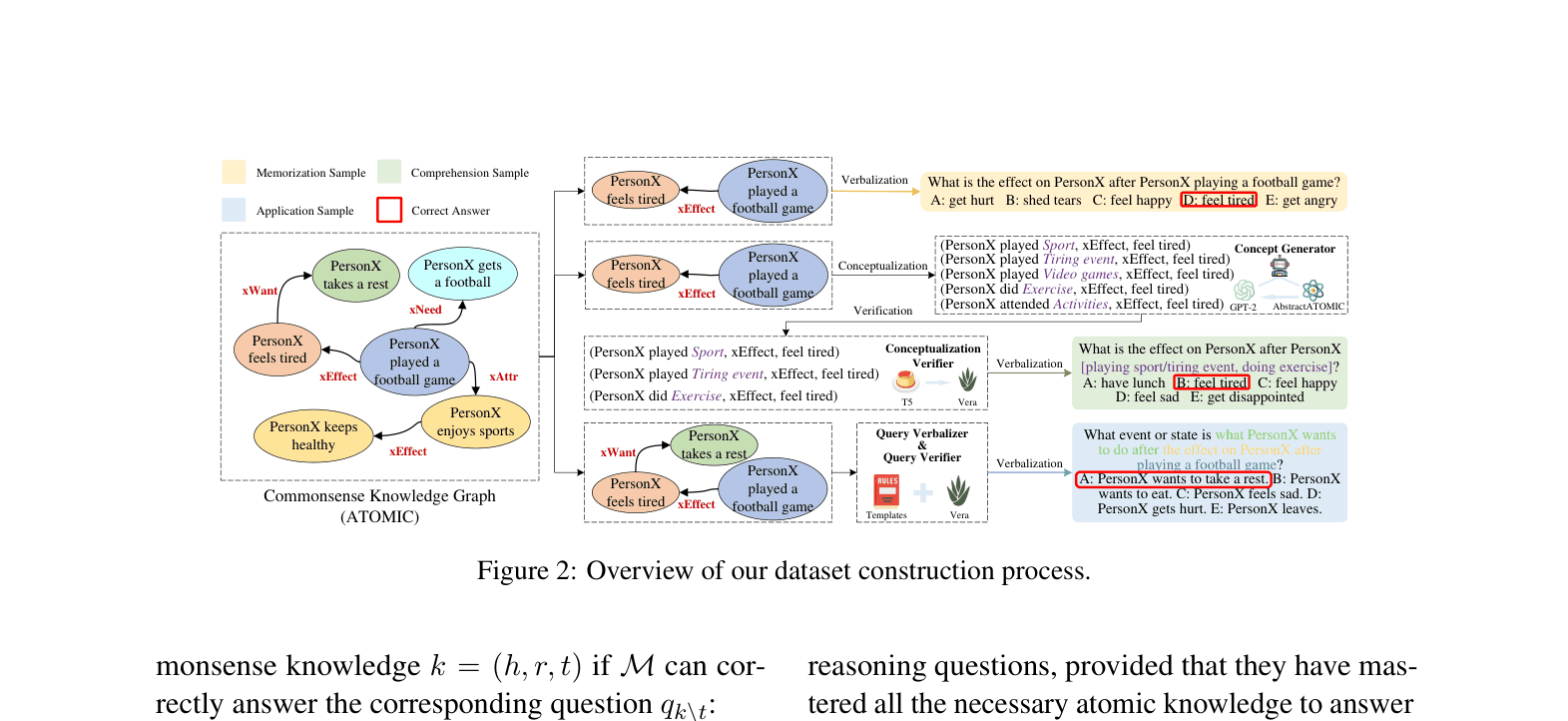
The automated data construction pipeline for CoCo.
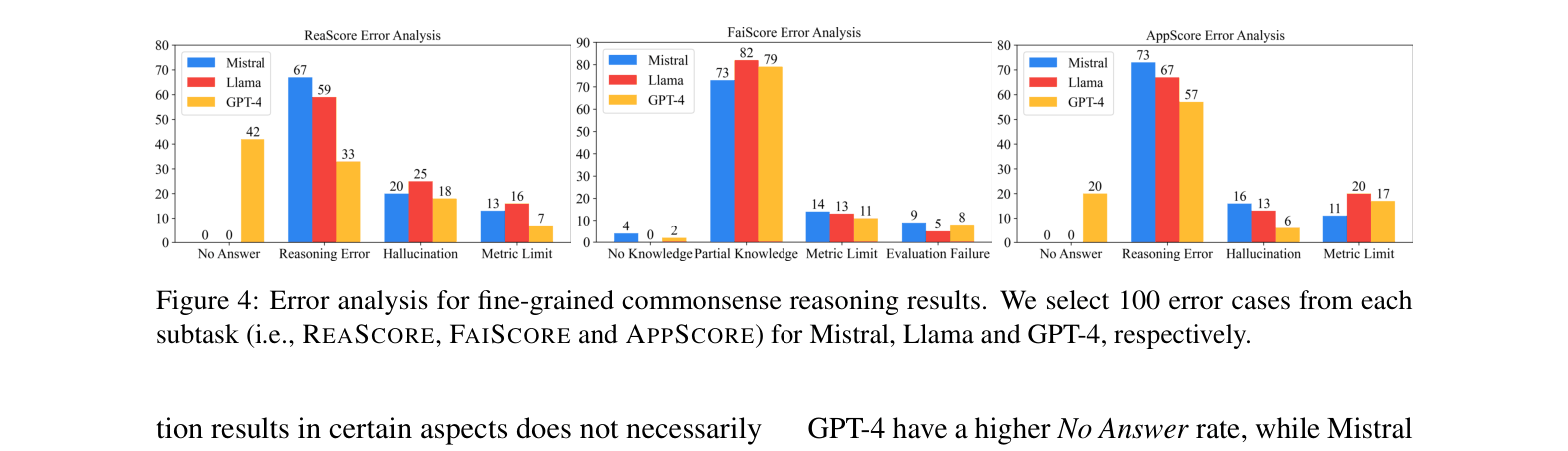
Evaluation Highlights
- GPT-4 achieves the highest performance but still lags behind human performance by 17.7% on average across tasks
- While GPT-4 scores 81.66% on Memorization, its Faithfulness Score (consistency between knowledge and reasoning) drops to 55.49%, indicating frequent hallucination or lucky guesses
- KnowCoT (Knowledge-based Chain-of-Thought) improves GPT-4's Application Score by ~3.7 points over vanilla prompting, enhancing consistency
Breakthrough Assessment
7/10
Strong methodological contribution in automated benchmark construction and consistency metrics. The results expose a critical weakness in current LLMs (knowledge-reasoning disconnect), though the approach relies on existing knowledge graphs.