📝 Paper Summary
Modularized RAG pipeline
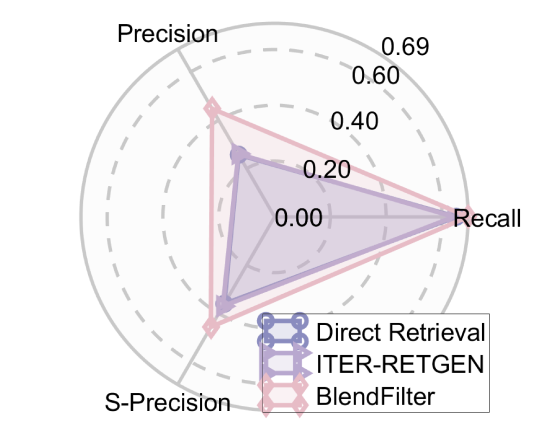
Retrieval
BlendFilter improves RAG performance by blending external and internal knowledge to augment queries, followed by a filtering step where the LLM itself selects only relevant retrieved documents before answering.
Core Problem
RAG systems struggle with complex questions that lack explicit keywords for retrieval, and retrieved documents often contain irrelevant noise that confuses the LLM.
Why it matters:
- Simple queries for complex tasks often miss key information, leading to retrieval failure
- Standard retrieval often fetches noisy, irrelevant documents that hallucinate or distract the model
- Existing query augmentation methods typically rely on a single source (internal or external), limiting coverage
Concrete Example:
For a multi-hop question about implicit sub-problems, a standard retriever might miss documents because the original query lacks specific keywords. Even if documents are found, top-K retrieval may include irrelevant text that misleads the final answer generation.
Key Novelty
Query Generation Blending + LLM-as-a-Filter
- Generates three query variants: the original query, one augmented with external knowledge (via Chain-of-Thought), and one augmented with internal LLM knowledge
- Uses the LLM itself to act as a semantic filter, reading retrieved documents from all three query streams and discarding irrelevant ones before final answer generation
Architecture
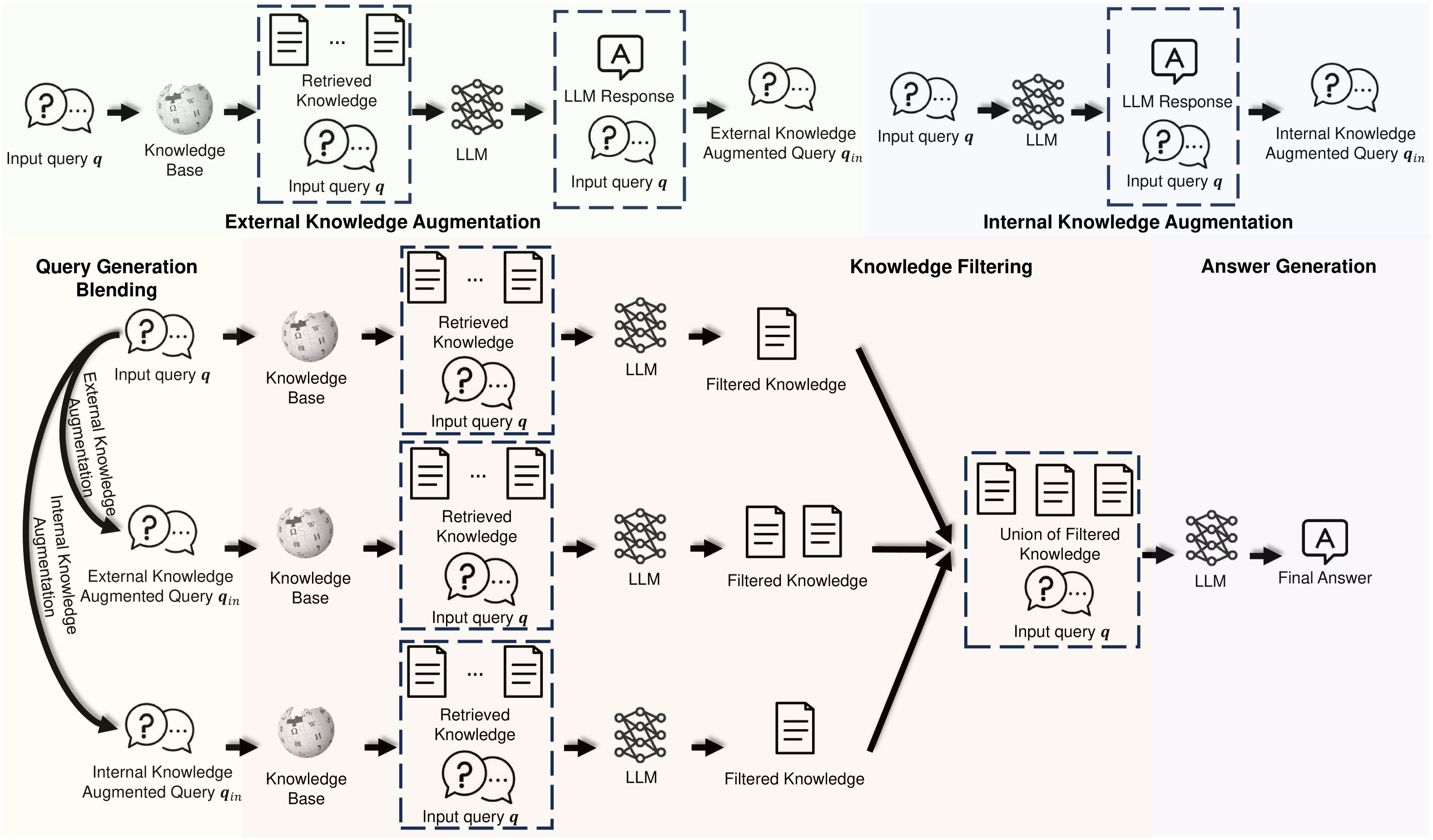
Overview of the BlendFilter framework, illustrating the query blending and knowledge filtering processes.
Evaluation Highlights
- Outperforms state-of-the-art baselines on 2WikiMultihopQA by up to +6.81% (Exact Match) using Llama-2-7b-chat
- Achieves significant gains on HotpotQA (+4.67% EM vs. Self-RAG) using Llama-2-13b-chat
- Consistently improves performance across three different backbone models (Llama-2-7b, Llama-2-13b, GPT-3.5-turbo-Instruct)
Breakthrough Assessment
7/10
Strong empirical results and a logical combination of augmentation sources. The idea of using the LLM itself as a filter is effective but computationally expensive compared to lightweight classifiers.