📝 Paper Summary
Modularized RAG pipeline
Aligned Query Expansion (AQE) fine-tunes large language models to generate query expansions that directly maximize retrieval effectiveness, eliminating the need for costly post-generation filtering steps.
Core Problem
Generative query expansion using LLMs often produces hallucinations or suboptimal queries, and current solutions rely on a computationally expensive 'generate-then-filter' paradigm.
Why it matters:
- Current filtering methods require generating dozens of queries and running a relevance model on each, increasing latency and cost
- Standard LLMs are not inherently aligned to prioritize terms that maximize downstream retrieval metrics like BM25 ranking
- Vocabulary mismatch remains a critical bottleneck in sparse retrieval systems where user queries do not match document terms
Concrete Example:
A user asks about 'symptoms of flu'. A standard LLM might generate 50 expansions, some irrelevant or hallucinated. Current methods (like EAR) must generate all 50 and use a separate ranker to filter them, wasting compute. AQE's model is trained to generate only the effective terms in one shot.
Key Novelty
Direct Alignment for Query Expansion (AQE)
- Instead of filtering outputs after generation, AQE fine-tunes the generator itself using reinforcement learning techniques (RSFT or DPO) to prefer expansions that result in better retrieval rankings.
- It treats the retrieval rank of the ground-truth document as the reward signal, aligning the generation probability with retrieval success.
Architecture
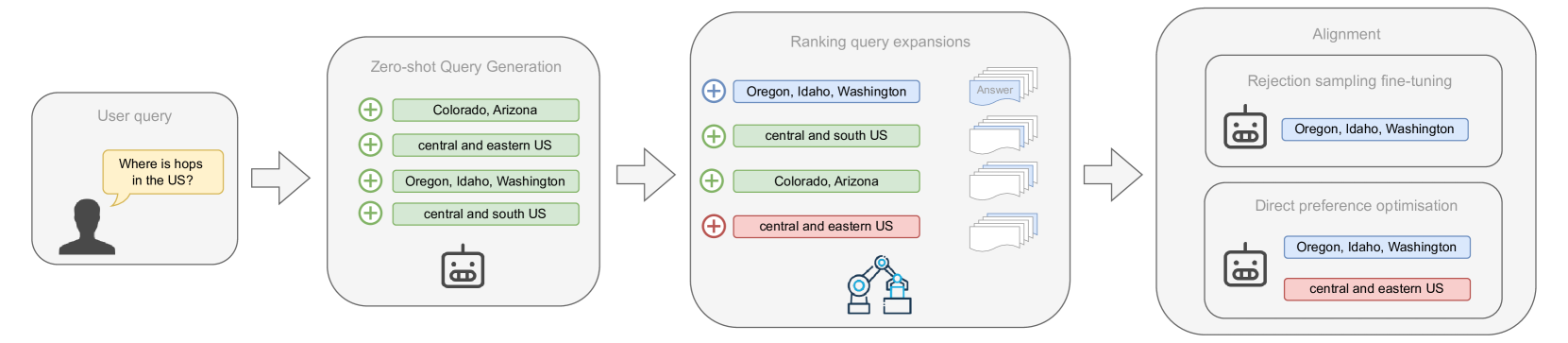
The training pipeline for Aligned Query Expansion (AQE)
Evaluation Highlights
- Reduces inference latency by approximately 70% compared to generate-then-filter approaches like EAR
- Outperforms baseline methods (GAR, EAR) in retrieval effectiveness across both in-domain and out-of-domain datasets
- Demonstrates significant gains in Recall@1000 and MRR@10 compared to standard zero-shot prompting
Breakthrough Assessment
7/10
Offers a strong efficiency improvement (70% latency reduction) while maintaining or improving accuracy. Applying alignment techniques (DPO) directly to the retrieval objective is a logical and effective step forward.