📝 Paper Summary
Graph-based RAG pipeline
KG-Rank augments LLMs for medical QA by retrieving triples from a knowledge graph and refining them via multi-stage ranking to provide factual, non-redundant context for answer generation.
Core Problem
General LLMs lack medical training data and factual consistency, while standard retrieval methods often introduce irrelevant or redundant noise that compromises credibility.
Why it matters:
- Medical advice requires high precision; inaccurate LLM outputs can lead to critical health risks
- Merely retrieving external knowledge risks introducing irrelevant information that distracts the model
- Prior works utilized external knowledge but overlooked how to optimally order and filter that knowledge to reduce noise and redundancy
Concrete Example:
When asking about diet for a patient with acute renal and hepatic failure, a standard LLM suggests 1.6-2.2g/kg protein (dangerous), whereas KG-Rank correctly identifies the need for restricted intake (0.8-1g/kg) by retrieving and prioritizing specific medical contraindications.
Key Novelty
Knowledge Graph Retrieval with Multi-Stage Ranking
- Combines structured knowledge graph retrieval (triplets) with three distinct ranking strategies (Similarity, Answer Expansion, MMR) to filter noise
- Applies a specialized re-ranking step using a medical cross-encoder to rigorously select only the most factually relevant triples before generation
- Integrates Maximal Marginal Relevance (MMR) to specifically reduce redundancy in retrieved medical facts, ensuring diverse yet concise context
Architecture
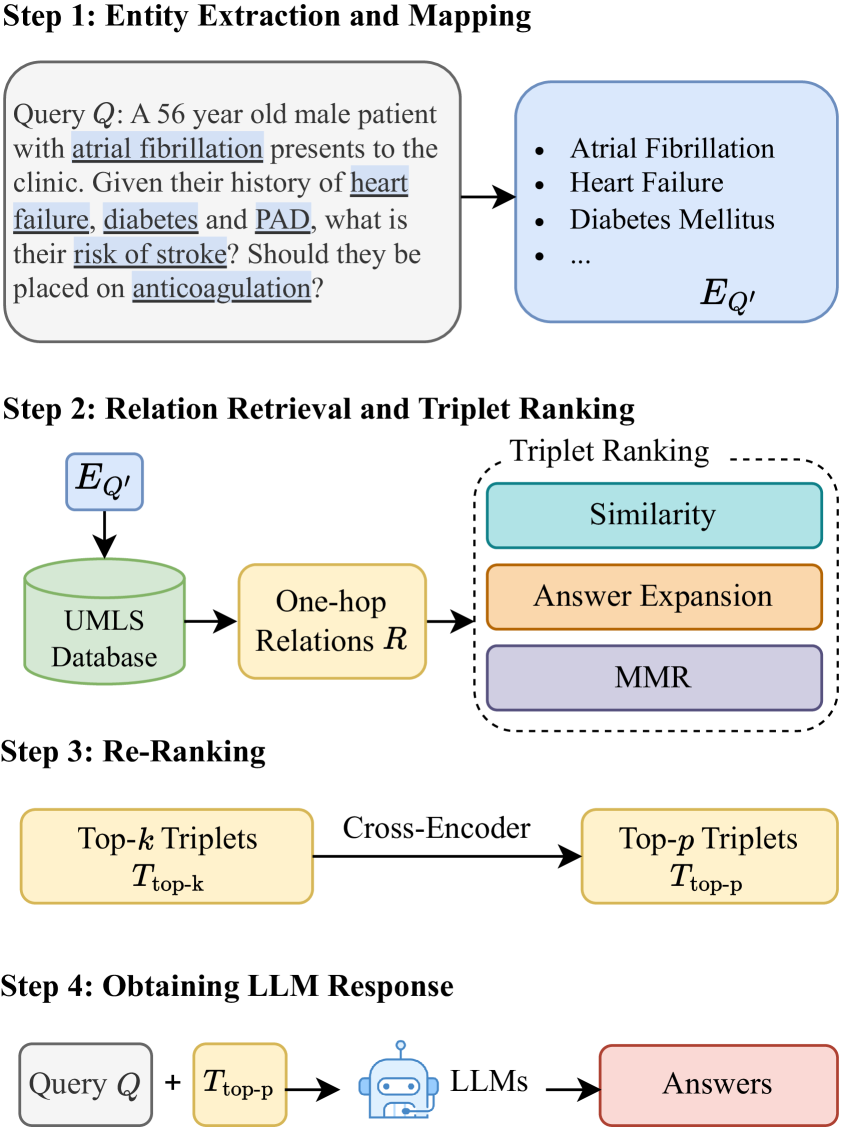
The complete workflow of the KG-Rank framework, from entity extraction to answer generation.
Evaluation Highlights
- +18% improvement in ROUGE-L score on the ExpertQA-Bio dataset compared to zero-shot baselines
- Outperforms standard RAG baselines on 4 medical QA datasets (LiveQA, ExpertQA-Med, ExpertQA-Bio, MedicationQA) in automated metrics
- +14% improvement in ROUGE-L score when extended to open domains (Law, Business, Music, History) using DBpedia
Breakthrough Assessment
7/10
Strong empirical gains in the high-stakes medical domain using a logical pipeline of KG retrieval and ranking. While the components (MMR, cross-encoders) are known, their specific application to graph-based medical RAG is effective.
