📝 Paper Summary
Memory organization
Knowledge internalization
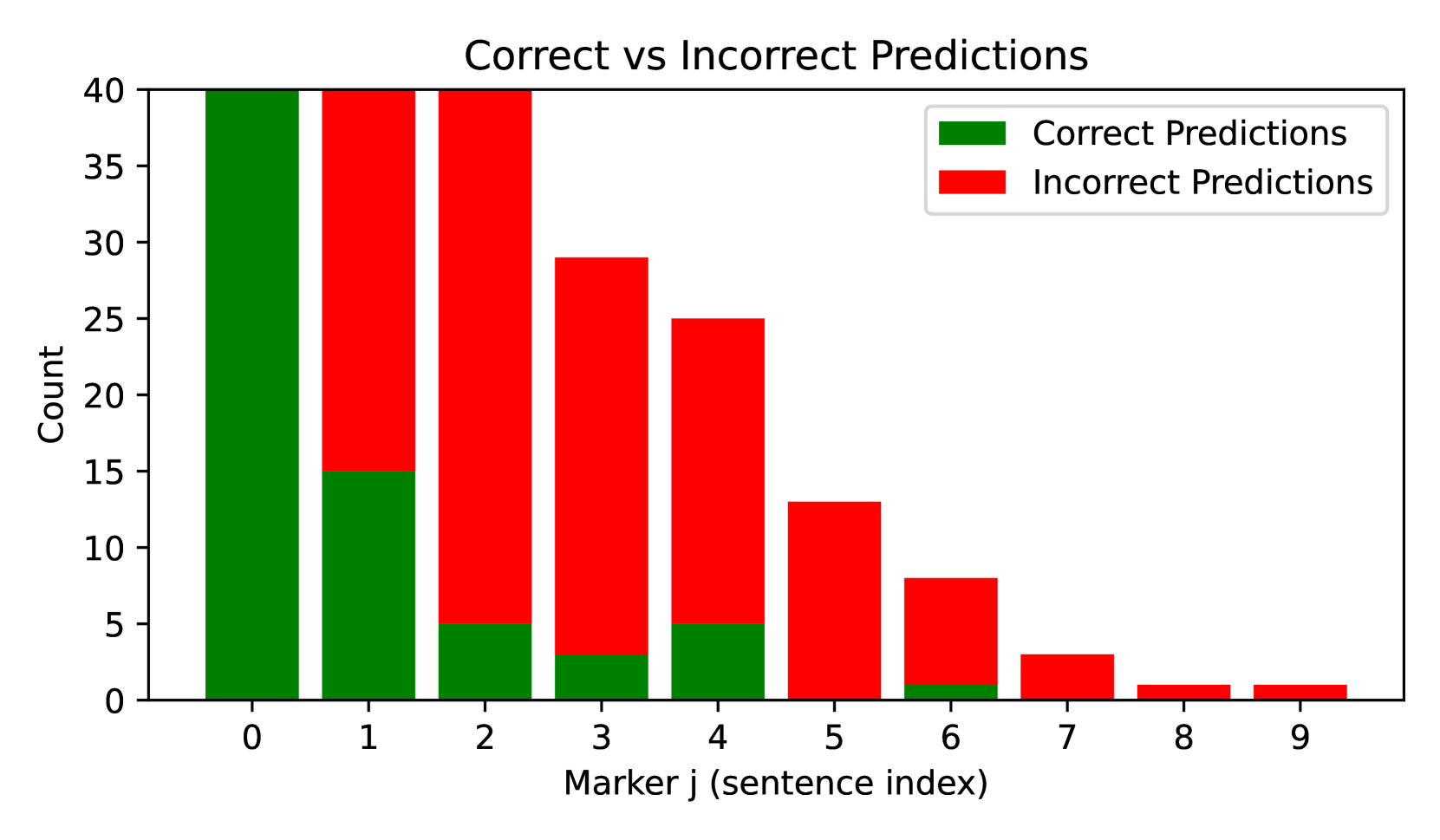
Language models struggle to randomly access specific segments of memorized text despite having memorized the full content, but explicit recitation of the content prior to answering mitigates this failure.
Core Problem
While Language Models (LMs) can effectively memorize and reproduce long passages sequentially, they fail to access specific information located in the middle of these memorized passages when prompted with a unique identifier.
Why it matters:
- Treating LMs as knowledge bases requires reliable retrieval of specific facts, not just full rote memorization
- Current inability to perform random access limits the utility of LMs in grounded question answering where precise extraction is needed
- Understanding this limitation sheds light on the fundamental mechanisms of how transformers store and index information in their parameters
Concrete Example:
A model memorizes a passage about Chopin associated with ID '#3022'. If asked to recite the whole passage given '#3022', it succeeds. However, if asked 'According to Document #3022, in what year did Chopin become a French citizen?' (requiring extraction from the middle), the model fails to output the correct year, acting as if it hasn't memorized the text.
Key Novelty
Distinction between Sequential and Random Parametric Memory Access
- Formalizes the difference between 'Sequential Access' (generating from the start token) and 'Random Access' (generating from an arbitrary mid-point) in LMs trained on key-value pairs
- Demonstrates that simply permuting sentence order during training helps the model unlearn the rigid sequential dependency, improving random access
- Proposes 'Recitation' at inference time: forcing the model to output the full memorized passage before answering a specific question allows it to bypass the random access bottleneck
Architecture
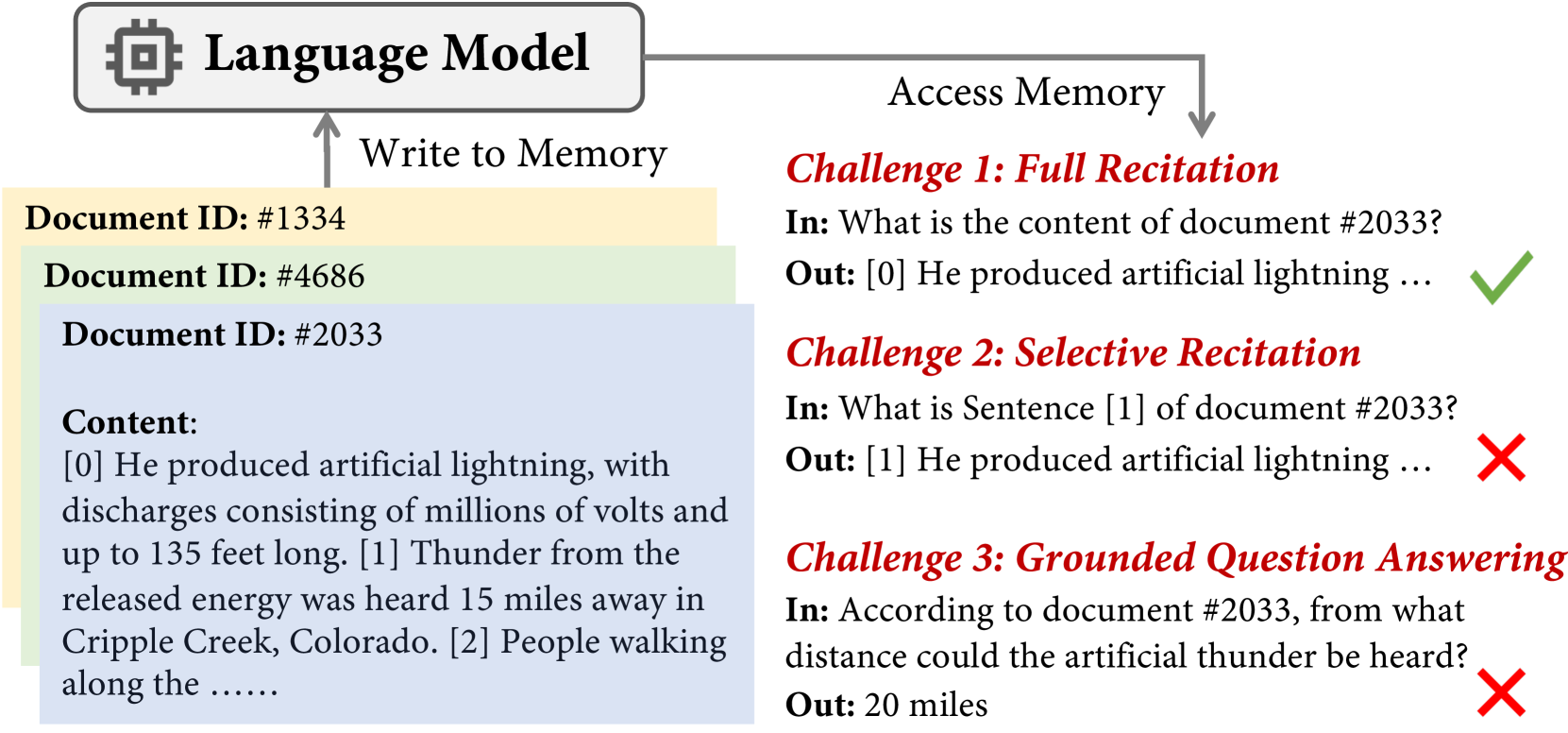
Conceptual illustration of Sequential vs. Random Memory Access in LMs
Evaluation Highlights
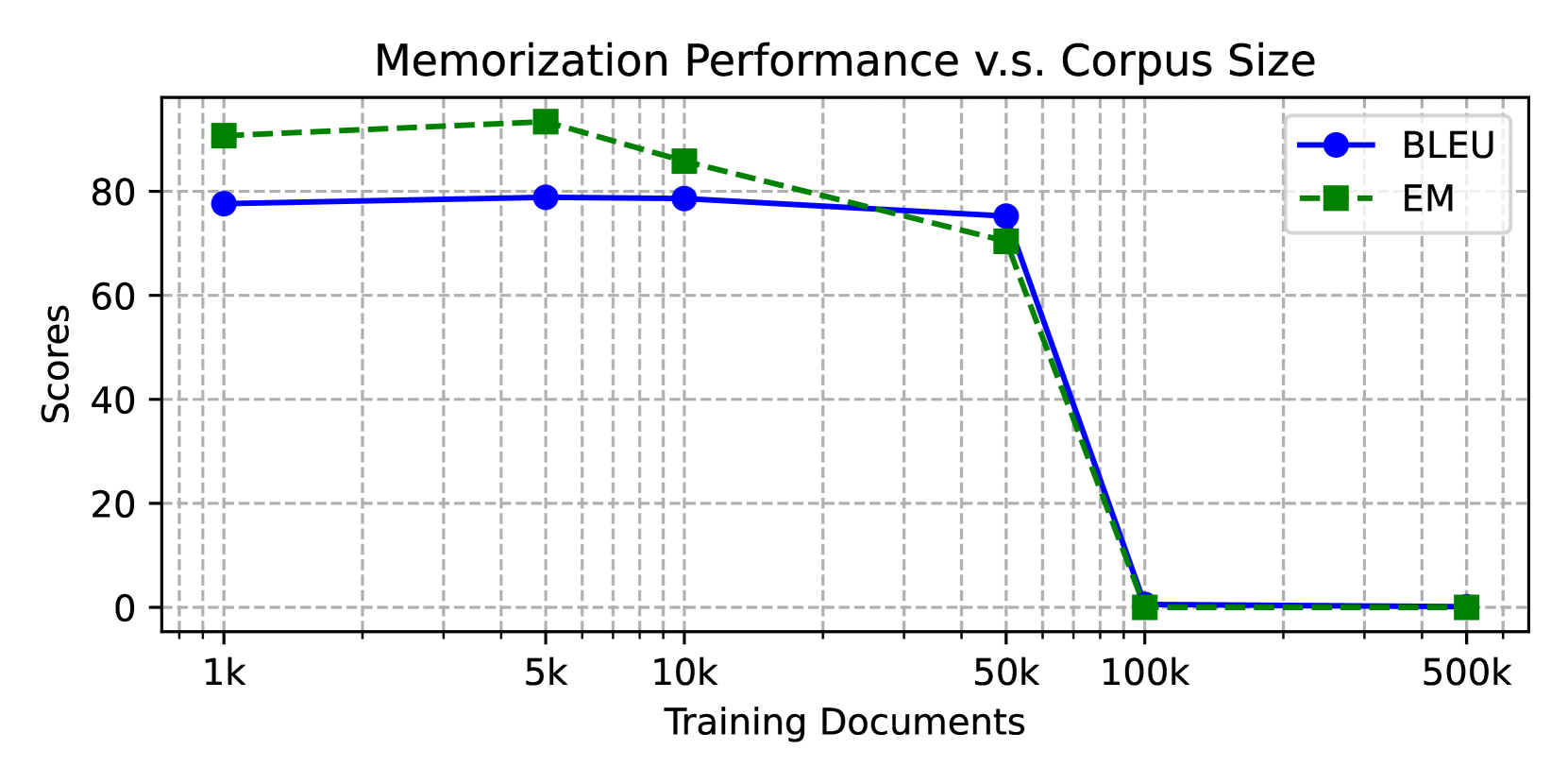
- In selective recitation, models achieve near-perfect sequential access (97.3 BLEU when context is provided) but drop to ~47 BLEU when relying on parametric memory with random access.
- In grounded QA, reciting the memorized passage before answering improves Exact Match (EM) scores from ~2.2% to ~28.6% on SQuAD-v1 passages.
- Permuting sentences during training improves random access accuracy (Exact Match) from 0.0 to 52.5 on synthetic recitation tasks.
Breakthrough Assessment
7/10
Provides a fundamental insight into the limitations of transformer memory (sequential bias). While the solution (recitation) increases compute, the diagnosis of the 'random access' failure mode is a significant contribution to understanding LM internals.