📝 Paper Summary
Large Audio Language Models (LALMs)
Audio-Text Alignment
Multimodal Adaptation
MoE-Adapter replaces dense, monolithic projection layers in Large Audio Language Models with a sparse Mixture-of-Experts architecture to resolve gradient conflicts arising from heterogeneous audio data like speech, music, and environmental sounds.
Core Problem
Current LALMs use a single, dense parameter-shared adapter to project diverse audio types (speech, music, sounds) into text space, creating optimization bottlenecks where updates for one modality interfere with another.
Why it matters:
- Audio data is intrinsically heterogeneous; speech requires semantic alignment while music/sounds require paralinguistic alignment, leading to conflicting gradient updates in shared parameters.
- Monolithic adapters struggle to simultaneously optimize for both high-level reasoning (speech content) and low-level perception (acoustic events), limiting overall model performance.
Concrete Example:
When a monolithic adapter processes both speech and background noise, the parameter updates needed to extract semantic meaning from speech often contradict those needed to characterize the noise, causing destructive interference and degraded performance in both tasks.
Key Novelty
Sparse Mixture-of-Experts (MoE) Adapter
- Replaces the standard dense projection MLP with a bank of specialized experts and a learnable router.
- Dynamically routes input audio segments to specific experts based on acoustic attributes, isolating conflicting gradients (e.g., speech vs. music) to different parameters.
- Uses an expert load-balancing loss to ensure diverse expert utilization, preventing the model from collapsing into using only a few dominant experts.
Architecture
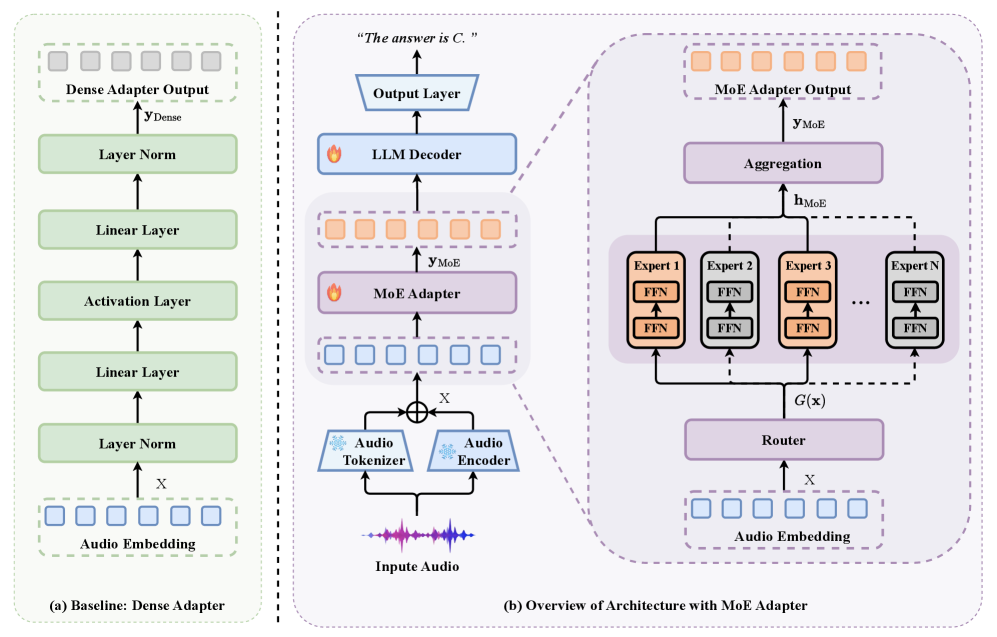
Comparison of the standard monolithic adapter vs. the proposed MoE-Adapter within the LALM architecture.
Evaluation Highlights
- +3.75% accuracy improvement on OpenBookQA (50.10% → 53.85%) and +3.16% on MMSU (35.03% → 38.19%) compared to dense baselines.
- Reduces the audio-text Modality Gap on MMSU from -17.83 to -14.67, indicating superior alignment of acoustic features with the LLM's semantic space.
- Maintains comparable inference costs (activating ~75% of baseline parameters) while outperforming dense adapters with the same total parameter budget.
Breakthrough Assessment
7/10
Offers a principled architectural solution to a known modality alignment problem with solid empirical gains. While applying MoE to adapters is an existing concept in other fields, its specific application to resolve audio heterogeneity conflicts in LALMs is well-motivated and effective.
