📝 Paper Summary
Multimodal Recommendation
Large Vision-Language Models (LVLMs) for RecSys
SDA adapts Large Vision-Language Models for recommendation by aligning cross-modal distributions via a structural teacher and disentangling gradient updates with expert-gated low-rank adapters.
Core Problem
Applying general-purpose LVLMs to recommendation fails due to representation misalignment (domain gap between pre-training and rec data) and gradient conflicts during fine-tuning (shared adapters cause interference between visual and textual updates).
Why it matters:
- Zero-shot LVLM features often underperform simpler baselines like CLIP due to domain shifts (e.g., product images vs. natural scenes), limiting their utility in real-world systems.
- Standard parameter-efficient tuning (like LoRA) shares weights across modalities, causing conflicting gradients that degrade discriminative power and cluster visually similar but functionally different items.
- Effective multimodal recommendation is crucial for handling long-tail items where interaction data is sparse but content information (images, text) is rich.
Concrete Example:
In standard fine-tuning, an item might be visually similar to another (e.g., two round objects) but functionally different (a ball vs. a fruit). Shared adapters force their embeddings together due to visual similarity, ignoring textual distinctions. SDA's disentangled experts allow the text modality to push these embeddings apart despite visual similarity.
Key Novelty
Structural and Disentangled Adaptation (SDA)
- Cross-Modal Structural Alignment (CMSA): Uses preserved intra-modal relationships (e.g., how similar two items' texts are) as a 'soft teacher' to guide the alignment of image and text embeddings, rather than just forcing them to match directly.
- Modality-Disentangled Adaptation (MoDA): Replaces shared low-rank adapters with a pool of experts and a gating mechanism. Each modality (text, image) routes through different expert combinations, preventing their gradients from cancelling out or interfering.
Architecture
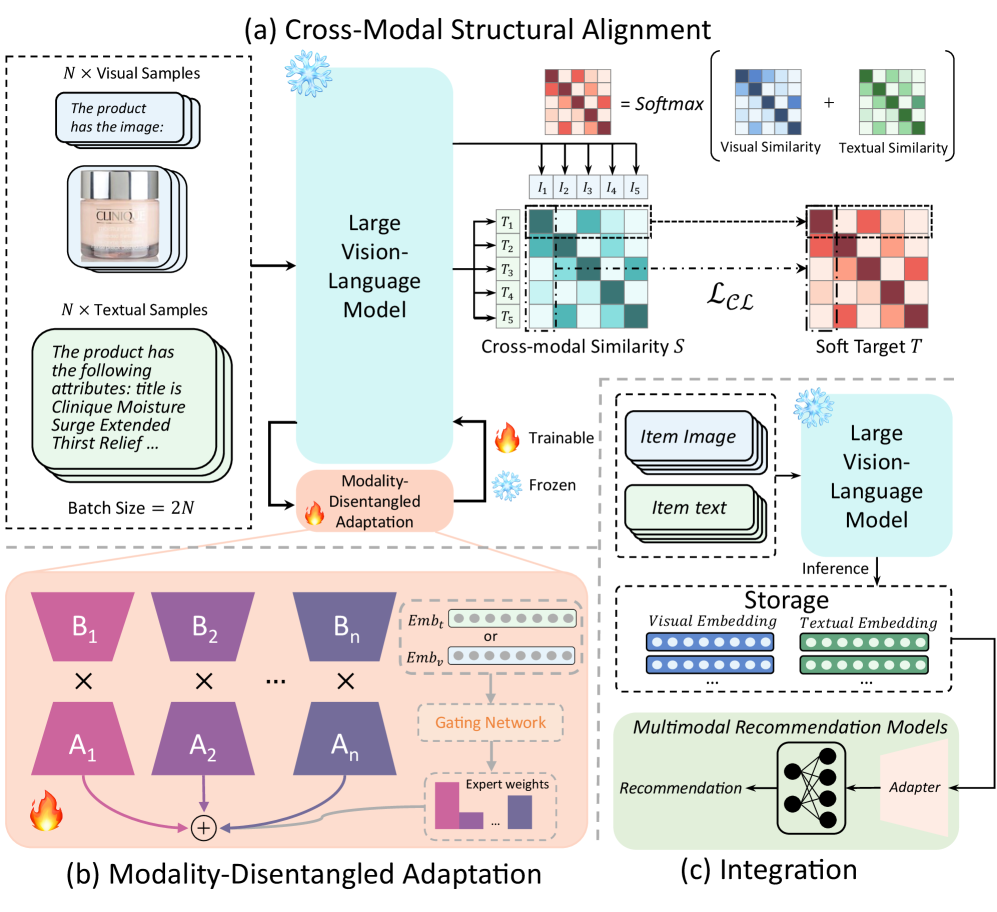
The overall SDA framework including the CMSA and MoDA modules.
Evaluation Highlights
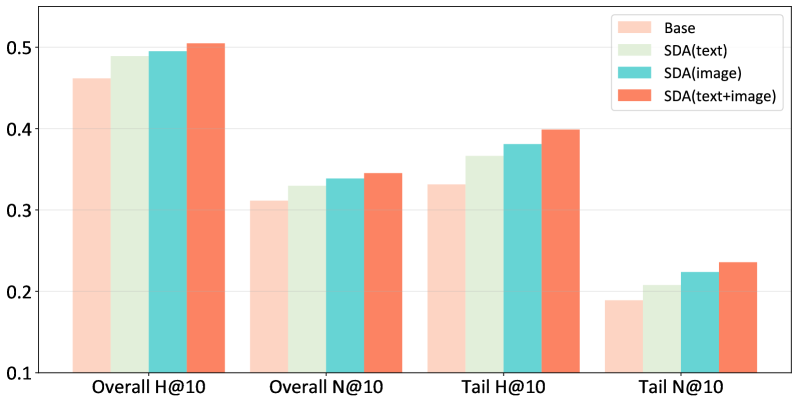
- Achieves average gains of 6.15% in Hit@10 and 8.64% in NDCG@10 across three Amazon datasets when integrated with standard recommenders.
- Delivers up to 18.70% relative gain on long-tail items (fewer than 4 interactions) compared to baselines.
- MoDA gradients show strong positive cosine similarity (0.44-0.71) between modalities, whereas standard LoRA shows negative similarity (-0.09), proving effective conflict resolution.
Breakthrough Assessment
7/10
Solid methodological improvement for adapting LVLMs to RecSys. Addresses specific, demonstrated issues (gradient conflict, misalignment) with distinct modules. Strong empirical gains, especially on long-tail items.