📝 Paper Summary
Hallucination suppression
RLHF (Reinforcement Learning from Human Feedback)
The paper demonstrates that LLMs hallucinate on unfamiliar queries by defaulting to the behavior learned from unfamiliar training examples, and proposes using 'conservative' reward models to mitigate this during RL fine-tuning.
Core Problem
When LLMs face queries about concepts outside their pre-training knowledge ('unfamiliar' inputs), they tend to hallucinate plausible-sounding but incorrect answers instead of expressing uncertainty.
Why it matters:
- Users rely on LLMs for factual information, but current models confidently fabricate details about obscure topics rather than admitting ignorance.
- Standard RLHF approaches often fail to fix this because reward models themselves hallucinate (overestimate quality) on unfamiliar inputs, reinforcing incorrect model generation.
- Understanding the specific mechanism of hallucination allows for targeted interventions in training data rather than generic scaling solutions.
Concrete Example:
If a user asks for a biography of a non-existent or obscure person, a standard model invents a fake life story. The paper shows this happens because the model's fine-tuning data included similar unfamiliar questions labeled with confident answers, teaching the model to 'guess' rather than abstain.
Key Novelty
Conservative Reward Models for RL Factuality Finetuning
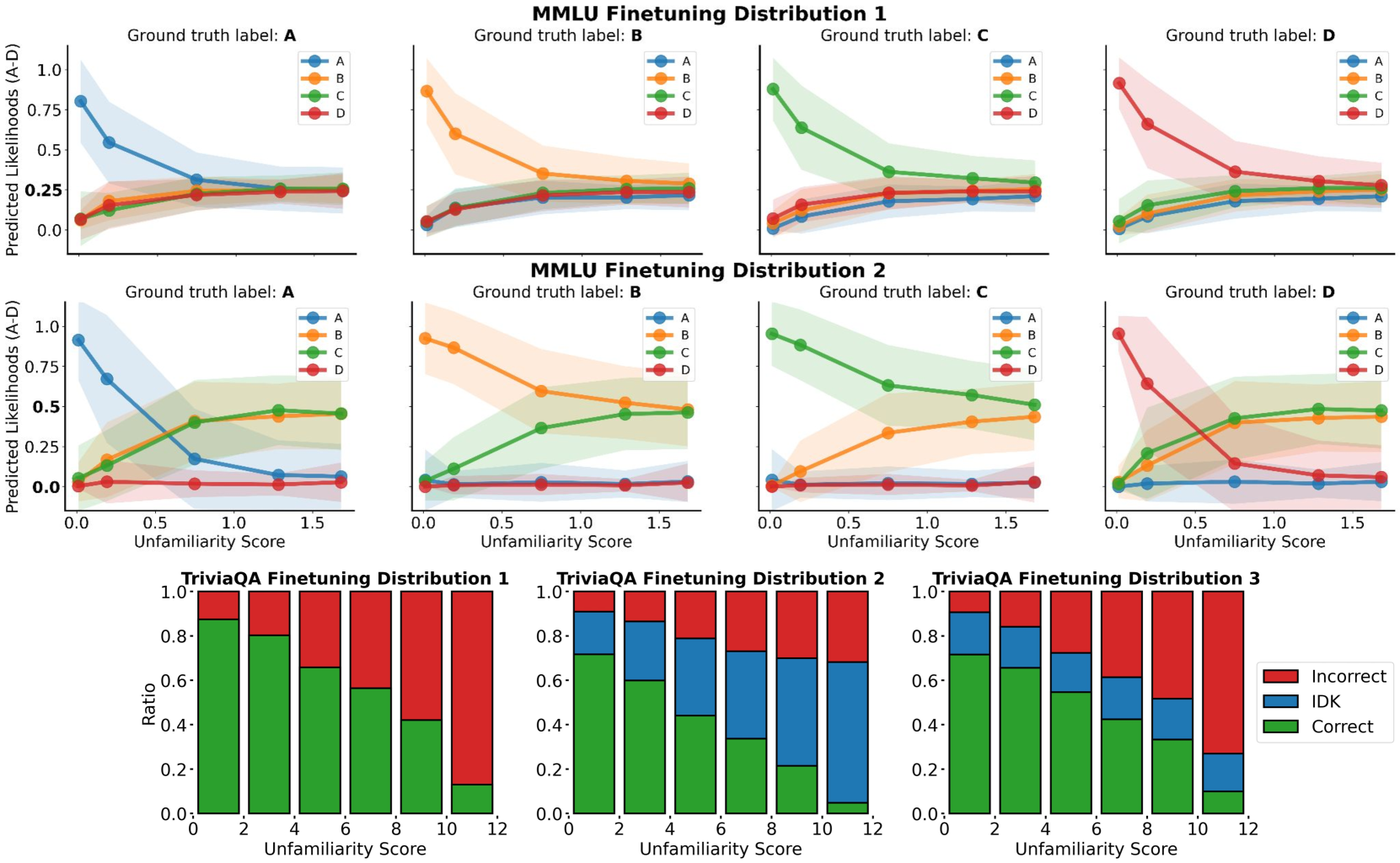
- Identifies that LLM hallucinations on unfamiliar inputs mimic the distribution of responses in the model's 'unfamiliar' fine-tuning examples (e.g., if trained to guess on unknowns, it guesses; if trained to say 'I don't know', it abstains).
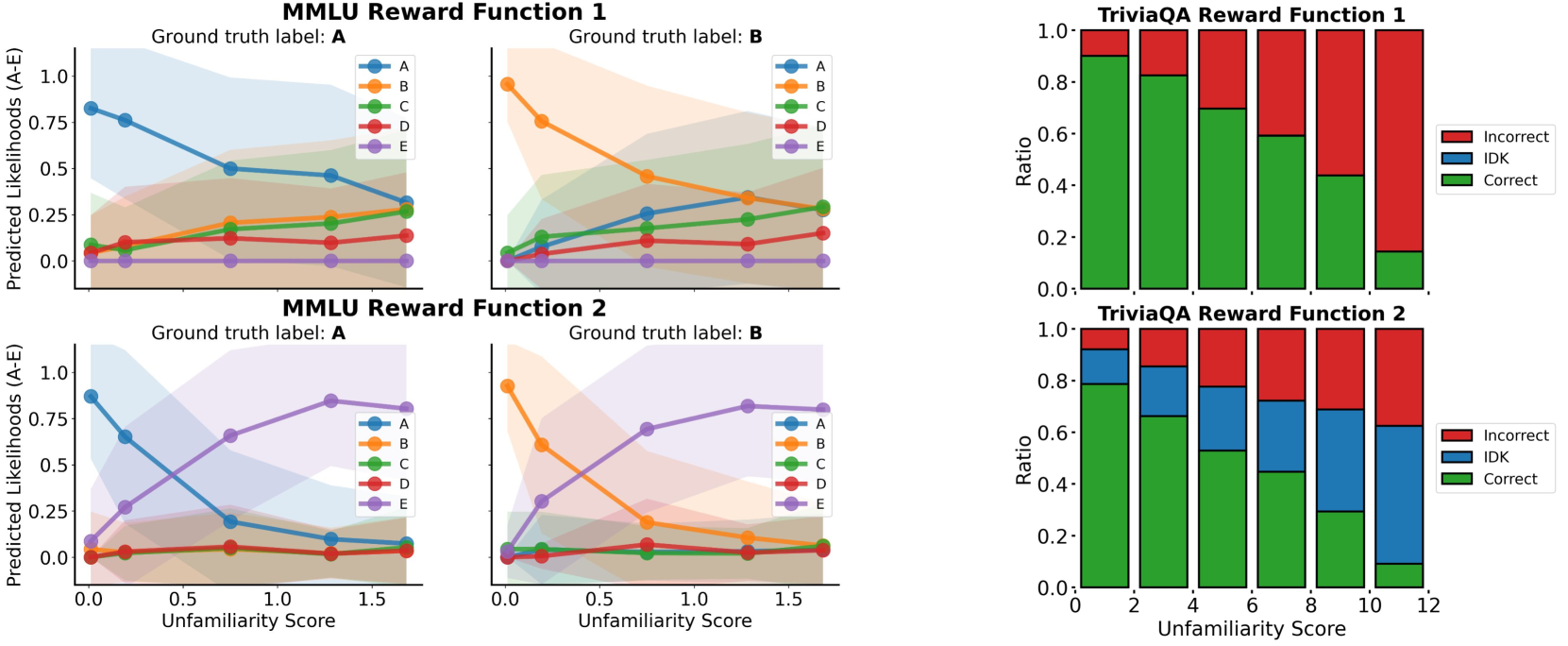
- Proposes training 'conservative' reward models that explicitly avoid overestimating rewards for unfamiliar inputs, unlike standard reward models that often confidently rate hallucinations as correct.
- Uses these conservative rewards during RL fine-tuning to teach the generator model to abstain or provide safer responses when facing knowledge gaps.
Architecture

Conceptual illustration of the 'intelligent blind guess' mechanism. It compares two SFT models: one trained on dataset A (unfamiliar examples = 'I don't know') and one on dataset B (unfamiliar examples = random hallucinations).
Evaluation Highlights
- Using conservative reward models for RL fine-tuning reduces factual error rates significantly compared to standard SFT and RL baselines on biography generation tasks.
- Controlled experiments on TriviaQA show that relabeling unfamiliar SFT examples to 'I don't know' successfully steers the model to abstain on new unfamiliar queries.
- On MMLU, modifying the fine-tuning label distribution for unfamiliar questions (e.g., 50% B, 50% C) causes the model's test-time predictions on unrelated unfamiliar questions to converge to that exact distribution.
Breakthrough Assessment
7/10
Provides a strong mechanistic explanation for hallucination patterns and a practical RL-based solution (conservative reward models). The finding that test-time hallucinations mirror fine-tuning distributions is a significant insight.