📝 Paper Summary
Knowledge-Enhanced Pre-trained Language Models (KEPLMs)
Efficient Pre-training
TRELM enhances language model pre-training by selectively injecting knowledge only into semantically important entities and updating only specific Feed-Forward Network neurons identified via dynamic knowledge routing.
Core Problem
Existing Knowledge-Enhanced PLMs indiscriminately inject knowledge into all entities (introducing noise/redundancy) and update all model parameters during pre-training (incurring high computational costs).
Why it matters:
- Indiscriminate injection introduces irrelevant or redundant knowledge, degrading model performance on downstream tasks due to noise
- Updating all parameters for knowledge integration is computationally expensive and inefficient
- Long-tail entities in text corpora are often suboptimally optimized, hindering effective knowledge acquisition
Concrete Example:
If a sentence mentions a common entity like 'the' or a very frequent entity unrelated to the sentence's core fact, standard KEPLMs still inject knowledge triples, adding noise. Furthermore, they update the entire Transformer to learn this, wasting compute.
Key Novelty
Robust and Efficient Knowledge Injection with Dynamic Routing
- Identifies 'important entities' using a semantic importance score to filter out noisy or redundant knowledge injection targets
- Maintains a 'Knowledge-augmented Memory Bank' (KMB) that acts as a cheat sheet, storing global and local entity representations to support long-tail entities
- Uses 'Dynamic Knowledge Routing' to identify specific neurons in FFN layers responsible for factual knowledge and selectively updates only those parameters during pre-training
Architecture
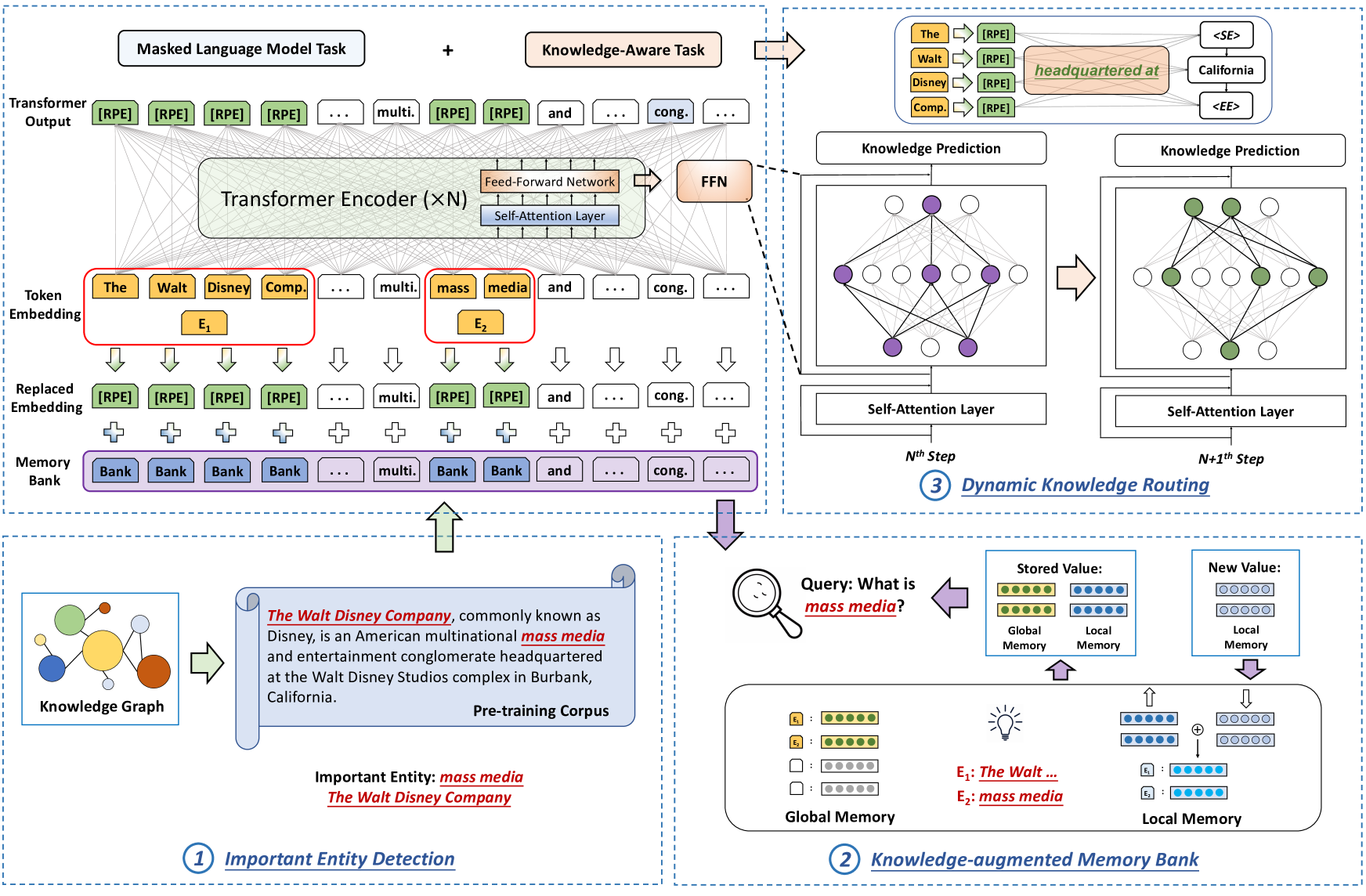
The overall framework of TRELM, illustrating the interaction between input text, the Knowledge-augmented Memory Bank (KMB), and the Transformer encoder with Dynamic Knowledge Routing.
Evaluation Highlights
- Reduces pre-training time by over 50% compared to standard KEPLM approaches while maintaining or improving performance
- Outperforms strong baselines (like DKPLM and ERNIE) on the LAMA knowledge probing benchmark
- Achieves superior performance on relation extraction and entity typing tasks compared to previous state-of-the-art KEPLMs
Breakthrough Assessment
7/10
Significant efficiency gains (50% faster) combined with robustness improvements make this a practical advancement for KEPLMs, though the core architecture remains Transformer-based.