📝 Paper Summary
Modularized RAG pipeline
Factuality and hallucination in LLMs
The paper introduces Corpus-Invariant Tuning (CIT), a training loss that prevents the reader from over-memorizing retrieved documents, thereby forcing reliance on retrieval and improving generalization to new or updated corpora.
Core Problem
Retrieval-augmented models often over-memorize training documents into their parameters instead of relying on the retriever, causing failures when the external corpus is updated or the domain changes.
Why it matters:
- Real-world knowledge evolves continually (e.g., Wikipedia updates), but models trained on old data struggle to adapt even when provided with new retrieved documents due to parametric bias.
- Adapting to new domains (e.g., biomedical) usually requires extensive retraining if the model has hard-coded general-domain knowledge.
- Prior OpenQA methods focus on in-domain accuracy but neglect the 'reader's' reliance on retrieved context versus internal memory.
Concrete Example:
If a model memorizes 'Boris Johnson' as the UK PM from an old corpus, it may ignore a retrieved document stating 'Rishi Sunak is PM' from a new corpus. The paper shows a drop from 62.2 (fresh training) to 56.9 (transfer) when moving from Wiki-2017 to Wiki-2018.
Key Novelty
Corpus-Invariant Tuning (CIT)
- Introduces a regularization loss that prevents the reader's likelihood of generating the retrieved document text from increasing during training.
- Forces the reader to act as a reasoning module over inputs rather than a memory module, shifting the burden of knowledge storage back to the retriever.
Architecture
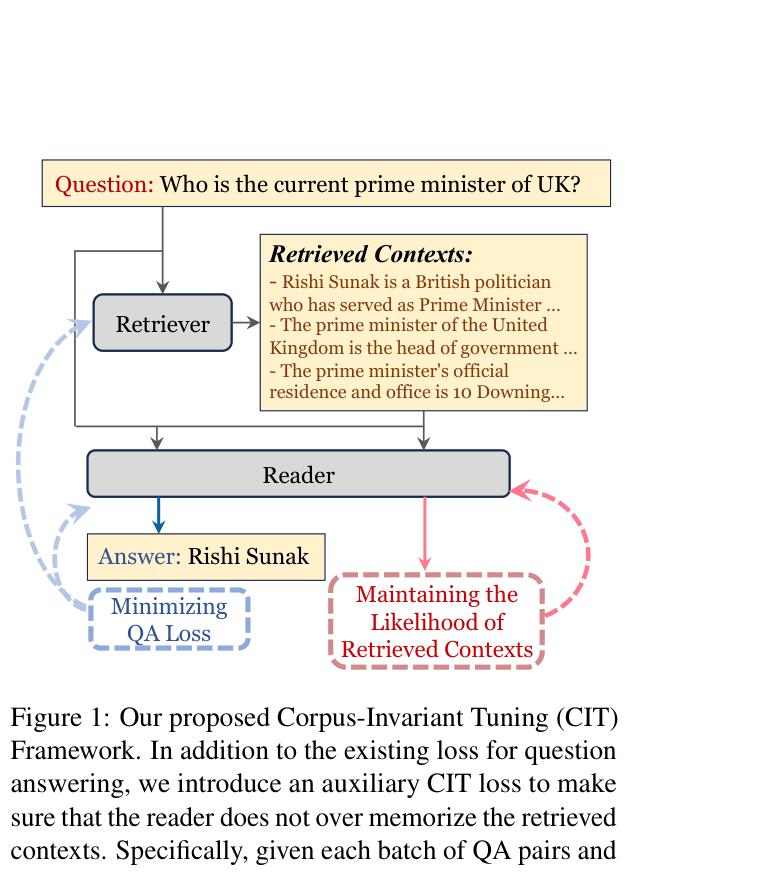
Illustration of the Corpus-Invariant Tuning (CIT) strategy.
Evaluation Highlights
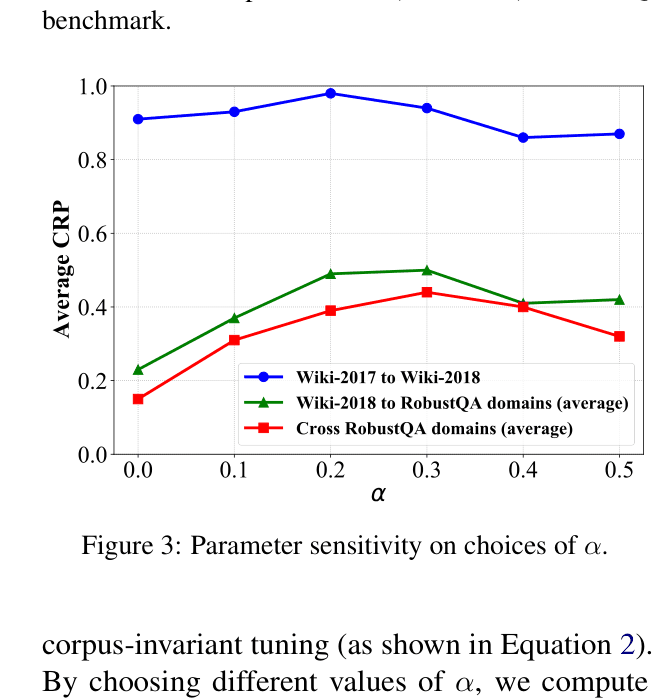
- +2.1% Exact Match (EM) improvement on Natural Questions when transferring from Wiki-2017 to Wiki-2018 compared to the Atlas-XL baseline.
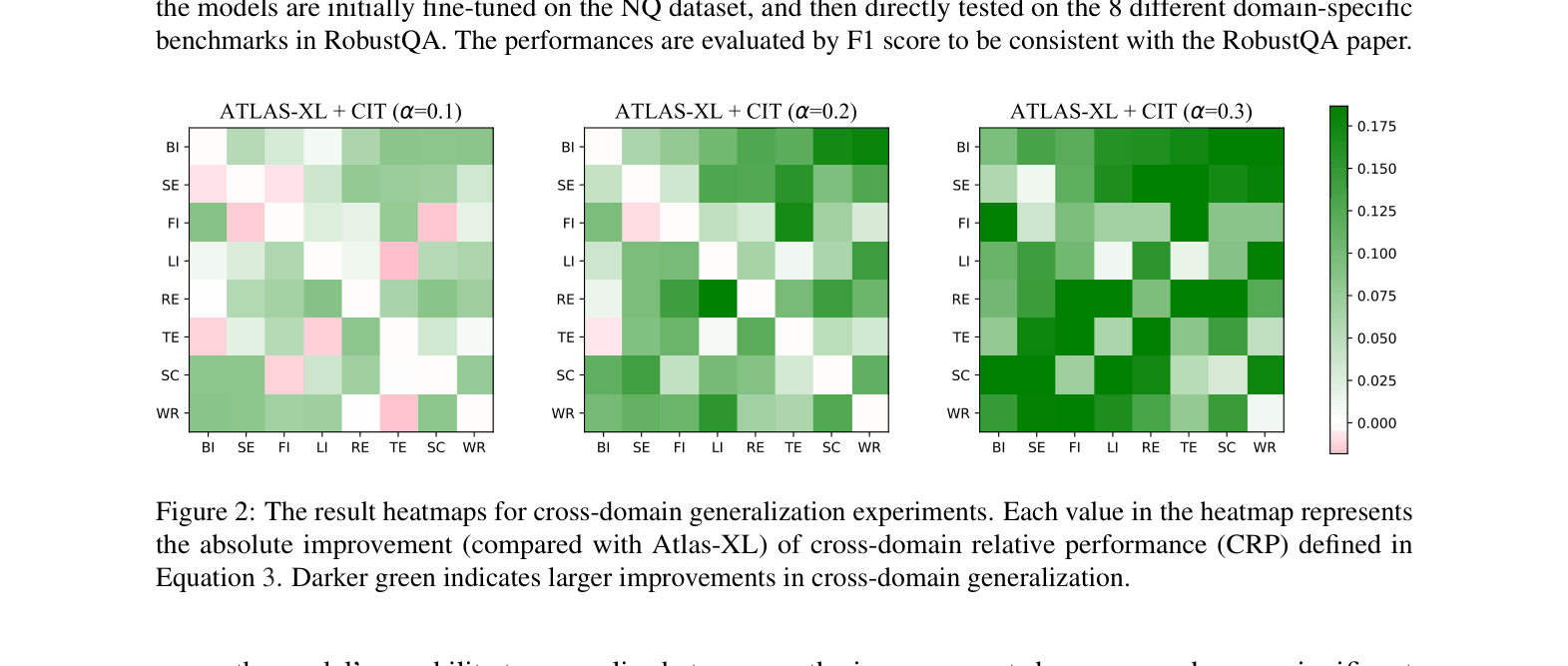
- Achieves state-of-the-art F1 scores among 3B-sized models on the RobustQA benchmark (averaging across 8 domains) by mitigating over-memorization.
- Significant gains in 'Life' domain generalization (where overlap with Wikipedia is high), validating that reducing memorization helps when knowledge conflicts or updates occur.
Breakthrough Assessment
7/10
Addresses a critical but often overlooked issue in RAG (parametric vs. non-parametric conflict). The solution is simple and effective, though primarily demonstrated on standard benchmarks.