📊 Experiments & Results
Evaluation Setup
Open-domain QA on entity-centric and general datasets.
Benchmarks:
- PopQA (Entity-centric QA (long-tail entities))
- TriviaQA (General open-domain QA (multi-hop/non-entity))
Metrics:
- Accuracy (ACC)
- Percentage of Retrieval (POR)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| PopQA | ACC | 29.21 | 33.08 | +3.87 |
| PopQA | POR | 95.15 | 57.89 | -37.26 |
| TriviaQA | ACC | 62.33 | 62.67 | +0.34 |
| TriviaQA | POR | 98.56 | 92.11 | -6.45 |
| PopQA | ACC | 38.54 | 40.98 | +2.44 |
Experiment Figures
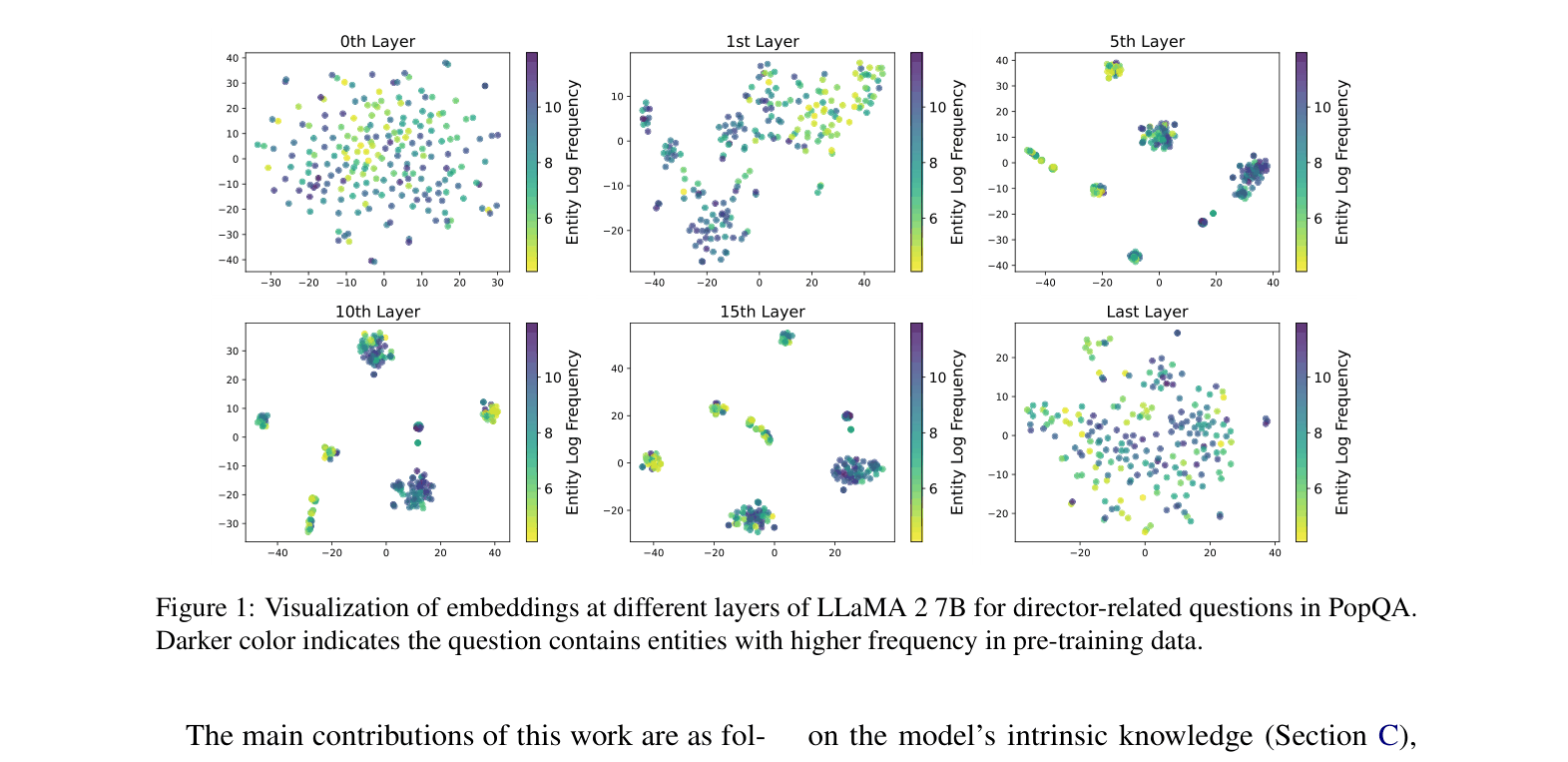
Visualization of LLaMA 2 7B embeddings at different layers for director-related questions, colored by entity frequency.
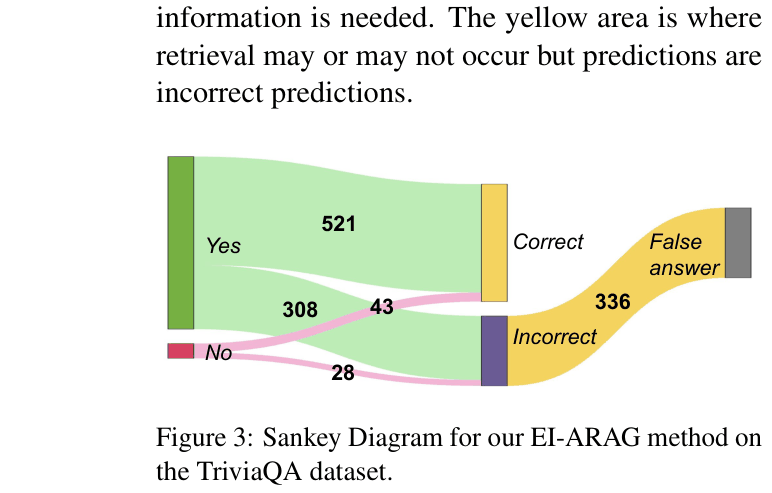
Sankey Diagram for EI-ARAG decisions on TriviaQA.
Main Takeaways
- EI-ARAG achieves superior or comparable accuracy to prompting methods while significantly reducing retrieval volume (POR).
- Latency analysis confirms embedding extraction is ~9x faster (0.0443s) than prompting for a decision (0.3885s).
- Embeddings from the 1st contextualized layer are sufficient for determining knowledge boundaries; deeper layers do not yield significant gains.