📝 Paper Summary
Modularized RAG pipeline
Adaptive-RAG uses a small classifier to predict query complexity and dynamically selects the most efficient strategy—no retrieval, single-step retrieval, or multi-step retrieval—for each query.
Core Problem
Existing RAG approaches use a 'one-size-fits-all' strategy: simple questions waste compute on unnecessary retrieval steps, while complex multi-hop questions fail with simple retrieval methods.
Why it matters:
- Real-world user queries vary widely in complexity, from simple fact lookups to complex reasoning chains
- Applying multi-step retrieval to every query creates massive computational overhead
- Applying single-step or no retrieval to complex queries results in incorrect answers
Concrete Example:
For the simple query 'Paris is the capital of what?', a multi-step RAG system wastes resources searching documents. Conversely, for 'When did the people who captured Malakoff come to the region where Philipsburg is located?', a single-step RAG fails because it cannot connect the four necessary reasoning steps.
Key Novelty
Complexity-Based Adaptive RAG Strategy Selection
- Classify incoming queries into three complexity levels (A: answerable by LLM, B: single-step retrieval, C: multi-step retrieval) using a smaller language model
- Dynamically route the query to the most appropriate solver based on the predicted complexity, avoiding unnecessary computation for simple queries and ensuring sufficiency for complex ones
- Automatically generate training labels for the classifier using model predictions and dataset inductive biases (e.g., multi-hop datasets imply complexity C)
Architecture

Conceptual diagram comparing the proposed Adaptive-RAG against 'Simple' (A) and 'Complex' (B) approaches. It shows the Classifier directing queries to one of three paths.
Evaluation Highlights
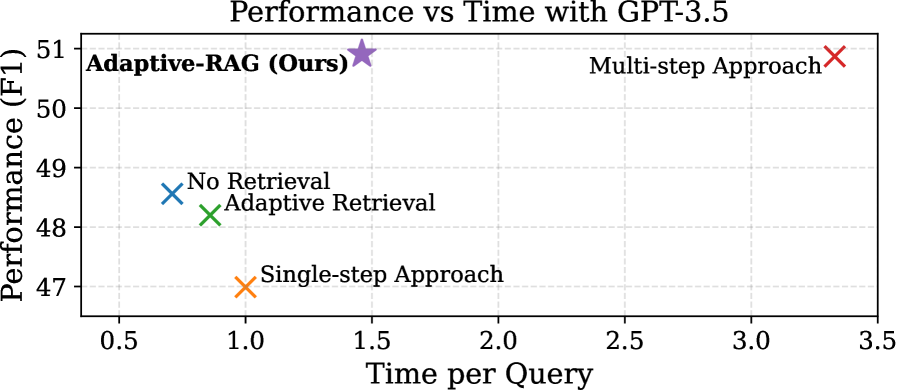
- Achieves higher accuracy than adaptive baselines like 'Adaptive Retrieval' (+5.5% on Multi-hop datasets) while maintaining efficiency
- Reduces computational cost significantly compared to always-on multi-step methods (e.g., 40-50% faster inference than Iter-Retgen)
- Outperforms single-step RAG by ~12-14% on complex multi-hop benchmarks like HotpotQA and 2WikiMultihopQA
Breakthrough Assessment
7/10
A practical, effective approach to the efficiency-accuracy trade-off in RAG. While the core idea of adaptive retrieval isn't new, the specific implementation of a classifier trained on 'silver' labels from model outcomes is a solid engineering contribution.