📝 Paper Summary
Tabular Representation Learning
LLM adaptation for structured data
The paper adapts Large Language Models for data science tasks by pretraining them on a massive corpus of 13 billion tabular examples using a mask-then-predict objective and instruction tuning.
Core Problem
LLMs struggle with structured tabular data tasks (classification, regression, missing values) because their training data is primarily natural language, lacking the specific structural and numerical intricacies of tables.
Why it matters:
- Tables are ubiquitous in finance and logistics, yet capturing their multidimensional interactions remains challenging for standard NLP models
- Traditional feature engineering is manual and brittle, often failing to generalize across diverse tasks
- Existing tabular LLM approaches focus on text generation (TableQA, Text-to-SQL) rather than core predictive data science tasks like regression
Concrete Example:
When handling a table with missing values, standard LLMs often treat it as a generic text completion task, failing to leverage column relationships. The paper's approach masks specific cells (e.g., '<missing_value_0>') and forces the model to predict them based on the structural context of the row and column.
Key Novelty
Table-Specific Continued Pretraining (Mask-Then-Predict + Instruction Tuning)
- Curates a massive dataset of 13 billion tabular examples from Kaggle and UCI to expose the model to diverse structural patterns
- Employs a 'Mask-Then-Predict' objective where random table cells are masked and the model must reconstruct them, forcing it to learn row/column dependencies
- Integrates a unified serialization format (Markdown) with task-specific instructions to treat classification and regression as text generation tasks
Architecture
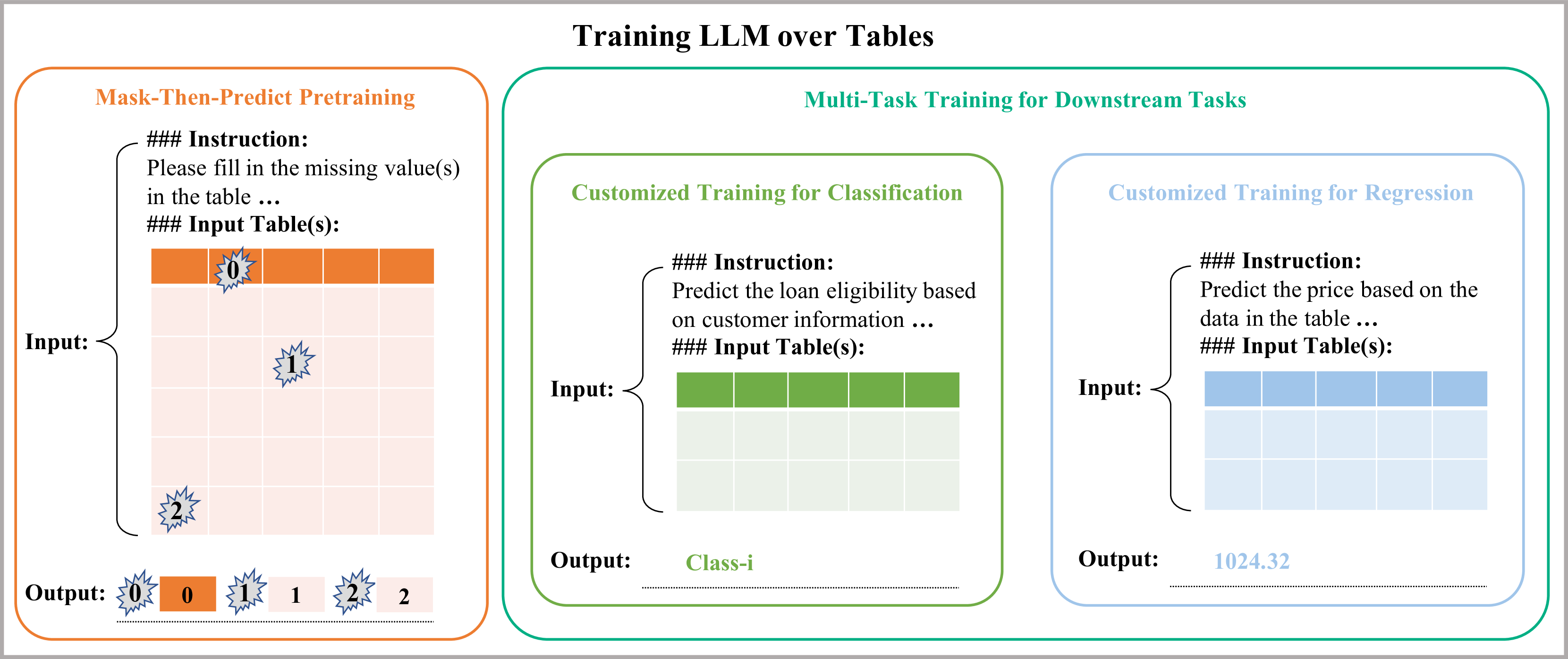
The bifurcated training regimen: Pretraining (Left) and Multi-task Training (Right).
Evaluation Highlights
- Achieves an average improvement of 8.9% in classification tasks and 10.7% in regression tasks compared to Llama-2
- Outperforms GPT-4 by 27% on missing value prediction tasks
- Shows a significant 28.8% improvement in extreme-few-shot (4-shot) predictions compared to baselines
Breakthrough Assessment
8/10
Strong empirical results on core data science tasks (regression/classification) where LLMs typically struggle. The scale of the pretraining corpus (13B examples) is a significant contribution.