📝 Paper Summary
Retrieval Benchmarking
Semi-structured Data
STaRK is a large-scale benchmark for evaluating retrieval systems on semi-structured knowledge bases, using a novel pipeline to synthesize natural language queries that require both textual understanding and relational reasoning.
Core Problem
Existing retrieval benchmarks focus either on purely textual queries (unstructured) or structured SQL/Knowledge Graph queries, failing to address complex real-world needs that require blending both unstructured text and structured relations from private knowledge bases.
Why it matters:
- Real-world queries (e.g., e-commerce, medicine) often combine free-form constraints (text) with relational constraints (graphs), which current systems struggle to handle simultaneously
- Prior benchmarks do not adequately test the capability of LLMs to perform retrieval on semi-structured knowledge bases (SKBs) that mix documents and graphs
- There is a lack of diverse, large-scale datasets that simulate realistic user queries on private SKBs with ground truth answers
Concrete Example:
A user asks: 'Find a push-along tricycle from Radio Flyer that’s fun and safe.' A purely textual retriever might find tricycles but miss the 'Radio Flyer' brand constraint. A structured query engine can't interpret 'fun and safe'. The system must verify the relational link (Brand=Radio Flyer) AND the textual description (fun/safe) simultaneously.
Key Novelty
Synthesizing Semi-structured Retrieval Queries
- Uses a novel pipeline that 'entangles' relational and textual information during synthesis: it samples relational templates (e.g., 'X belongs to Brand Y') and extracts textual properties (e.g., 'fun and safe') from a gold entity's document
- Disentangles these aspects during verification: uses LLMs to strictly filter candidate entities that match the relational constraints against the textual properties to ensure precise ground truth
- Incorporates diverse domains (Amazon product search, academic paper search, precision medicine) with role-playing LLMs (e.g., patient vs. doctor) to vary query language and complexity
Architecture
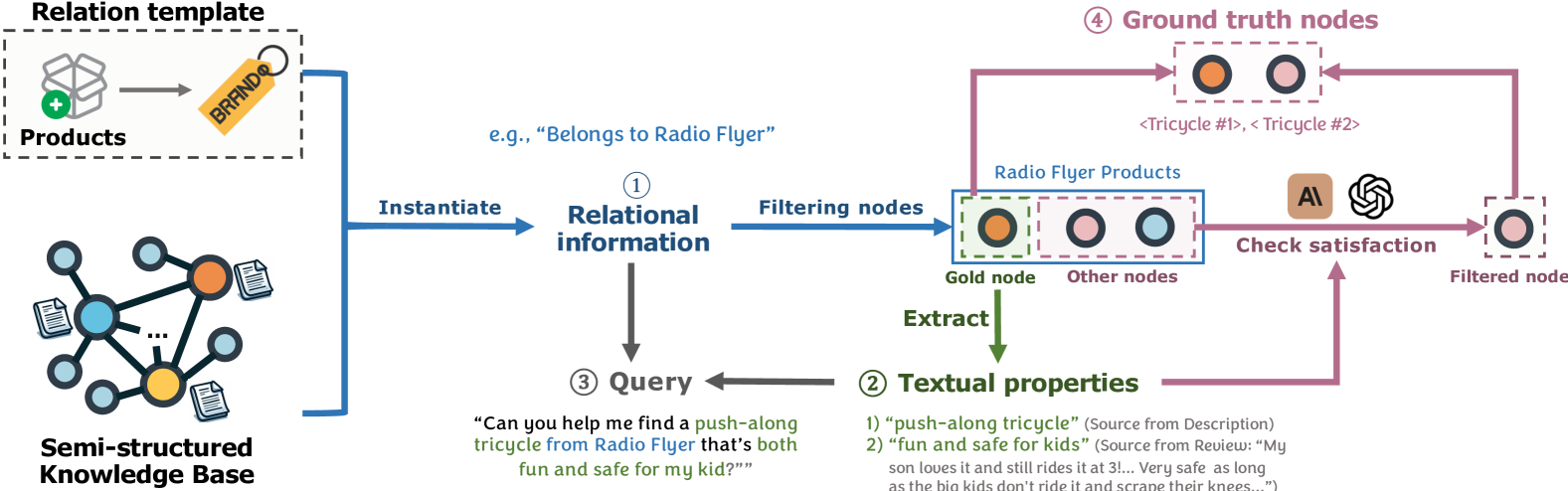
The data synthesis pipeline for constructing the benchmark.
Evaluation Highlights
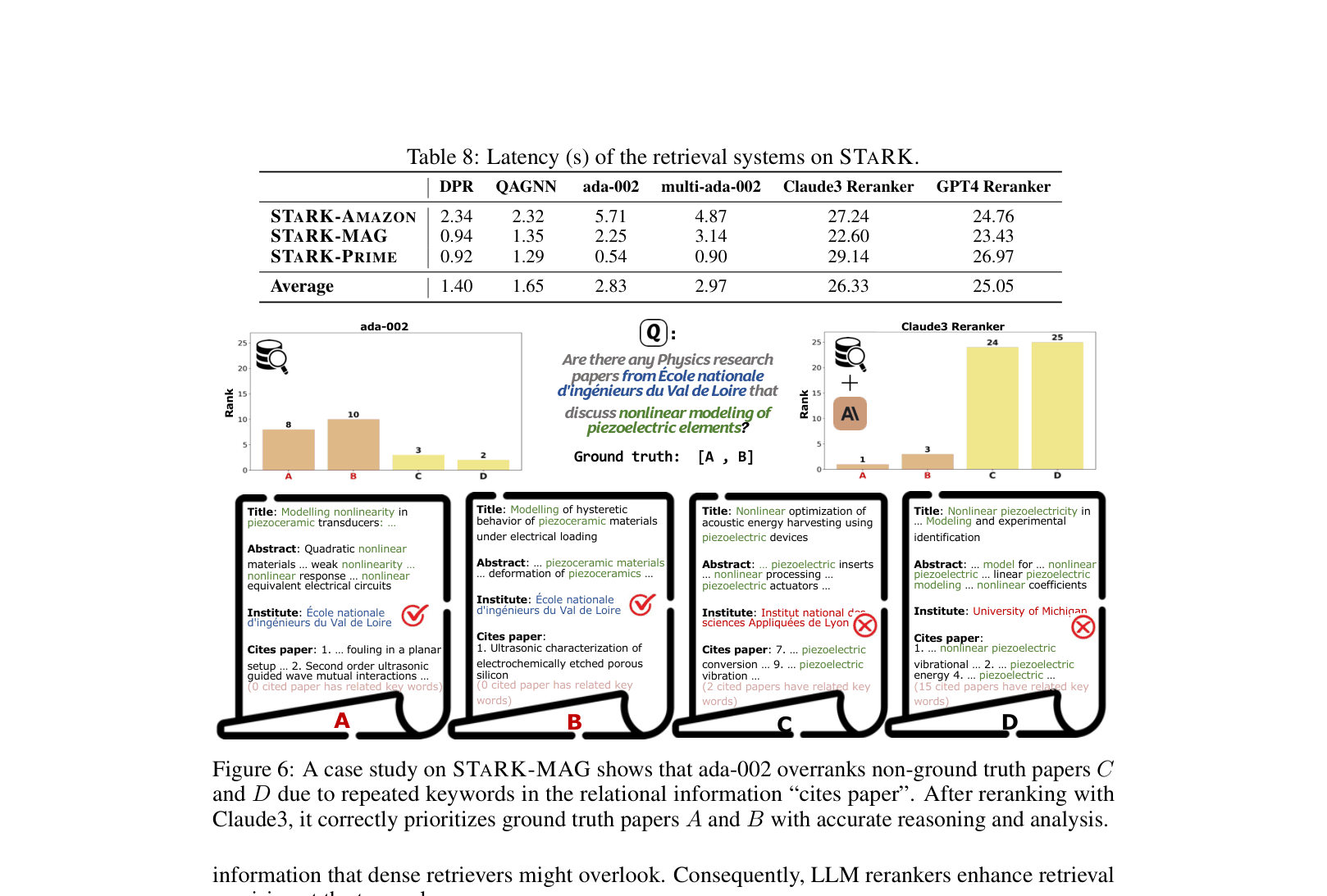
- Sparse retrieval (BM25) outperforms dense retrievers (DPR, ANCE) on STaRK-Amazon (Hit@1: 29.5% vs 17.0%), showing current dense models struggle with specific entities in SKBs
- LLM Rerankers (GPT-4) significantly improve performance but remain imperfect, achieving only ~18% Hit@1 on STaRK-Prime, highlighting the difficulty of biomedical relational reasoning
- Recall@20 for GPT-4 reranker is below 60% across all datasets (e.g., 34% on STaRK-Prime), indicating that even powerful models miss a large portion of relevant answers
Breakthrough Assessment
8/10
Addresses a critical gap in retrieval benchmarking by combining text and graph modalities. The synthesis pipeline is robust, and the results reveal significant failures in current SOTA retrieval systems.