📝 Paper Summary
Vision-Language Models (LVLMs)
Model Evaluation
The authors identify severe data leakage and visual independence issues in existing LVLM benchmarks and propose MMStar, a manually curated benchmark requiring true visual understanding.
Core Problem
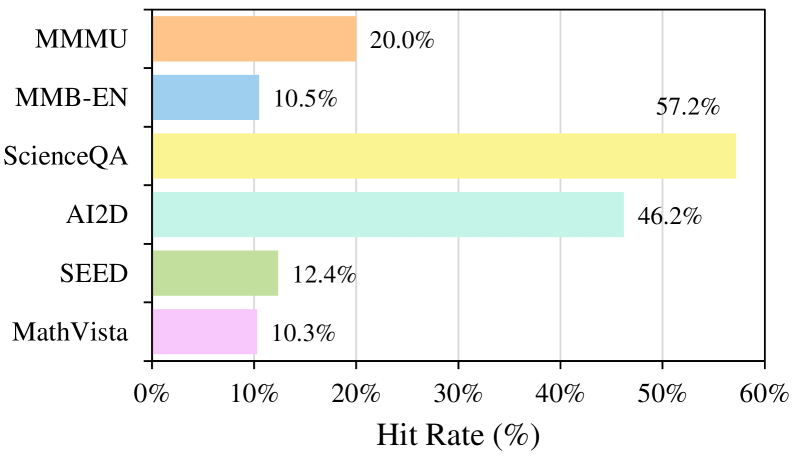
Existing LVLM benchmarks contain many samples where visual content is unnecessary (answerable by text alone) and suffer from unintentional data leakage where models memorize answers during training.
Why it matters:
- Evaluation samples that don't require vision degrade LVLM assessment into merely testing the text-only LLM backbone
- Unintentional leakage leads to inflated scores and unfair comparisons, misguiding research on actual multi-modal architectural gains
- High scores on flawed benchmarks create a false sense of progress while models may lack genuine multi-modal reasoning capabilities
Concrete Example:
GeminiPro achieves 42.9% on the MMMU benchmark without seeing any images, and Sphinx-X-MoE gets 43.6% on MMMU without images, surpassing its own LLM backbone by 17.9% due to memorization.
Key Novelty
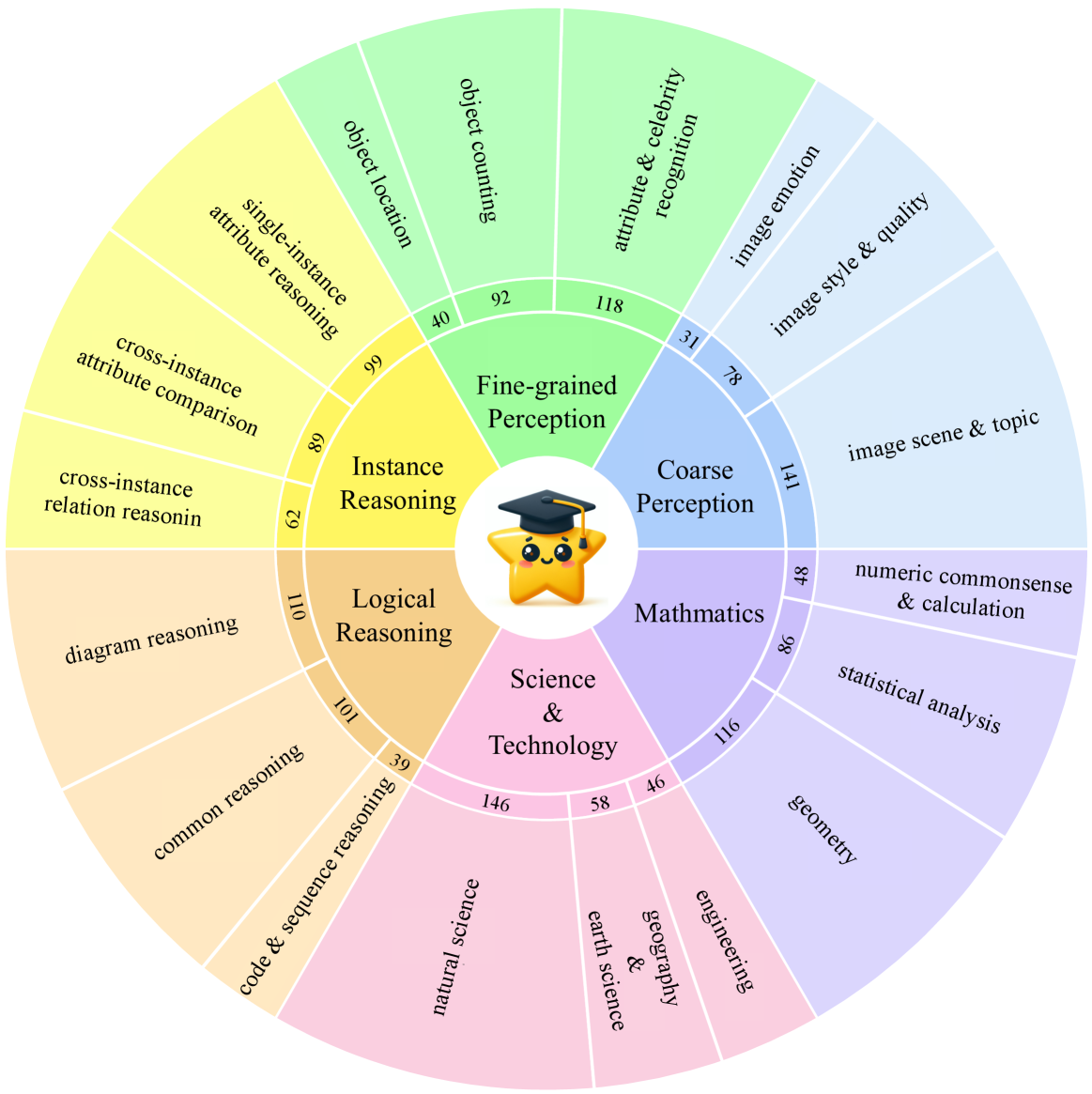
MMStar Benchmark & Metric Suite
- Developed an automated pipeline using 8 LLMs to filter out samples answerable without images, followed by strict human curation to ensure visual dependency
- Introduced 'Multi-modal Gain' (MG) and 'Multi-modal Leakage' (ML) metrics to quantify how much performance comes from actual visual understanding versus training data memorization
Architecture
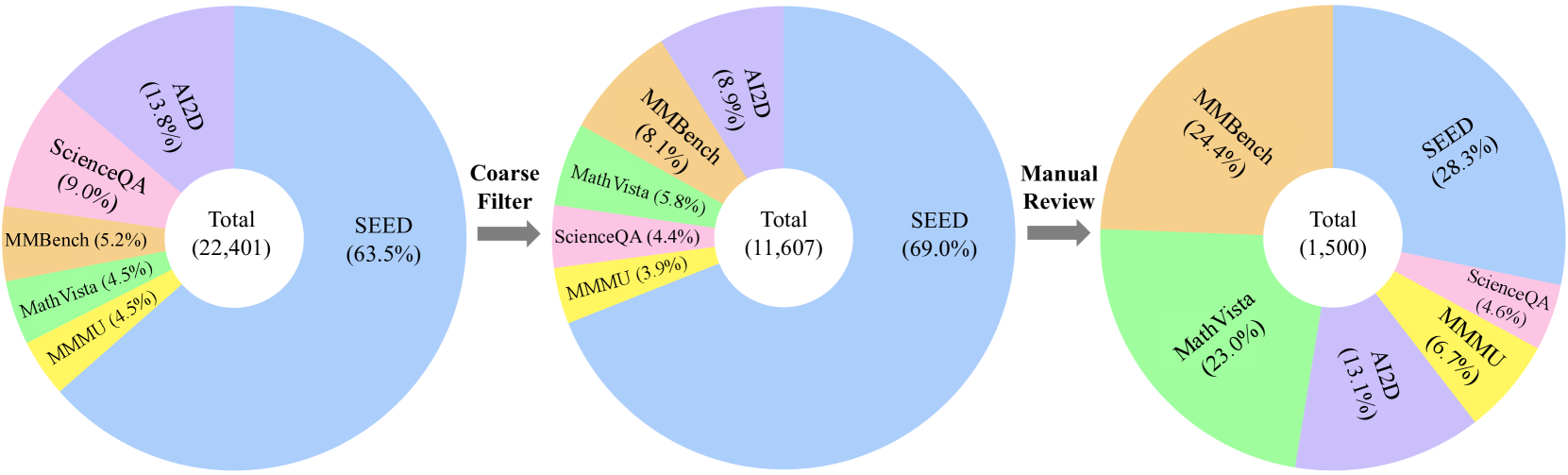
The data curation pipeline for constructing MMStar.
Evaluation Highlights
- GeminiPro outperforms random choice by over 24% on average across six existing benchmarks without accessing any visual input
- GPT-4V (high-res) achieves the highest accuracy of 57.1% on MMStar, confirming it as the state-of-the-art vision-language model
- On the MMMU benchmark, Sphinx-X-MoE achieves 43.6% accuracy without images, indicating severe data leakage in its training
Breakthrough Assessment
9/10
Crucial reality check for the field. Exposes fundamental flaws in current SOTA benchmarks and provides a cleaned dataset plus metrics to measure leakage, likely shifting future evaluation standards.