📊 Experiments & Results
Evaluation Setup
Open-domain QA across general and domain-specific benchmarks
Benchmarks:
- 2WikiMultihopQA (Multi-hop QA)
- HotpotQA (Multi-hop QA)
- StrategyQA (Commonsense QA)
- IIRC (Reading Comprehension)
- BioASQ (Biomedical QA)
- PubMedQA (Biomedical QA)
Metrics:
- Exact Match (EM)
- F1 Score
- Accuracy (for BioASQ/PubMedQA)
- Retrieval Frequency
- Delayed Retrieval Ratio
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Main performance comparison across general domain datasets using LLaMA3-8B backbone. | ||||
| 2WikiMultihopQA | F1 | 39.4 | 43.3 | +3.9 |
| HotpotQA | F1 | 45.0 | 47.7 | +2.7 |
| Efficiency analysis showing retrieval frequency reduction. | ||||
| Average across datasets | Number of Retrievals | 2.83 | 2.33 | -0.50 |
| Analysis of delayed retrieval on 2WikiMultihopQA (Manual Eval). | ||||
| 2WikiMultihopQA | Delayed Retrieval Ratio | 0.33 | 0.10 | -0.23 |
Experiment Figures

Comparison of retrieval timing between DRAGIN (confidence-based) and ETC (trend-based) on a specific example.
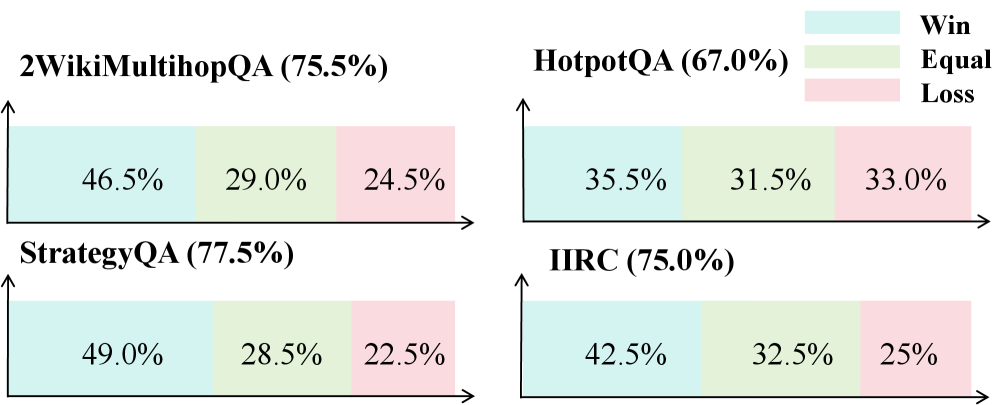
Win rate evaluation using GPT-4o comparing ETC against baselines.
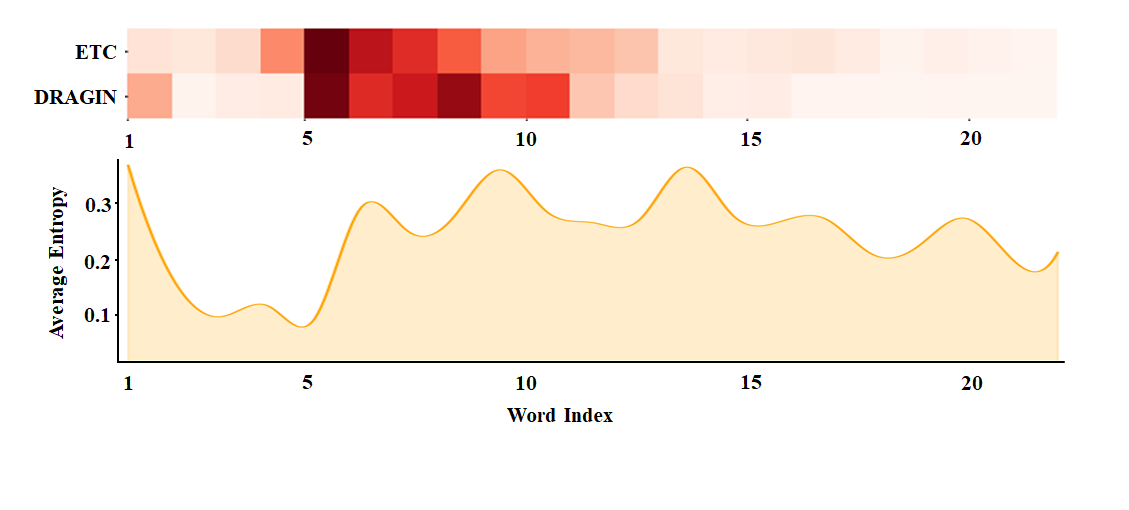
Heatmap of retrieval positions and entropy values.
Main Takeaways
- ETC consistently outperforms strong baselines (FLARE, DRAGIN) across 6 benchmarks and 3 model families (LLaMA2, LLaMA3, Vicuna).
- Using second-order entropy differences (acceleration) provides a more timely trigger than absolute thresholds or first-order differences.
- Dynamic smoothing is critical; removing it increases redundant retrievals.
- ETC reduces the 'delayed retrieval' problem where models retrieve only after generating incorrect tokens.