📝 Paper Summary
In-Context Learning (ICL)
Language Model Scaling Laws
Small Language Models (SLMs)
Data Curation for Pre-training
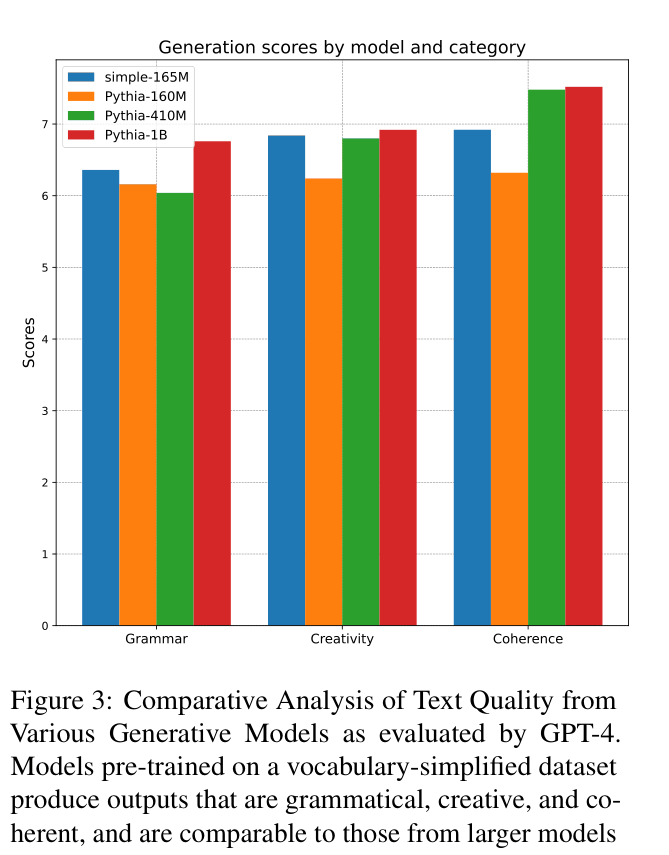
Pre-training small language models on vocabulary-restricted, simplified data unlocks zero-shot learning capabilities comparable to much larger models trained on standard data, challenging the idea that emergence requires massive scale.
Core Problem
Emergent abilities like in-context learning are typically observed only in massive models (billions of parameters), making them inaccessible to smaller models and computationally expensive to study.
Why it matters:
- Current scaling laws suggest only massive compute/data allow complex reasoning, discouraging research into efficient small models
- Understanding whether 'emergence' is an inherent property of scale or an artifact of data complexity fundamentally changes how we design and train efficient AI systems
Concrete Example:
A standard 165M parameter model trained on unrestricted web text typically fails at zero-shot tasks (performing near random chance) because the linguistic distribution is too complex for its capacity, whereas the paper shows the same sized model succeeds when the language is simplified.
Key Novelty
Language Simplification for Pre-training (Downscaling the Problem)
- Instead of scaling up the model to master complex language, the paper scales down the language complexity to match smaller models.
- Filters massive pre-training corpora (SlimPajama) using a child-directed speech vocabulary (~21k words) to create a linguistically simpler but structurally natural dataset.
- Demonstrates that when the 'problem difficulty' (language complexity) matches model capacity, emergent behaviors like zero-shot learning appear in models as small as 100M parameters.
Architecture
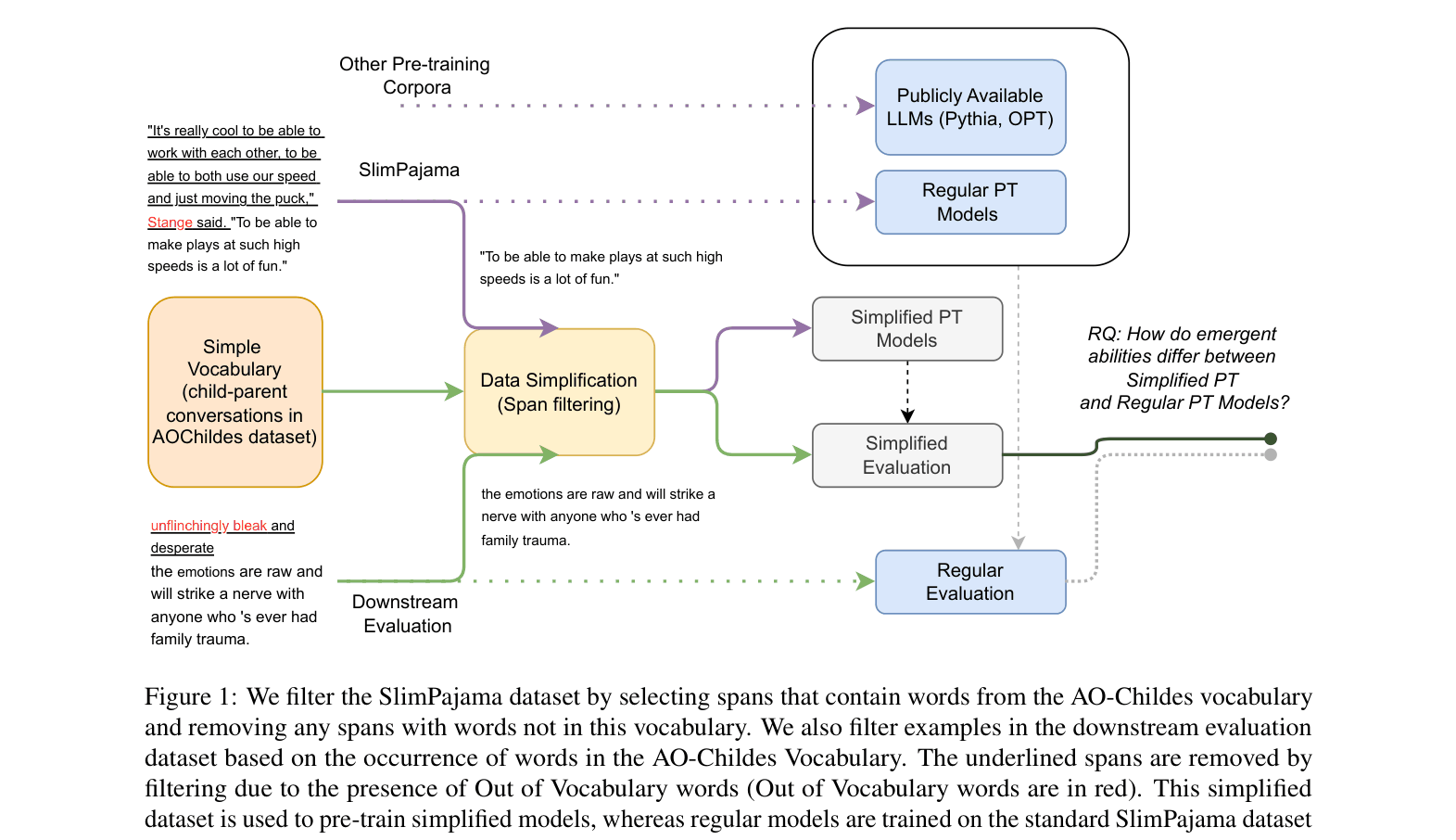
The data processing pipeline for creating the simplified pre-training corpus from the SlimPajama dataset.
Evaluation Highlights
- Simple 165M model outperforms the 6x larger Pythia 1B on simplified zero-shot tasks (0.64 vs 0.62 average score).
- Simple 165M model matches or beats OPT 350M performance on standard benchmarks despite the distribution shift.
- Establishes a power law relationship for small models on simplified data between evaluation loss and compute/data/size ($R^2 > 0.75$).
Breakthrough Assessment
7/10
Strong empirical evidence challenging the 'scale is all you need' narrative for emergence. While the utility of simplified-language models is restricted, the finding that emergence is relative to data complexity is theoretically significant.