📝 Paper Summary
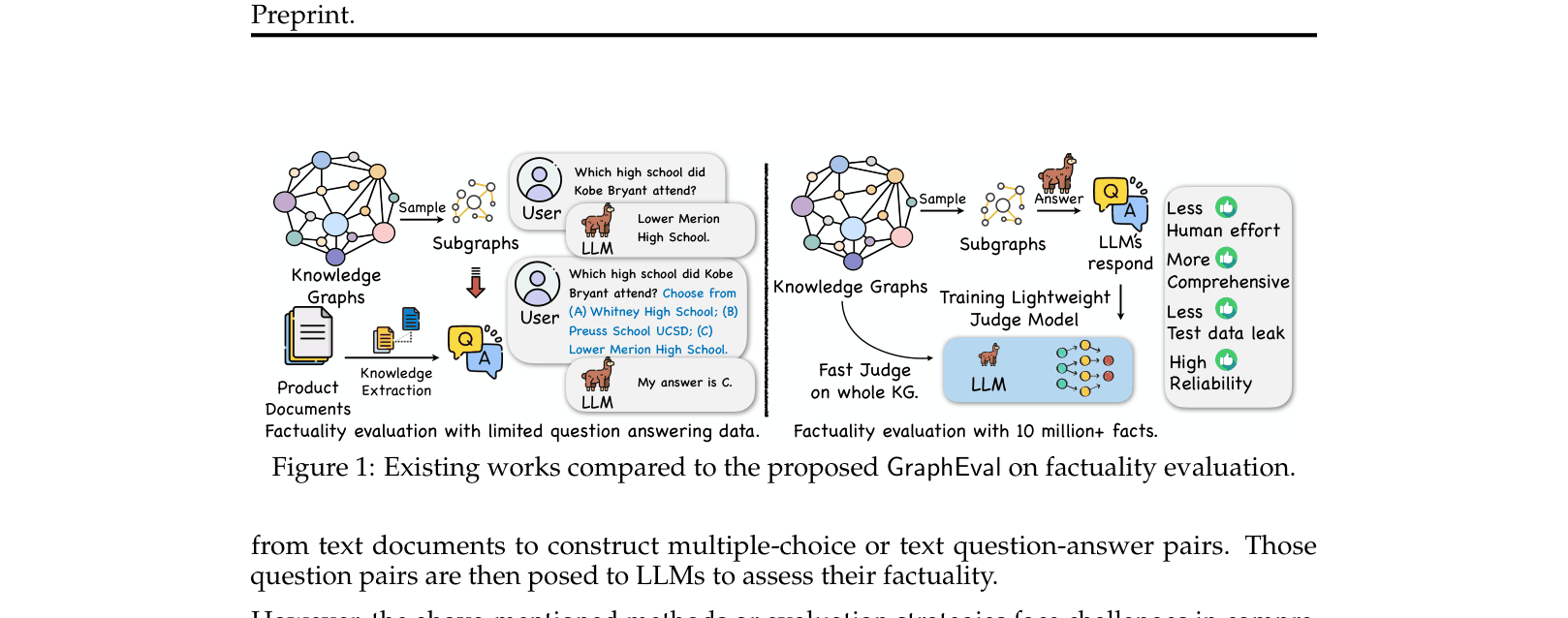
Factuality Evaluation
Knowledge Graph (KG) Integration
GraphEval efficiently evaluates LLM factuality at scale by using a lightweight judge model to assess truthfulness on millions of declarative statements derived from Knowledge Graphs.
Core Problem
Existing factuality benchmarks are limited in scope, domain-specific, and computationally expensive because they require generating full text and meticulous human or heavy-model validation.
Why it matters:
- Limited evaluation data restricts breadth, failing to cover the wide range of topics LLMs handle
- High costs of generating and validating full-text responses make frequent large-scale evaluations infeasible
- Small benchmarks carry risks of bias and data leakage, compromising evaluation validity
Concrete Example:
For the triple (Barack Obama, birthPlace, Hawaii), asking a multiple-choice question might confuse the model with distractors. Asking for full generation requires expensive parsing. GraphEval converts this to 'Obama was born in Hawaii' and uses a lightweight judge to classify the LLM's hidden state response as True/False/IDK.
Key Novelty
KG-driven retrieval with lightweight judge model (GraphEval)
- Utilizes entire Knowledge Graphs (like DBpedia) to generate millions of factual True/False prompts automatically, avoiding manual labeling
- Replaces expensive text generation with a lightweight judge model that predicts 'True', 'False', or 'IDK' directly from the LLM's hidden states
- Uses a prompt encoder to compress instruction prefixes, further reducing computational overhead for the judge
Architecture
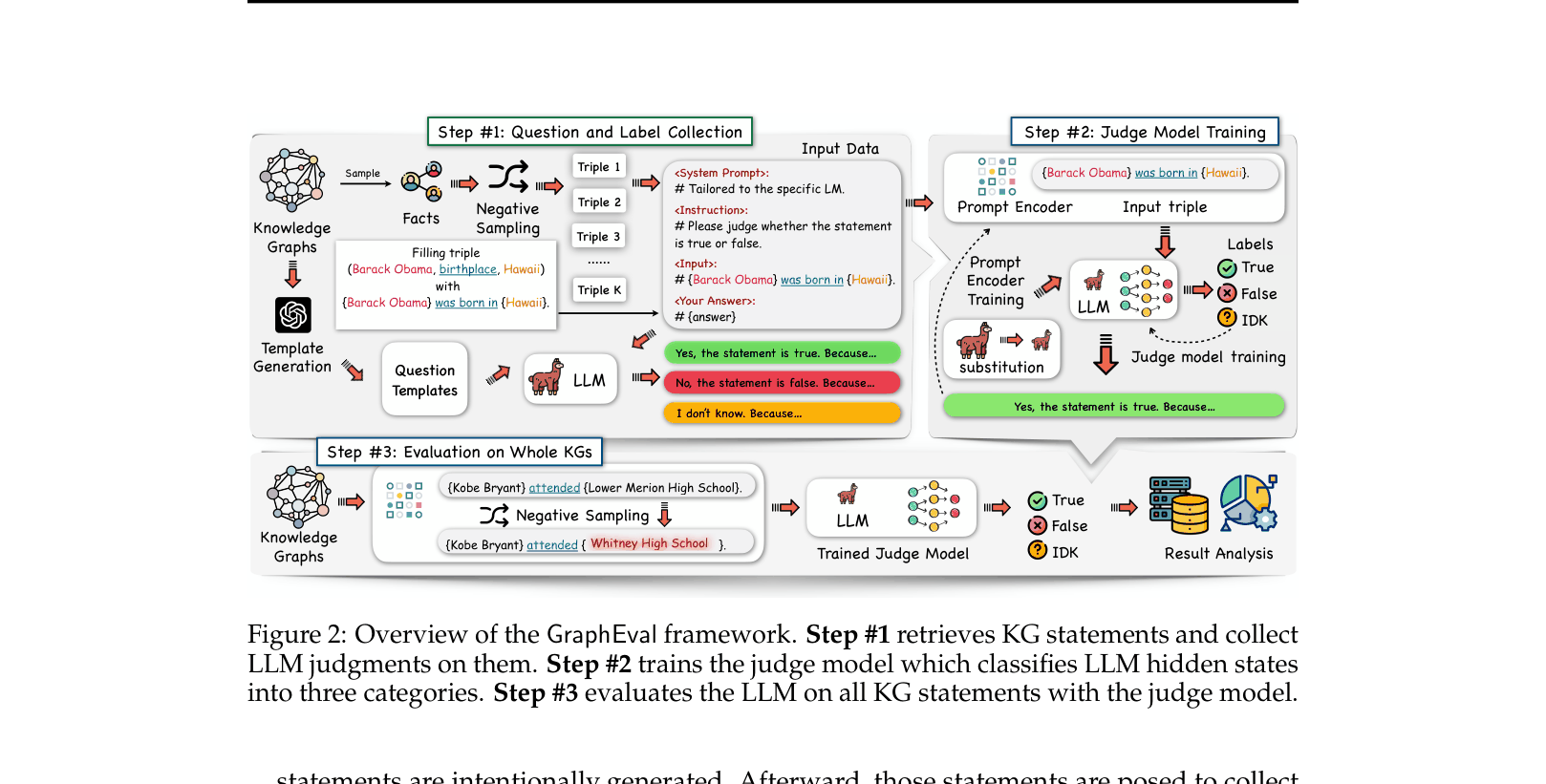
The GraphEval framework workflow: from KG sampling to Judge Model training and final Evaluation.
Evaluation Highlights
- Evaluates on 10 million facts from DBpedia, significantly larger than existing benchmarks like FELM or TruthfulQA
- Judge model achieves high accuracy (implied by high alignment claims) while substantially reducing evaluation costs compared to generating full text
- Demonstrates that judge model performance is robust across different LLM sizes (7B to 70B), allowing the use of smaller substitute models for efficient hidden state computation
Breakthrough Assessment
7/10
Significant scale-up for factuality evaluation (10M facts vs thousands) with a practical efficiency solution (judge model). However, relies on simple triple-based facts rather than complex reasoning.