📊 Experiments & Results
Evaluation Setup
Weakly-supervised reasoning on complex puzzles and riddles
Benchmarks:
- PuzzleBen (Complex Reasoning (Brainteasers, Riddles, Puzzles, Parajumbles, Critical Reasoning)) [New]
Metrics:
- Not explicitly reported in the paper
- Statistical methodology: Not explicitly reported in the paper
Experiment Figures
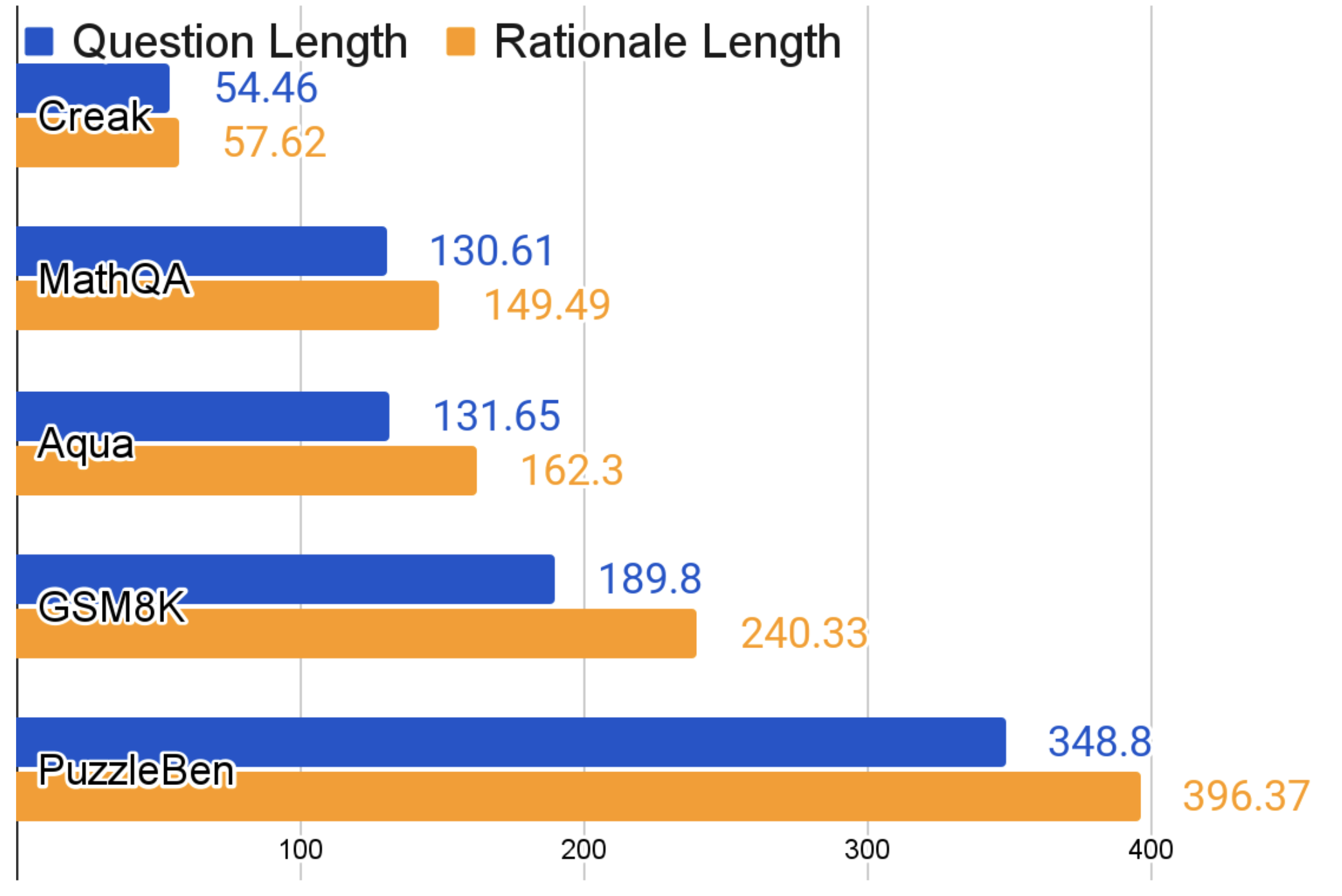
Comparison of average lengths of questions and rationales between PuzzleBen and other benchmarks
Main Takeaways
- The paper introduces PuzzleBen, a large-scale dataset (25k+ labeled, 10k unlabeled) focusing on lateral thinking puzzles and riddles.
- PuzzleBen features longer average question and rationale lengths (348.80 and 396.37 characters respectively) compared to existing benchmarks, indicating higher complexity.
- The methodology proposes using relative performance between an SFT model and a base model as a signal for self-improvement, avoiding the need for extensive human annotation.
- Qualitative assertion: Experiments underscore the significance of PuzzleBen and the effectiveness of the methodology (though specific numbers are missing in the text).