📝 Paper Summary
Vision-Language-Action (VLA) models
Robot Manipulation
EvoScene-VLA improves multi-step robot control by co-denoising actions and future scene states, creating an action-updated geometric prior that persists across decision chunks.
Core Problem
Chunked VLA policies typically predict actions based only on current observations, lacking a compact, persistent record of how the robot's recent actions have transformed the scene's geometry.
Why it matters:
- Robot actions cause contact, occlusion, and object motion, significantly changing the geometry before the next camera frame arrives
- Relying purely on past visual history or spatial encodings forces the policy to constantly re-infer changes from noisy or occluded visual evidence
- Without a persistent, action-updated scene prior, prediction errors compound across sequential control decisions
Concrete Example:
When a robot wipes a counter or lifts a cup, the scene geometry changes instantly. Existing models forget these action-induced changes across decision chunks, whereas EvoScene-VLA maintains a recurrent geometric prior to remember that the shelf slot is now empty even if the camera is occluded.
Key Novelty
Recurrent Scene Prefix with Joint Action-Scene Denoising
- EvoScene-VLA maintains a recurrent prefix in the VLM containing observation slots from the current image and a scene prior inherited from the last action
- The action decoder jointly generates the next action sequence and the anticipated future scene state in a single flow-matching pass
- During training, auxiliary modules ground these scene tokens in 3D geometry and future states, but these are discarded at inference for efficiency
Architecture
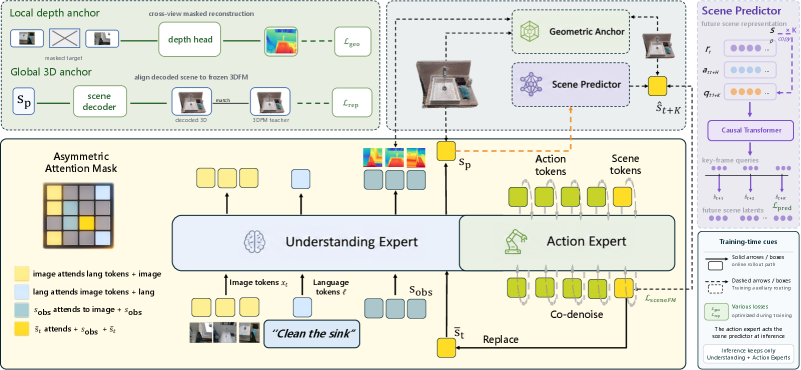
The architecture of EvoScene-VLA, highlighting the recurrent scene prefix, attention masking, and joint action-scene flow-matching denoising
Evaluation Highlights
- +1.9 percentage points average success rate over the best baseline on 31 RoboTwin tasks under fixed initial conditions (87.2% to 89.1%)
- +2.4 percentage points average success rate on RoboTwin tasks under randomized initial conditions (86.1% to 88.5%)
Breakthrough Assessment
8/10
Presents an elegant, inference-efficient architecture to maintain geometric scene states across VLA chunks without auxiliary online predictors, yielding solid empirical gains in simulation and real robot trials.