📝 Paper Summary
Modularized RAG pipeline
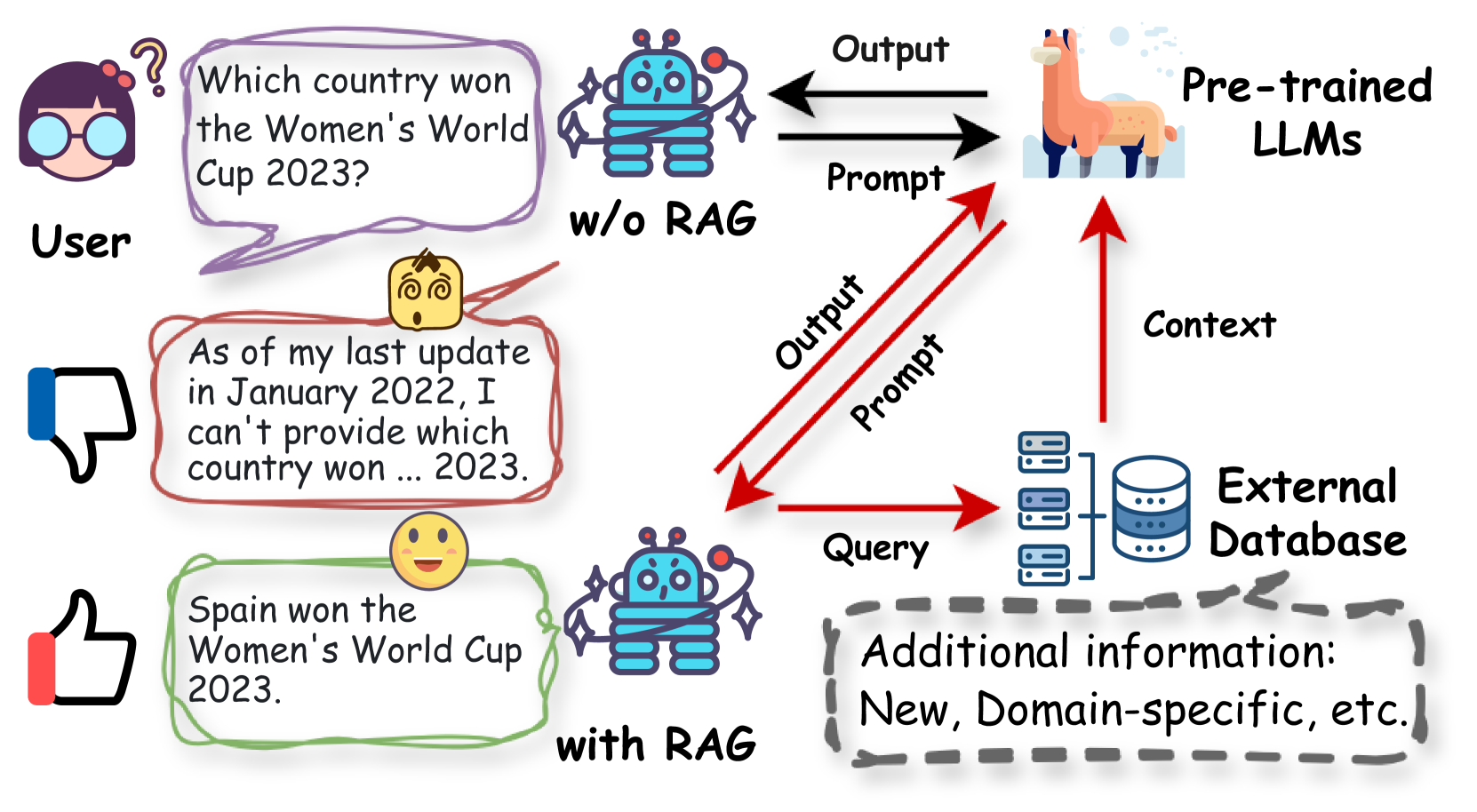
Retrieval-Augmented Generation (RAG)
This survey systematically categorizes Retrieval-Augmented Large Language Models (RA-LLMs) into three paradigms—architectures, training strategies, and applications—providing a comprehensive roadmap of how external knowledge integration enhances LLM generation.
Core Problem
Large Language Models (LLMs) suffer from inherent limitations including hallucinations, outdated internal knowledge, and a lack of domain-specific expertise, which hinder their reliability in real-world applications.
Why it matters:
- Hallucination rates in critical domains like law can range from 69% to 88%, making unaugmented LLMs unreliable for professional use
- Fine-tuning LLMs to update knowledge is computationally expensive and slow, failing to keep pace with rapidly changing information
- Previous surveys often lack a systematic review of the specific technical architectures and training paradigms unique to the intersection of RAG and LLMs
Concrete Example:
An LLM-based dialog system fails to answer 'What is the latest news about the 2024 election?' because its training data cutoff was in 2023. Without RAG to retrieve the latest news articles, the model either refuses to answer or hallucinates a plausible but false scenario based on older data.
Key Novelty
Comprehensive Taxonomy of RA-LLMs
- Categorizes RAG systems by Architecture (Retriever-Generator interaction), Training Strategy (independent vs. joint training), and Augmentation methodology (Input vs. Output vs. Intermediate integration)
- Systematically reviews the necessity of retrieval, discussing when to retrieve (adaptive retrieval) versus always retrieving, to balance efficiency and accuracy
Architecture
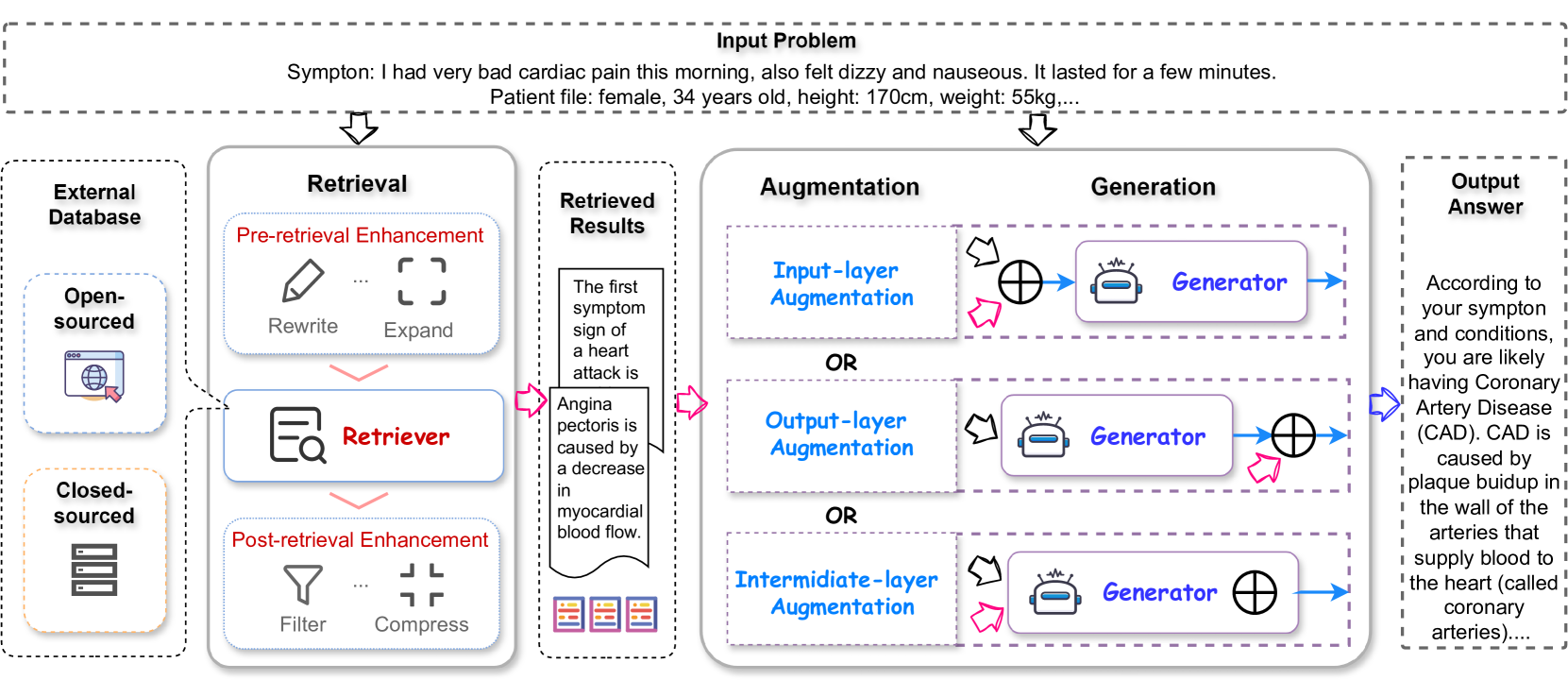
A unified framework of Retrieval-Augmented Large Language Models (RA-LLMs) categorizing the three main components: Retrieval, Generation, and Augmentation.
Evaluation Highlights
- Highlights that retrieval-augmented methods like RAG and REALM significantly outperform standalone LLMs on Open-domain QA benchmarks (Natural Questions, TriviaQA)
- Notes that legal hallucinations in state-of-the-art LLMs can reach 69-88%, which RAG frameworks effectively mitigate by grounding generation in retrieved statutes
- Demonstrates that general-purpose retrievers (like Contriever) without fine-tuning achieve comparable performance to sparse retrievers (BM25) but lag behind task-tuned dense retrievers (DPR)
Breakthrough Assessment
9/10
An extensive, highly structured survey that became a foundational reference for the RAG field, clearly defining the paradigms of retrieval, generation, and augmentation.