📝 Paper Summary
Knowledge internalization
Synthetic data generation
Expert domain adaptation
Active Reading improves factual recall in LLMs by having the model self-generate diverse study strategies (paraphrasing, quizzing, linking) for documents rather than just training on raw text.
Core Problem
LLMs struggle to reliably learn and recall facts from their training data, especially for long-tail information that appears sparsely, and standard fine-tuning often leads to overfitting or hallucinations.
Why it matters:
- Rote memorization of raw text is inefficient for robust knowledge integration and generalization
- Current methods like simple repetition or standard paraphrasing plateau in performance as data scale increases
- Integrating new knowledge into models remains brittle, limiting the creation of expert models in domains like finance or medicine
Concrete Example:
When finetuning on raw Wikipedia documents, a model might fail to answer 'Who received the IEEE Frank Rosenblatt Award in 2010?' because it only saw the fact once in a specific context. Standard augmentation (paraphrasing) provides limited diversity, leading to recall failures on such tail facts.
Key Novelty
Active Reading (Self-Generated Study Strategies)
- Instead of using fixed templates (like just QA pairs), the model prompts itself to invent diverse 'study strategies' (e.g., create a timeline, explain via analogy, map concepts) for a given document
- These self-generated strategies are then executed by the model to create diverse synthetic training data that forces it to process the information deeply from multiple angles
Architecture
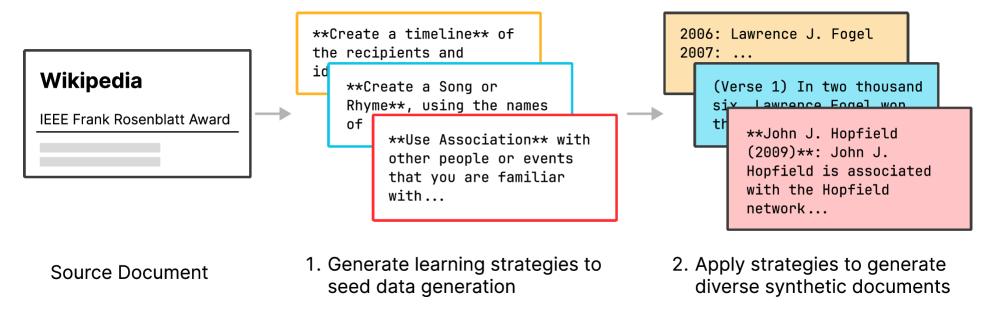
Conceptual workflow of Active Reading. It contrasts standard training (reading raw text) with Active Reading (generating strategies -> synthesizing data -> learning).
Evaluation Highlights
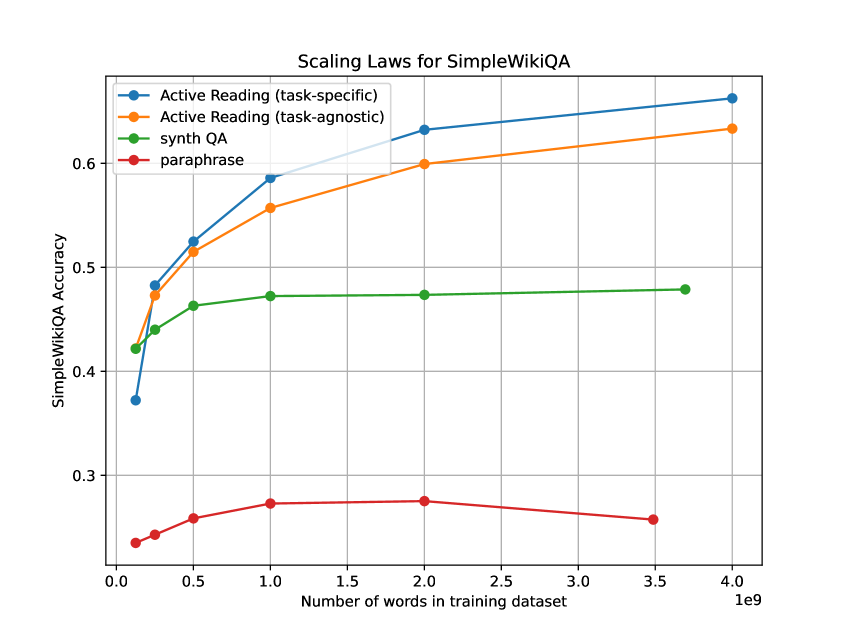
- +50 percentage points absolute improvement (16% -> 66%) on SimpleWikiQA compared to vanilla finetuning, outperforming standard paraphrasing and synthetic QA
- Meta WikiExpert-8B (trained on 1T Active Reading tokens) outperforms the much larger Llama 3.1 405B on SimpleQA (23.5% vs 17.1%)
- Superior scaling behavior: Unlike synthetic QA which plateaus, Active Reading performance continues to improve linearly as synthetic data volume scales up to 4B words
Breakthrough Assessment
8/10
Significant jump in factual recall for 8B models, outperforming 400B+ models on specific benchmarks. The method offers a scalable alternative to RAG for knowledge-intensive tasks.