📝 Paper Summary
Memory recall
Memory organization
MemLLM fine-tunes a language model to interact with an external, structured database via explicit read/write API calls, enabling interpretable knowledge storage and editing without retraining parameters.
Core Problem
Standard LLMs rely on implicit parametric memory, making it difficult to update facts, memorize rare events, and interpret stored knowledge, while RAG methods often lack structure for precise editing.
Why it matters:
- Parametric knowledge degrades over time and requires expensive retraining or unreliable editing methods to update.
- Unstructured RAG storage complicates atomic fact editing (changing one fact might require modifying many documents to prevent contradictions).
- Lack of interpretability in parametric memory makes preventing hallucinations and verifying stored facts challenging.
Concrete Example:
When a fact changes (e.g., a Prime Minister changes), a standard LLM might hallucinate or output outdated info. Parametric editing (like ROME) struggles with sequential updates. MemLLM simply executes a `MEM_WRITE` command to update the structured triple in the database.
Key Novelty
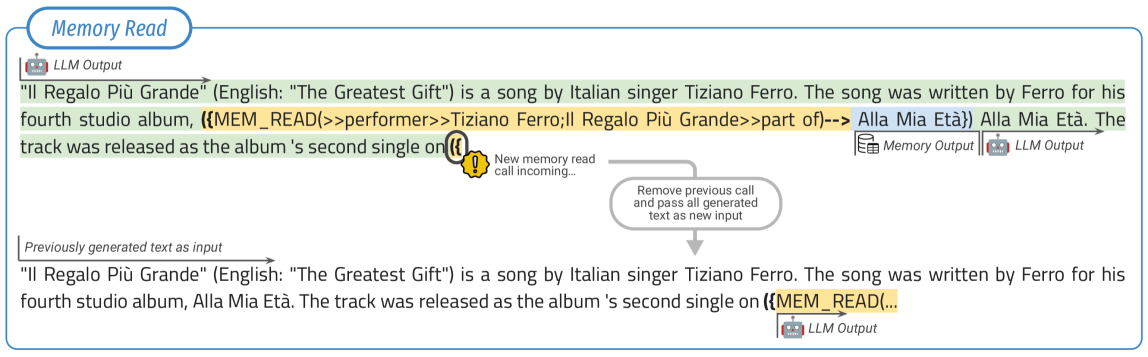
Explicit Read-Write Memory via API Fine-tuning
- Treats memory access as tool use: fine-tunes the LLM to generate text-based API calls (`MEM_WRITE`, `MEM_READ`) interleaved with normal generation.
- Uses a structured database (triples of subject, relation, object) rather than raw text or vector pools, making the memory human-readable and editable.
- Teaches the model to 'write' to memory while processing context and 'read' from memory before generating entities.
Architecture

The schema of the structured memory and how entities and relations are linked.
Evaluation Highlights
- Outperforms standard LLMs on language modeling perplexity (20.53 vs 21.65 for Llama-2-7b-chat) on Re-DocRED, with significant gains on named entities.
- Achieves superior knowledge editing performance (Sustainability Score: 24.3 vs 19.5 for ROME) when handling sequential edits.
- Demonstrates high efficacy in memory utilization, improving named entity prediction accuracy by +13.5% compared to no-memory baselines.
Breakthrough Assessment
7/10
Strong conceptual advance in making LLM memory interpretable and editable via structured APIs. While the scale is limited to relation triples, it offers a distinct alternative to vector-only RAG or parametric editing.