📝 Paper Summary
Video Multimodal Large Language Models (VMLLMs)
Fine-grained video understanding
VideoPerceiver enhances the perception of brief actions and rare events in videos by training on constructed "key-information-missing" clips and using a relative reward mechanism that prioritizes detailed visual reasoning.
Core Problem
Current Video MLLMs fail to perceive fine-grained temporal events (brief actions or rare transient moments) due to uniform sampling strategies and text-centric reward designs that prioritize fluency over visual precision.
Why it matters:
- Models miss critical but brief events like traffic accidents in surveillance or fleeting facial micro-expressions, rendering them unreliable for safety-critical applications
- Uniform frame sampling discards short-duration visual cues, while standard holistic encoding averages out localized details needed for precise temporal reasoning
Concrete Example:
In a long surveillance video, a traffic accident may last only 1-2 seconds (<1% of duration). Standard models using uniform sampling might miss these frames entirely, or generate generic captions ignoring the crash because their reward functions focus on text quality rather than visual evidence recovery.
Key Novelty
Contrastive Missing-Information Recovery & Comparative RL
- Creates synthetic training pairs where keyframes of an action are replaced by neighbors; the model learns to identify these missing details by contrasting the full video against the degraded version
- Uses a reinforcement learning reward that explicitly compares the quality of answers generated from the full video versus the degraded video, rewarding the model only when the full video yields a better answer
Architecture
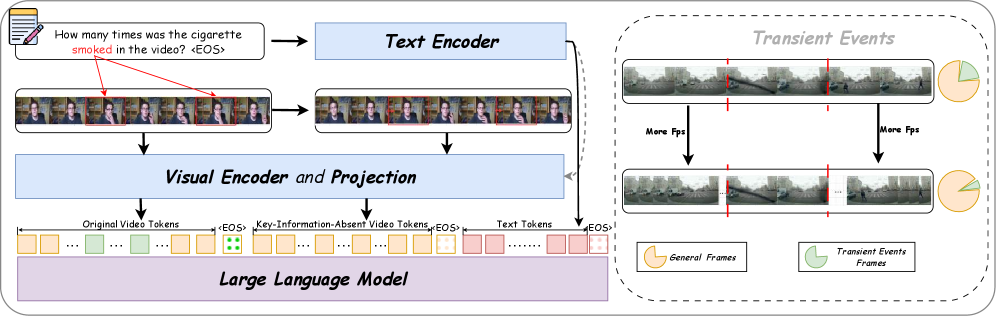
The complete training pipeline including Key-Information-Absent Video Construction and Comparative GRPO.
Evaluation Highlights
- Achieves 0.61 on MotionBench Repetition Count (VideoPerceiver-7B), surpassing Qwen2.5-VL-7B by +0.26 and marking the first score >0.6 on this subtask
- +22.9% average accuracy improvement on VRU-Accident VQA for VideoPerceiver-3B compared to Qwen2.5-VL-3B
- State-of-the-art performance on Dense Caption generation for VRU-Accident, outperforming baselines in BLEU, METEOR, and ROUGE metrics
Breakthrough Assessment
8/10
Significant methodology shift for video LLMs by introducing 'negative' video samples (missing keyframes) into both SFT and RL, yielding large gains on difficult fine-grained benchmarks.
