📝 Paper Summary
Theoretical Expressivity of Transformers
Formal Language Theory for Neural Networks
Transformers using either hard or sparse attention can exactly represent any n-gram language model, with trade-offs between the number of heads, layers, and embedding dimensionality.
Core Problem
Most theoretical analyses of transformers focus on binary language acceptance (classifiers), which mismatches the definition of language models as probability distributions over strings.
Why it matters:
- Analyzing LMs as recognizers introduces a category error, ignoring the probabilities essential to language modeling
- Understanding probabilistic capacity is crucial for interpreting how LMs implement formal computation models
- Existing results on binary recognition do not directly translate to the autoregressive probability generation used in modern LMs
Concrete Example:
A standard analysis might ask if a transformer can classify a string as valid/invalid Dyck-k. However, an LM assigns a probability to every token sequence. This paper asks if a transformer can exactly match the conditional probability distribution P(w_t | w_{t-n+1}...w_{t-1}) of a classical n-gram model.
Key Novelty
Exact Probabilistic Simulation of n-gram LMs by Transformers
- Constructs explicit weights showing how a transformer can copy previous symbols to the current position to form a history representation
- Demonstrates that multiple mechanisms exist for this simulation: using n-1 attention heads in parallel OR n-1 layers in sequence
- Extends the proof from idealized hard attention to differentiable sparse attention (sparsemax), bridging theory and practice
Architecture
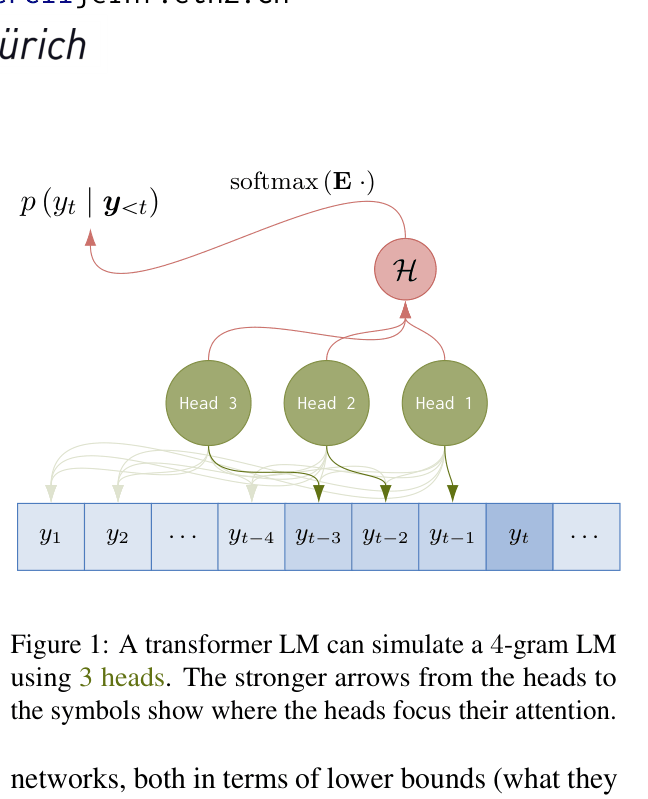
A schematic of a transformer LM simulating a 4-gram LM using 3 attention heads in a single layer
Evaluation Highlights
- Theorem 3.1: A single-layer hard attention transformer with n-1 heads can exactly represent any n-gram LM
- Theorem 3.2: A single-head hard attention transformer with n-1 layers can exactly represent any n-gram LM
- Theorem 4.1: A single-layer sparse attention transformer with n-1 heads can exactly represent any n-gram LM
Breakthrough Assessment
7/10
Solid theoretical foundation establishing a clear lower bound on transformer expressivity. While n-grams are simple, shifting the analysis from binary recognition to probabilistic modeling is a significant methodological improvement.