📝 Paper Summary
Tabular Question Answering
LLM Evaluation
Table Reasoning
DataBench is a diverse benchmark of 65 real-world tabular datasets and 1300 questions designed to reveal the limitations of LLMs in reasoning over structured data types beyond simple Wikipedia tables.
Core Problem
Existing tabular QA benchmarks primarily rely on clean, small Wikipedia tables that lack the complexity, size, and diverse data types (booleans, lists, URLs) found in real-world data analysis tasks.
Why it matters:
- Current benchmarks like OpenWikiTables are saturated and do not test reasoning over lists, booleans, or dirty data
- Real-world data analytics involves large tables (millions of rows) and diverse types (dates, URLs, lists) not represented in academic datasets
- There is a significant gap in understanding how well current LLMs function as reliable tabular reasoners for business intelligence
Concrete Example:
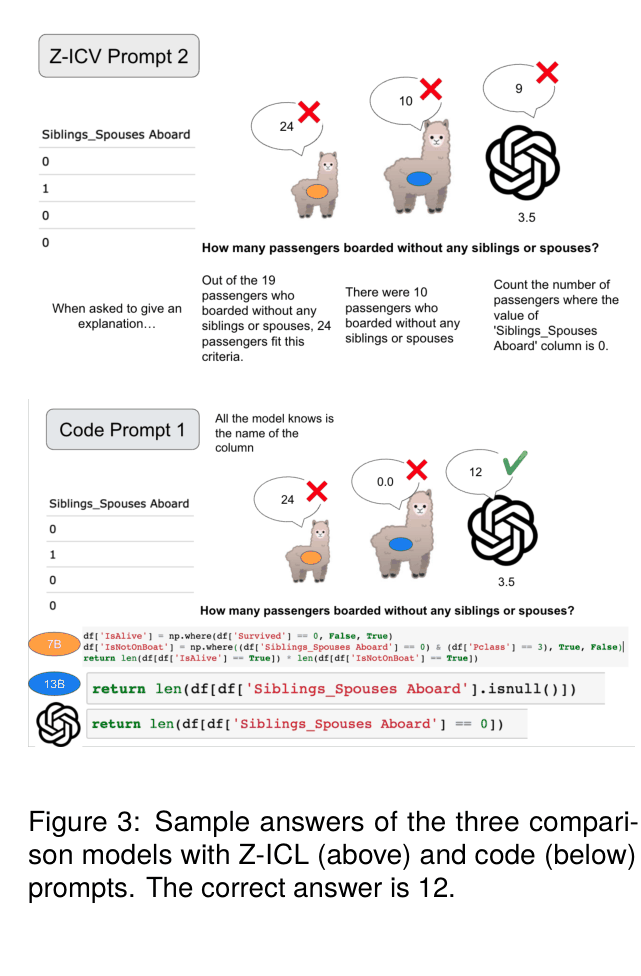
A user asks 'Are there any passengers under 30?' on a dataset. A Wikipedia-based model might fail because it hasn't seen list-type answers like '[Lil Lama, Cody Lama]' or boolean logic columns in training, leading to format errors or hallucinations.
Key Novelty
DataBench: Diverse Real-World Tabular QA Benchmark
- Aggregates 65 heterogeneous datasets from domains like Finance, Health, and Sports, moving beyond Wikipedia to real-world sources like Kaggle and government data
- Introduces complex answer types rarely tested: lists of numbers, lists of categories, and booleans, alongside standard number/text answers
- Evaluates two distinct prompting paradigms: Zero-shot In-Context Learning (feeding data directly) vs. Code-based (generating Python/Pandas code)
Architecture
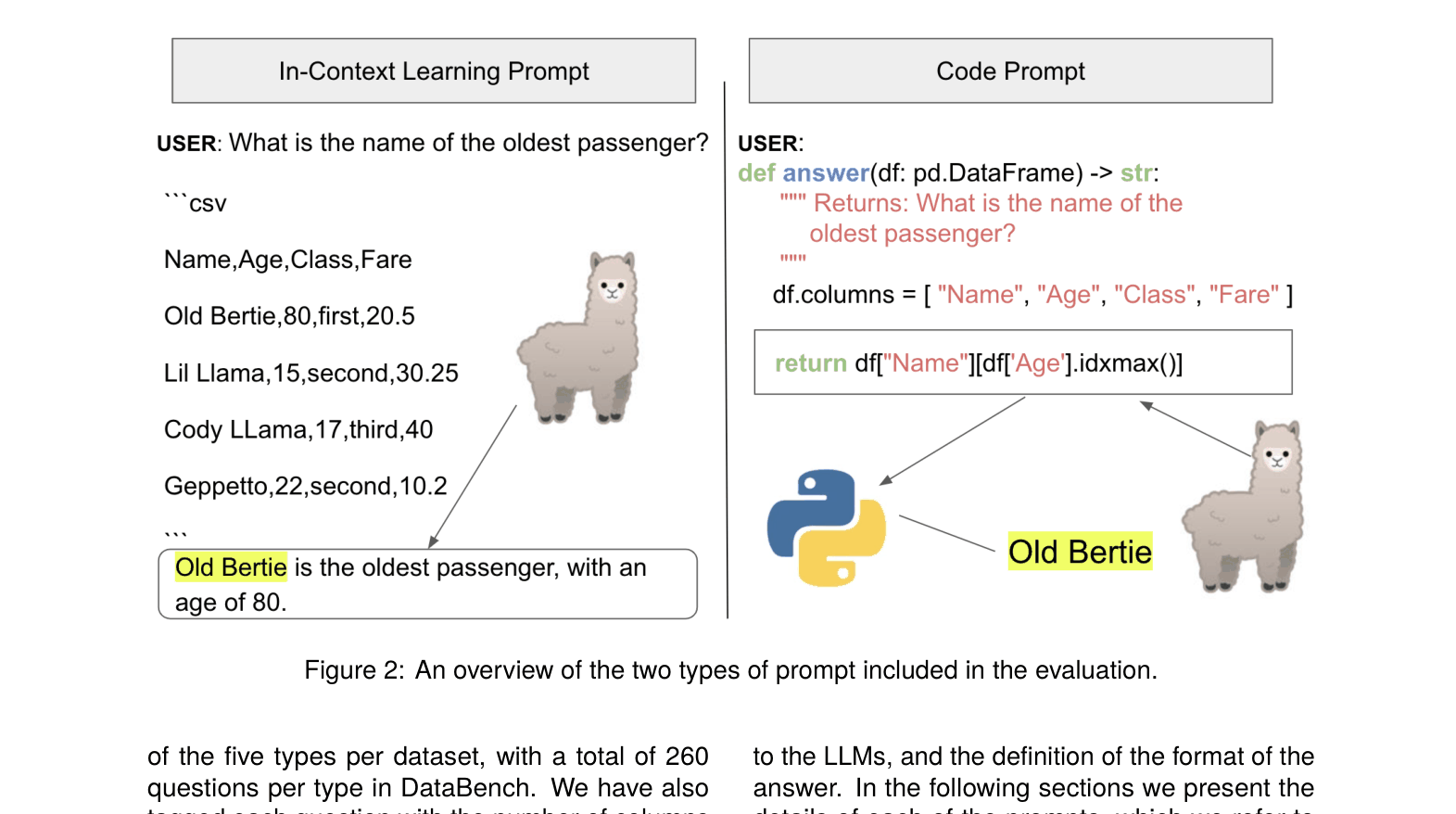
Overview of the two evaluation prompting strategies: In-Context Learning (Z-ICL) vs. Code-based.
Evaluation Highlights
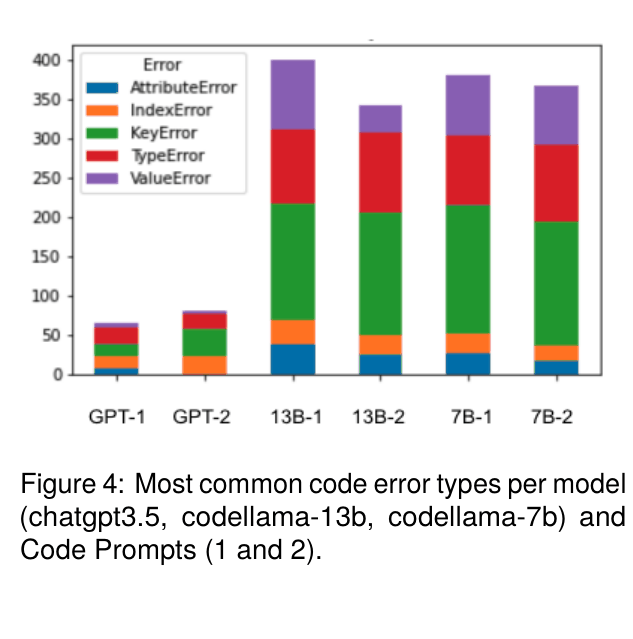
- ChatGPT-3.5 (closed source) achieves 63.0% accuracy on Code-based prompts, significantly outperforming the best open model (CodeLlama-13b) at 33.1%
- All models struggle significantly with 'list' answer types; Llama-2-7b achieves only 0.8% accuracy on list[number] questions using In-Context Learning
- Using Code-based prompts consistently outperforms In-Context Learning for numerical reasoning, raising accuracy from ~14% (text) to ~43% (code) for CodeLlama-7b on number questions
Breakthrough Assessment
7/10
Significant contribution to evaluation methodology by introducing a realistic, diverse benchmark that exposes major gaps in current LLMs (especially open-source) regarding tabular reasoning.