📝 Paper Summary
Knowledge Editing
Evaluation Benchmarks
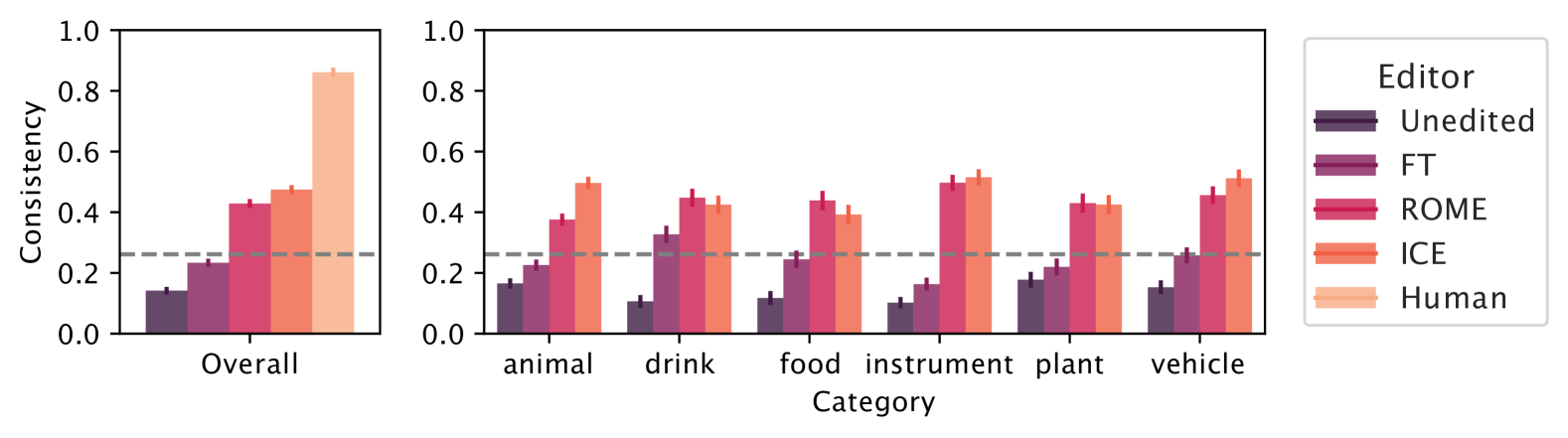
TAXI is a new benchmark that evaluates whether editing a subject's category in a language model correctly updates its associated properties, revealing that current editors struggle with consistency compared to humans.
Core Problem
Current knowledge editing benchmarks fail to adequately evaluate 'consistency'—whether injecting a new fact (e.g., category change) correctly propagates to related facts (e.g., inherited properties).
Why it matters:
- Effective model editing requires more than just recalling the specific edited fact; it must maintain a consistent worldview by updating logical consequences of that fact
- Existing benchmarks like CounterFact or MQuAKE focus on paraphrases or multi-hop retrieval but lack clear ground truth for broad property inheritance
- Inconsistent edits can lead to contradictory model outputs, where a model believes a subject belongs to a new category but still attributes old, conflicting properties to it
Concrete Example:
If a model is edited to believe a 'cobra' is a 'dog', it should consistently infer that the cobra now 'barks' and 'has fur'. Current editors might successfully change the category to dog but still predict the cobra 'has scales' or 'slithers'.
Key Novelty
Taxonomic Inference (TAXI) Benchmark
- Leverages the hierarchical nature of taxonomic categories (e.g., Animals, Vehicles) where category membership strictly entails specific properties
- Evaluates 'Categorical Consistency': measuring if an edit to a subject's category (e.g., pitbull → cat) causes the subject to inherit the new category's properties (e.g., meows) and lose the old ones
- Introduces a controlled dataset of 11,120 queries where ground truth property changes are unambiguous, enabling precise measurement of edit propagation
Architecture
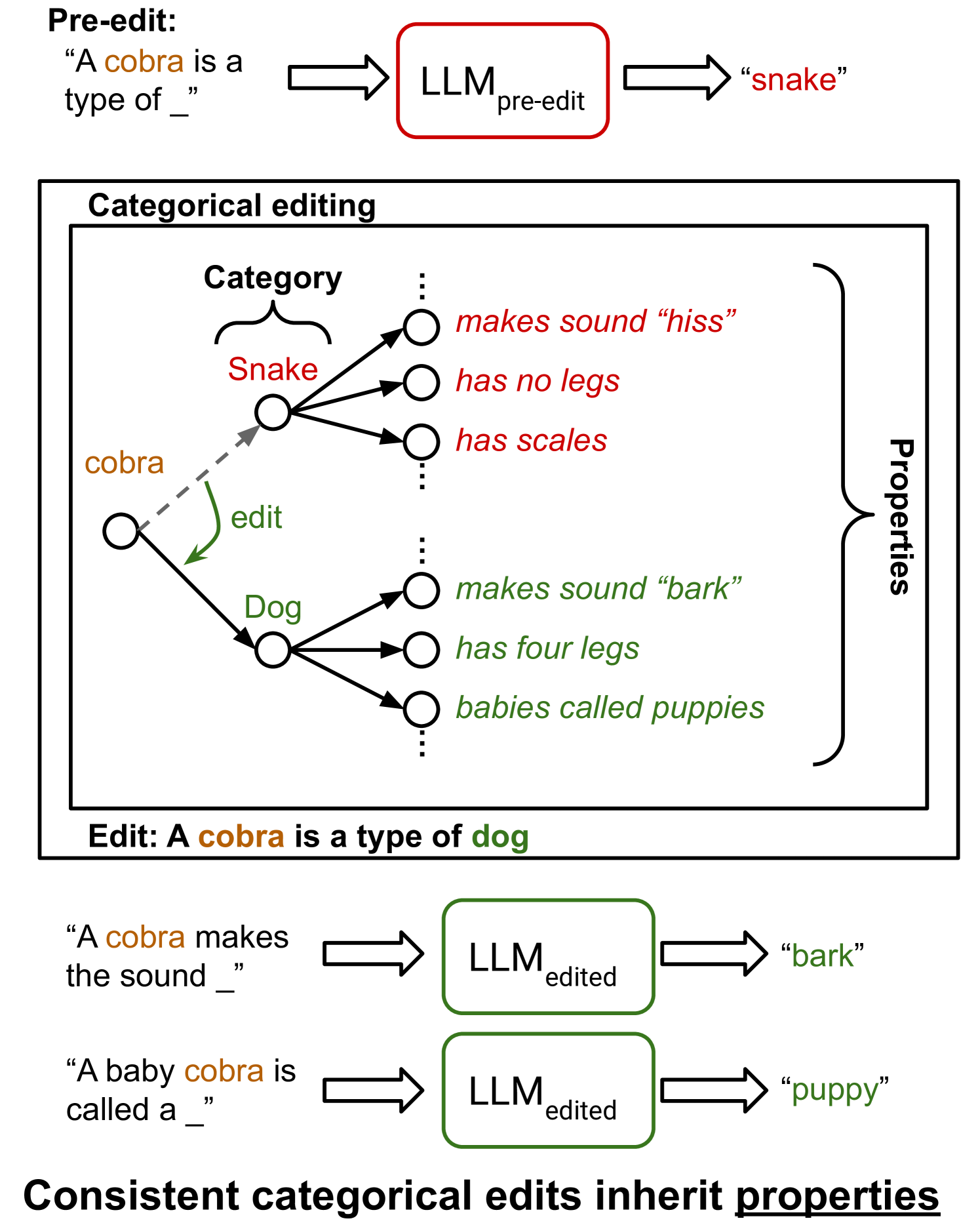
Conceptual diagram of the TAXI benchmark task structure.
Evaluation Highlights
- Human annotators achieve 86.8% consistency on the TAXI task, whereas the best model editor (ICE) achieves only ~45% consistency on changed properties
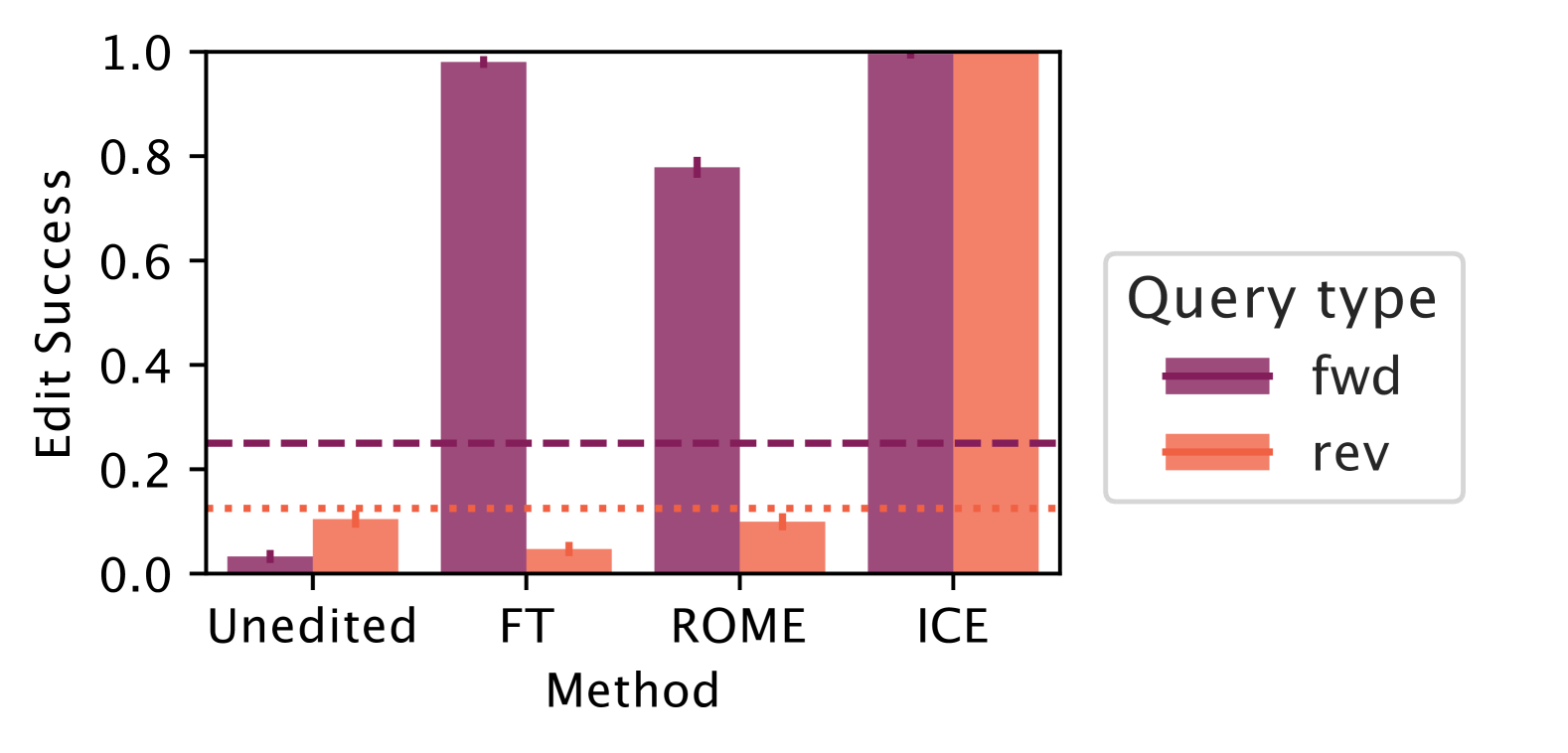
- Editors like ROME and In-Context Editing (ICE) successfully update the category label (>90% success) but fail to consistently update the associated properties
- Consistency is generally higher for 'atypical' subjects (rare entities) compared to typical ones, supporting recent findings that rare knowledge is easier to edit
Breakthrough Assessment
7/10
Offers a crucial, biologically-inspired metric (consistency via property inheritance) that exposes a major failure mode in current editing methods. The gap between edit success and property consistency is a significant finding.