📝 Paper Summary
Mechanistic Interpretability
Transformer Analysis
This primer provides a unified technical framework and notation for understanding the internal mechanisms of decoder-only Transformers, categorizing techniques into localization of predictions and decoding of learned representations.
Core Problem
Rapid progress in large language models has created a need to contextualize dispersed interpretability insights and standardize the technical understanding of how these black-box models process information internally.
Why it matters:
- Understanding internal mechanisms is crucial for ensuring AI safety, fairness, and error mitigation in critical settings
- Previous surveys focused heavily on encoder-based models like BERT, leaving a gap for modern decoder-only generative architectures
- Disparate notations and terminologies across research papers make it difficult to connect insights and identify common mechanisms
Concrete Example:
In a standard linear network, representations are rotationally invariant, making it hard to isolate meaningful features. However, the paper explains how the element-wise nonlinearity in Feed-Forward Networks creates a 'privileged basis,' forcing features to align with specific neurons—a crucial insight for interpretability that is often misunderstood without a unified theoretical view.
Key Novelty
Unified Technical Primer for Transformer Interpretability
- Establishes a unified mathematical notation to describe model components (Residual Stream, Attention, MLP) and interpretability methods, revealing connections between seemingly different approaches
- Categorizes the vast literature into two primary dimensions: 'localization' (identifying components responsible for predictions) and 'decoding' (extracting information from representations)
- Synthesizes discrete mechanical insights (e.g., OV circuits, induction heads) into a comprehensive overview of known internal mechanisms within a single consistent framework
Architecture
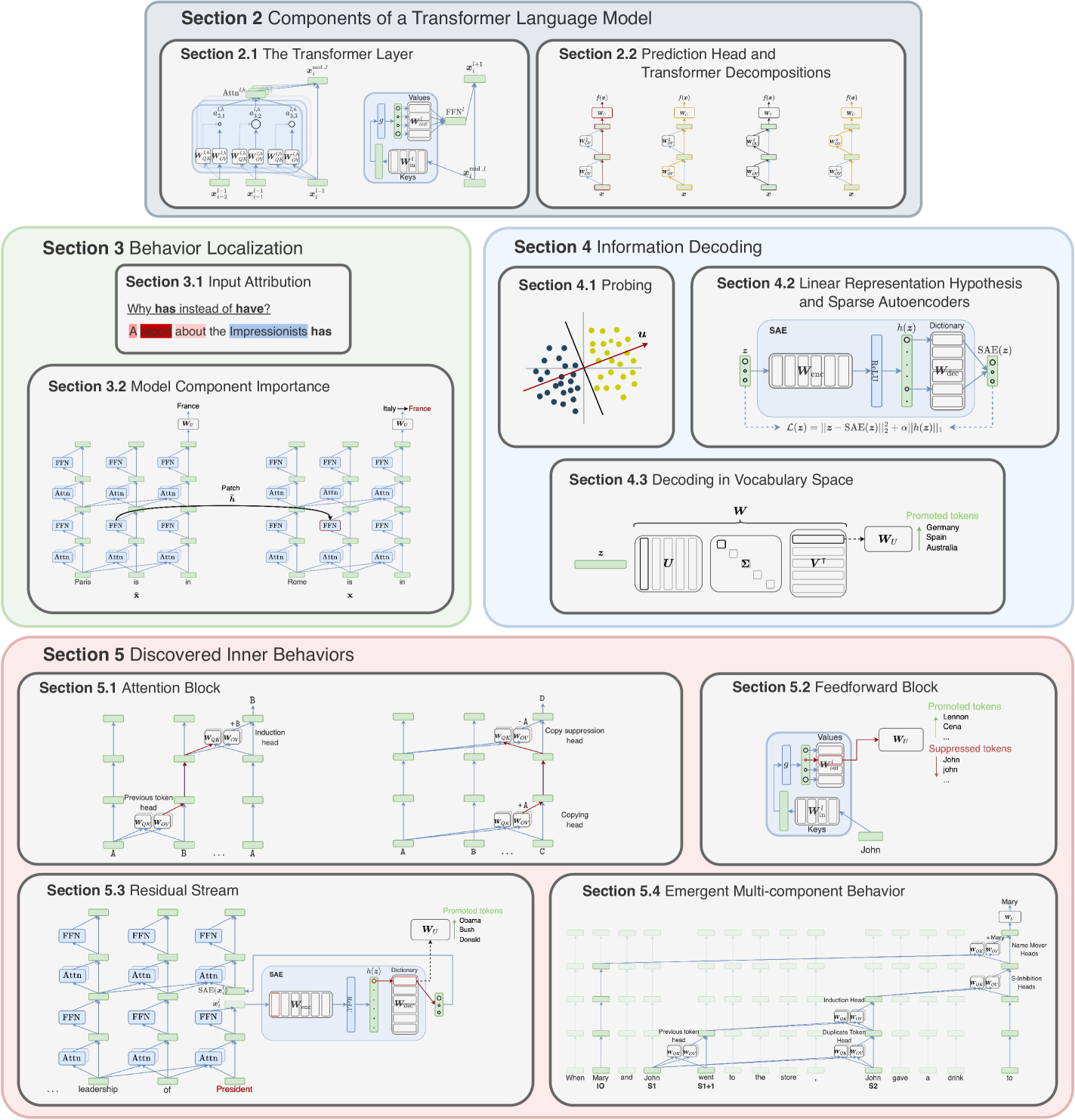
Decomposition of the Transformer architecture into the Residual Stream view
Breakthrough Assessment
8/10
Excellent foundational resource that systematizes the chaotic field of mechanistic interpretability. While it doesn't propose a new model, its unification of notation and concepts is a significant contribution to the research community.