📝 Paper Summary
Model Fusion / Merging
Mixture-of-Experts (MoE)
Instruction Tuning
ULTRAFUSER integrates three highly specialized LLMs (text, code, math) into a single system using a trainable token-level gating mechanism and a mixed-domain instruction dataset to achieve high performance across all domains.
Core Problem
Training a single LLM to master distinct domains (text, code, math) simultaneously is difficult due to conflicting data distributions, where specialized training in one area often degrades performance in others (catastrophic forgetting).
Why it matters:
- General-purpose models often trail behind specialized models (like WizardMath or CodeLlama) in their specific niches.
- Existing fusion methods often require training experts from scratch (computationally expensive) or suffer from performance loss during static weight merging.
- Users currently have to choose between a generalist chat model with mediocre specialized skills or distinct models for coding/math that lack conversational ability.
Concrete Example:
A text-specialized model (UltraLM-2-13B) achieves ~71% on text benchmarks but only ~19.9% on math. Conversely, a math specialist (WizardMath-13B) hits ~28.4% on math but drops to ~39.2% on text tasks.
Key Novelty
ULTRAFUSER: Post-Specialist Token-Level Fusion
- Instead of training experts from scratch (standard MoE), it fuses already-trained, highly specialized dense models (Specialists) by keeping them active during inference.
- A light-weight, trainable gating network sits on top of the specialists, dynamically calculating a weighted sum of their output logits for every token.
- Uses a two-stage training strategy: first warming up the gate while freezing specialists, then fine-tuning all parameters jointly to align representations.
Architecture
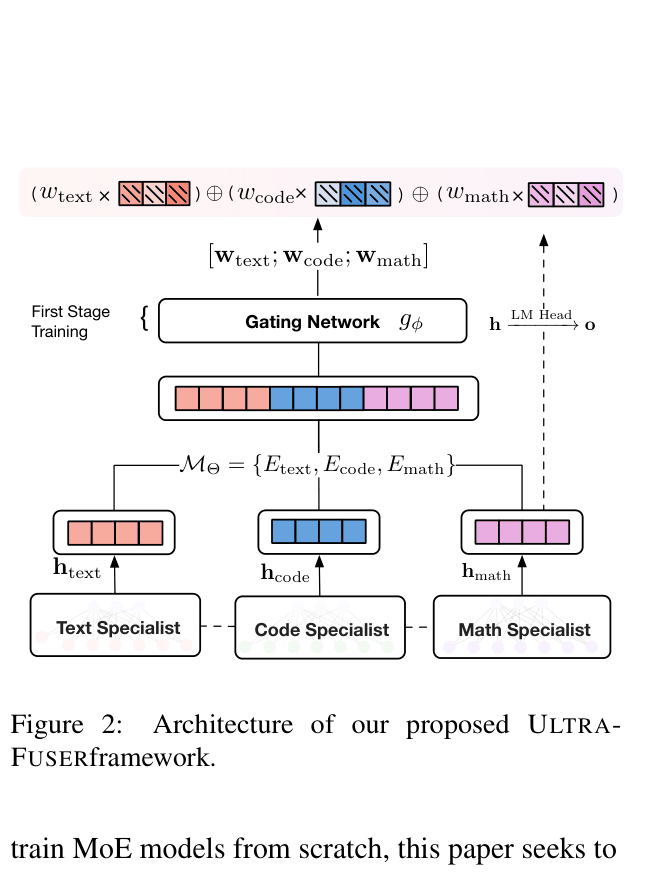
The architecture of ULTRAFUSER, illustrating how three specialist models (Text, Code, Math) process input in parallel.
Evaluation Highlights
- ULTRAFUSER achieves 73.51% on Text benchmarks, outperforming the specialized UltraLM-2-13B (71.03%) and Llama-2-13B-Chat (62.36%).
- On Code (HumanEval Pass@1), ULTRAFUSER reaches 53.03%, surpassing the specialist CodeLlama-13B (48.78%) and GPT-3.5-Turbo (48.10%).
- On Math benchmarks, ULTRAFUSER scores 30.58%, outperforming the math specialist WizardMath-13B (28.44%) and Llama-2-13B-Chat (5.88%).
Breakthrough Assessment
7/10
Strong practical results showing a single model can outperform its constituent specialists. The architecture is straightforward but effective. The main contribution is the fusing strategy and the constructed dataset.
