📝 Paper Summary
Conversational Recommender Systems (CRS)
Agentic RAG pipeline
LLM-based recommendation
ChatCRS decomposes conversational recommendation into sub-tasks handled by specialized agents—a tool-augmented knowledge retriever and a LoRA-tuned goal planner—orchestrated by an LLM to improve both accuracy and proactivity.
Core Problem
General LLMs (like ChatGPT) struggle with domain-specific conversational recommendation because they lack external grounded knowledge and fail to proactively plan dialogue goals, leading to hallucinations and passive interactions.
Why it matters:
- LLMs hallucinate or provide generic answers in domains with scarce internal knowledge (e.g., Chinese movies vs. English movies)
- Without explicit goal planning, LLMs often fail to transition from chit-chat to recommendation, resulting in unproductive dialogue turns
- Current approaches evaluate recommendation only, ignoring the multi-round response generation quality essential for user engagement
Concrete Example:
When a user mentions 'Jimmy's Award', a standard LLM without domain knowledge might hallucinate facts or fail to link it to the movie 'The Piano in a Factory'. Without a goal plan, the LLM might just passively acknowledge the user ('That's interesting') instead of proactively recommending the movie.
Key Novelty
Multi-Agent Decomposition for CRS (ChatCRS)
- Decomposes the complex CRS task into sub-tasks: knowledge retrieval, goal planning, and response generation
- Treats knowledge retrieval as a tool-use problem where the LLM selects relation paths in a Knowledge Graph rather than just semantic search
- Uses a specialized small model (LoRA-tuned LLaMA-7b) for goal planning to guide the main LLM's conversation flow
Architecture
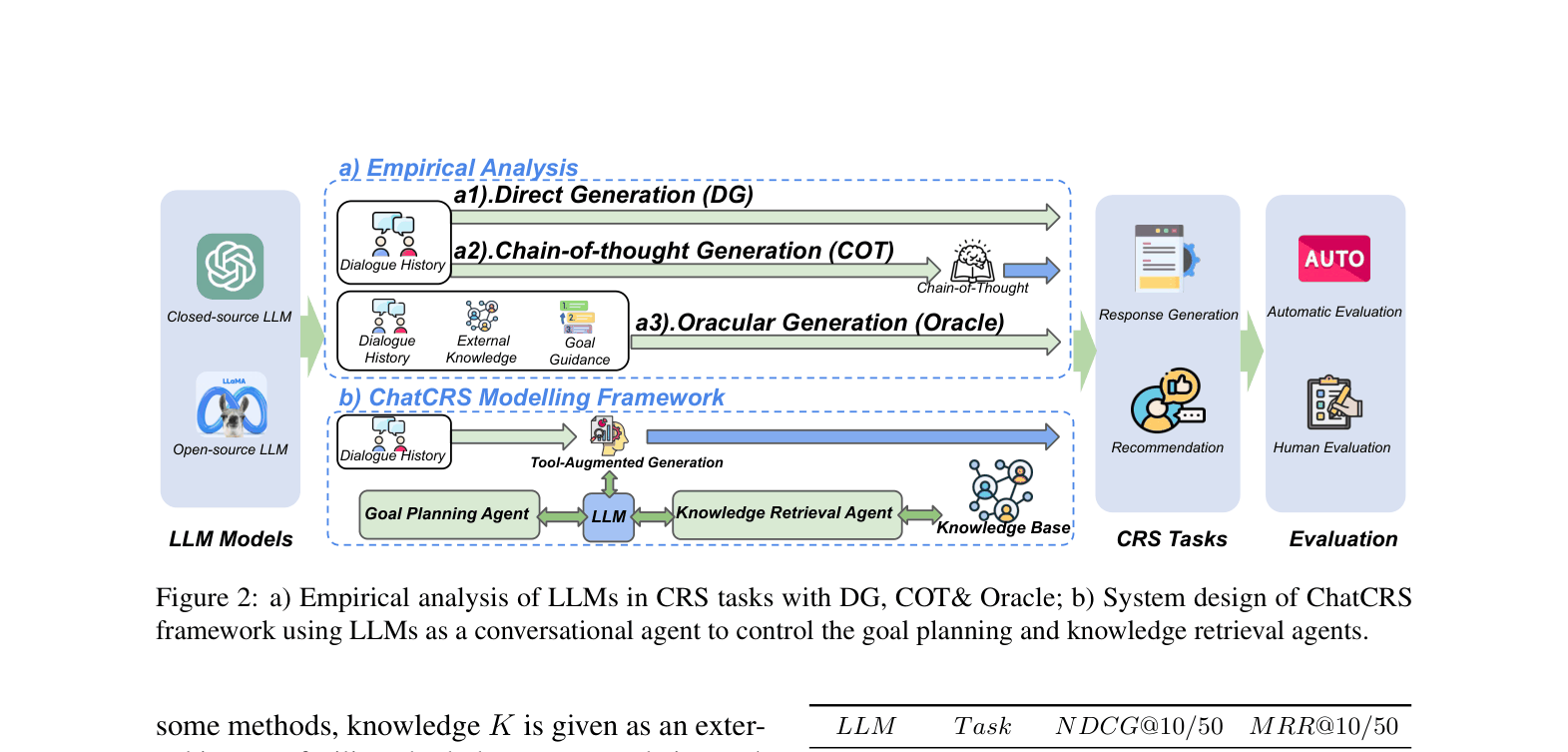
The ChatCRS framework structure showing the decomposition of the CRS task into sub-agents.
Evaluation Highlights
- Achieves a tenfold enhancement in recommendation accuracy (NDCG@1) on DuRecDial and TG-Redial compared to standard LLM baselines (ChatGPT, LLaMA)
- Improves CRS-specific language quality significantly: +17% in informativeness and +27% in proactivity over baselines in human evaluation
- Outperforms fully trained SOTA baselines (like UniMIND) in response generation metrics (BLEU, F1) while requiring no full-model fine-tuning for the main agent
Breakthrough Assessment
7/10
Strong engineering of a multi-agent system that addresses specific LLM weaknesses (knowledge, planning) in CRS. While the components (RAG, LoRA) are known, their specific orchestration for CRS yields massive empirical gains.