📝 Paper Summary
Explainability/Interpretability
Model Evaluation/Stress-testing
FIZLE leverages instruction-tuned LLMs to generate counterfactual text examples in a zero-shot manner for explaining and stress-testing black-box NLP classifiers without auxiliary training data.
Core Problem
Existing automated counterfactual generation methods are resource-intensive, requiring task-specific datasets, fine-tuning of auxiliary models, or expert human annotation, which is not scalable for new domains.
Why it matters:
- Black-box NLP models require careful stress-testing and explainability, especially in high-stakes deployments
- Collecting gold-standard counterfactual datasets for every new task is infeasible
- Current methods like Polyjuice require sentence-pair datasets for specific control codes, limiting flexibility
Concrete Example:
For the input 'This movie is great', a counterfactual explanation might be 'This movie is boring'. Existing methods might struggle to generate this without training on sentiment-flip pairs, whereas an LLM can infer the task from instructions alone.
Key Novelty
Framework for Instructed Zero-shot Counterfactual Generation with LanguagE Models (FIZLE)
- Utilizes the inherent instruction-following capabilities of off-the-shelf LLMs (like GPT-4 and Llama 3) to generate counterfactuals without any fine-tuning or few-shot examples
- Proposes a 'guided' prompting strategy where the LLM first identifies important features (words) responsible for a label, then edits them, acting as a two-step reasoning process
Architecture
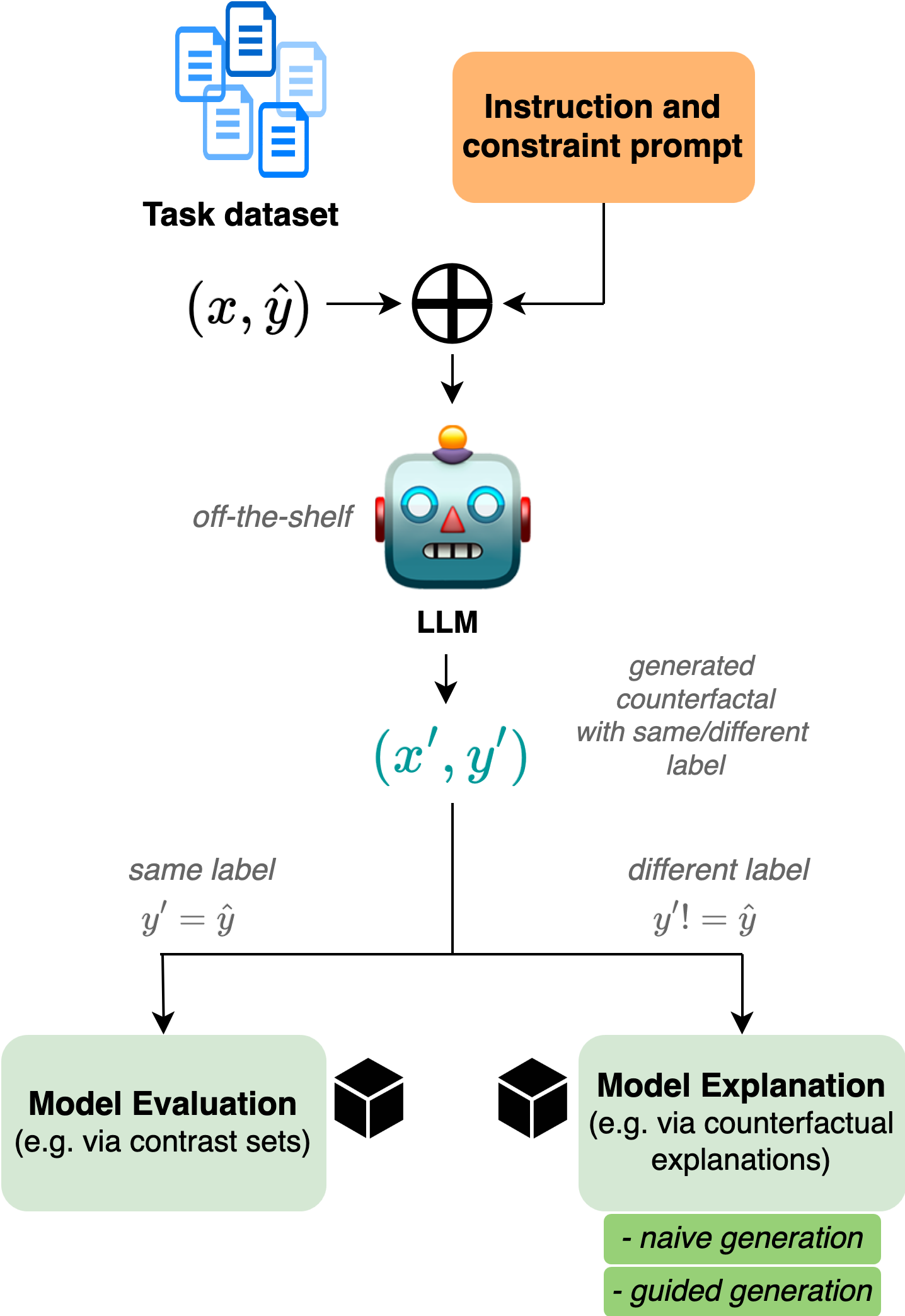
The workflow of the FIZLE framework, detailing the zero-shot prompting pipeline.
Evaluation Highlights
- GPT-4o achieves a Label Flip Score of 95% on IMDB in the naive zero-shot setting, significantly outperforming the Polyjuice baseline (89%) while maintaining reasonable textual similarity
- The proposed FIZLE-guided pipeline generally produces counterfactuals with higher semantic similarity to the original input compared to naive prompting, verifying the benefit of the two-step feature identification approach
- On the AG News dataset, GPT-4o-mini achieves a 96% Label Flip Score, surpassing the BAE baseline (66%) and CheckList (0%)
Breakthrough Assessment
7/10
Offers a strong practical contribution by demonstrating that zero-shot LLMs can replace complex, trained counterfactual generators. While the methodology is straightforward prompting, the rigorous benchmarking against established baselines validates its utility for low-resource settings.