📝 Paper Summary
LLM-based recommendation
Agentic AI
Sequential recommendation
ToolRec uses an LLM as a surrogate user to iteratively explore candidate items via attribute-specific ranking and retrieval tools, overcoming the 'narrow expert' limitations of traditional recommenders.
Core Problem
Conventional recommender systems (RSs) struggle to capture fine-grained preferences and lack commonsense knowledge, while existing LLM-based RSs suffer from hallucinations and misalignment between semantic and behavioral spaces.
Why it matters:
- Traditional RSs are 'narrow experts' limited by historical interaction data, missing the user's latent interests outside their history.
- Directly using LLMs for recommendation often leads to hallucinated items or poor alignment with the actual item catalog.
- Existing LLM controllers use simplistic strategies (rank vs. show) that lack human-like exploration and refinement logic.
Concrete Example:
A user watches 5 genre-specific movies. A standard RS suggests more of the same genre. ToolRec, acting as a surrogate user, notices a gap in 'release year,' invokes a retrieval tool for that specific year, then refines by 'actor,' iteratively building a more tailored list.
Key Novelty
LLM as a Surrogate User with Attribute-Oriented Tools
- Models the recommendation process as an iterative conversation where an LLM simulates the user's decision-making process (surrogate user) to actively explore item attributes.
- Introduces specialized attribute-oriented tools (ranking and retrieval) that allow the LLM to fetch real items based on specific criteria (e.g., 'rank by actor', 'retrieve by genre') rather than hallucinating them.
Architecture
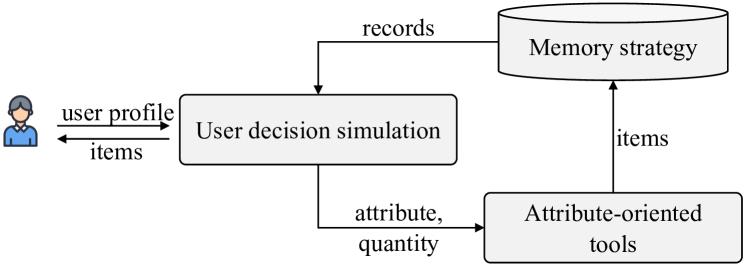
The overall framework of ToolRec, illustrating the interaction between the LLM-based surrogate user, the tool library, and the memory module.
Evaluation Highlights
- Outperforms state-of-the-art baselines (including SASRec and identifying LLM methods) across three real-world datasets (MovieLens-1M, Amazon-Beauty, Amazon-Sports) on HR@10 and NDCG@10.
- Achieves highest performance in semantic-rich domains like movies, significantly surpassing traditional ID-based models.
- Ablation studies confirm the necessity of both retrieval and ranking tools; removing either leads to performance degradation.
Breakthrough Assessment
7/10
Novel framework integrating tool learning with recommendation simulation. Addresses hallucination and 'narrow expert' issues effectively, though reliance on simulation prompts and specific attribute tools may limit generalization to non-attribute-rich domains.
