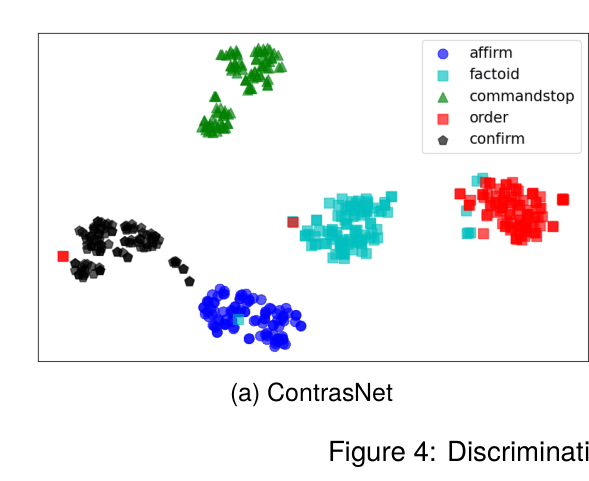
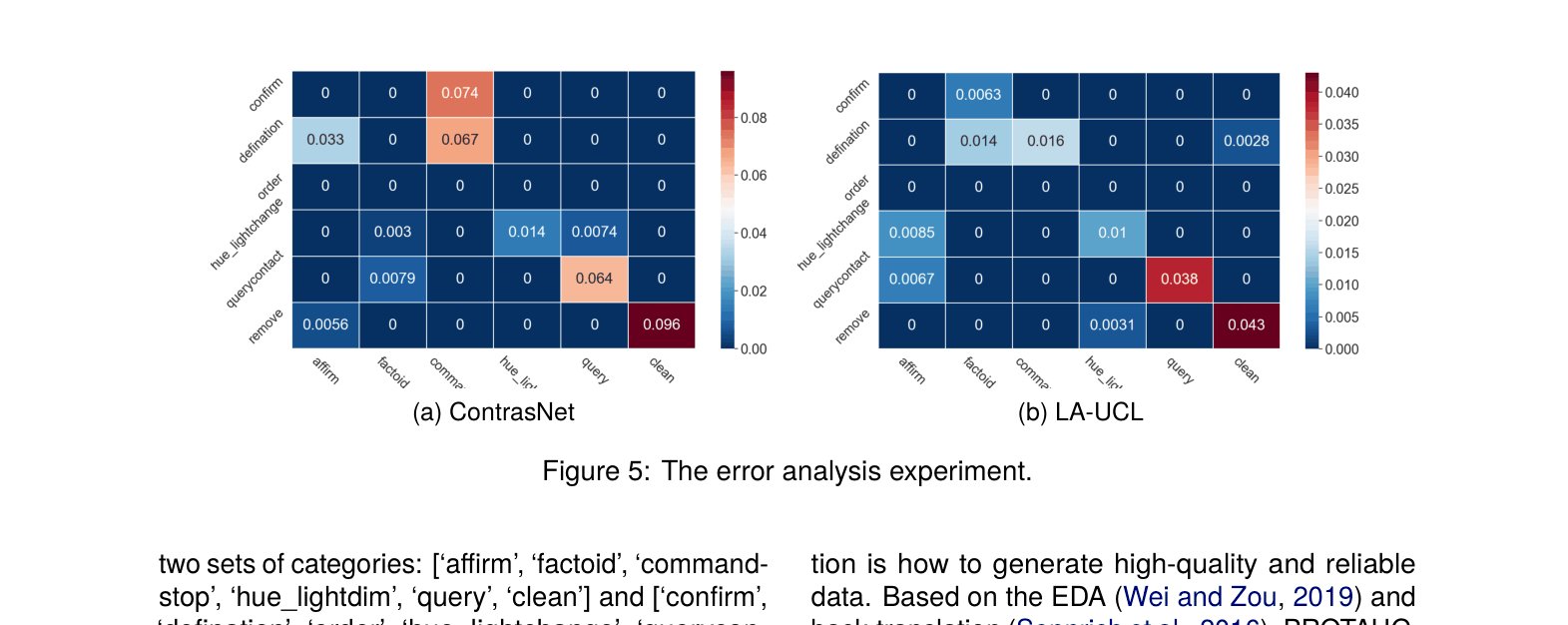
📝 Paper Summary
Data Augmentation for Few-Shot Learning
Contrastive Learning
LA-UCL enhances few-shot text classification by using retrieval-guided LLMs to generate diverse augmented samples and optimizing them via novel group-level and sample-level unsupervised contrastive losses.
Core Problem
Few-shot text classification suffers from overfitting and poor class discrimination because existing data augmentation methods (like simple paraphrasing) lack diversity and cognitive ability.
Why it matters:
- Traditional augmentation models generate samples too similar to the original, failing to expand the feature space effectively
- Lack of diversity in augmented data exacerbates overfitting in low-resource settings
- Models struggle to distinguish between semantically similar classes without richer, more discriminative training signals
Concrete Example:
When augmenting the question 'Who is the Prime Minister of Russia?', traditional models produce repetitive variants like 'Is Vladimir Putin a prime minister?'. In contrast, a retrieval-augmented LLM can generate diverse, high-quality variants by leveraging external knowledge, preventing the model from overfitting to simple surface patterns.
Key Novelty
Retrieval-Guided LLM Augmentation with Dual Contrastive Losses
- Uses retrieval-based in-context prompts to guide an LLM (ChatGPT) in generating data. For labeled data, it retrieves similar negative samples to force the LLM to generate *discriminative* positives (avoiding confusion).
- For unlabeled data, it retrieves external web knowledge to help the LLM generate *diverse* and accurate paraphrases, expanding the semantic space.
- Introduces two specific unsupervised contrastive losses: Group-Level (interacts with base classes to improve discrimination) and Sample-Level (pulls diverse augmentations of the same sample together to reduce overfitting).
Architecture
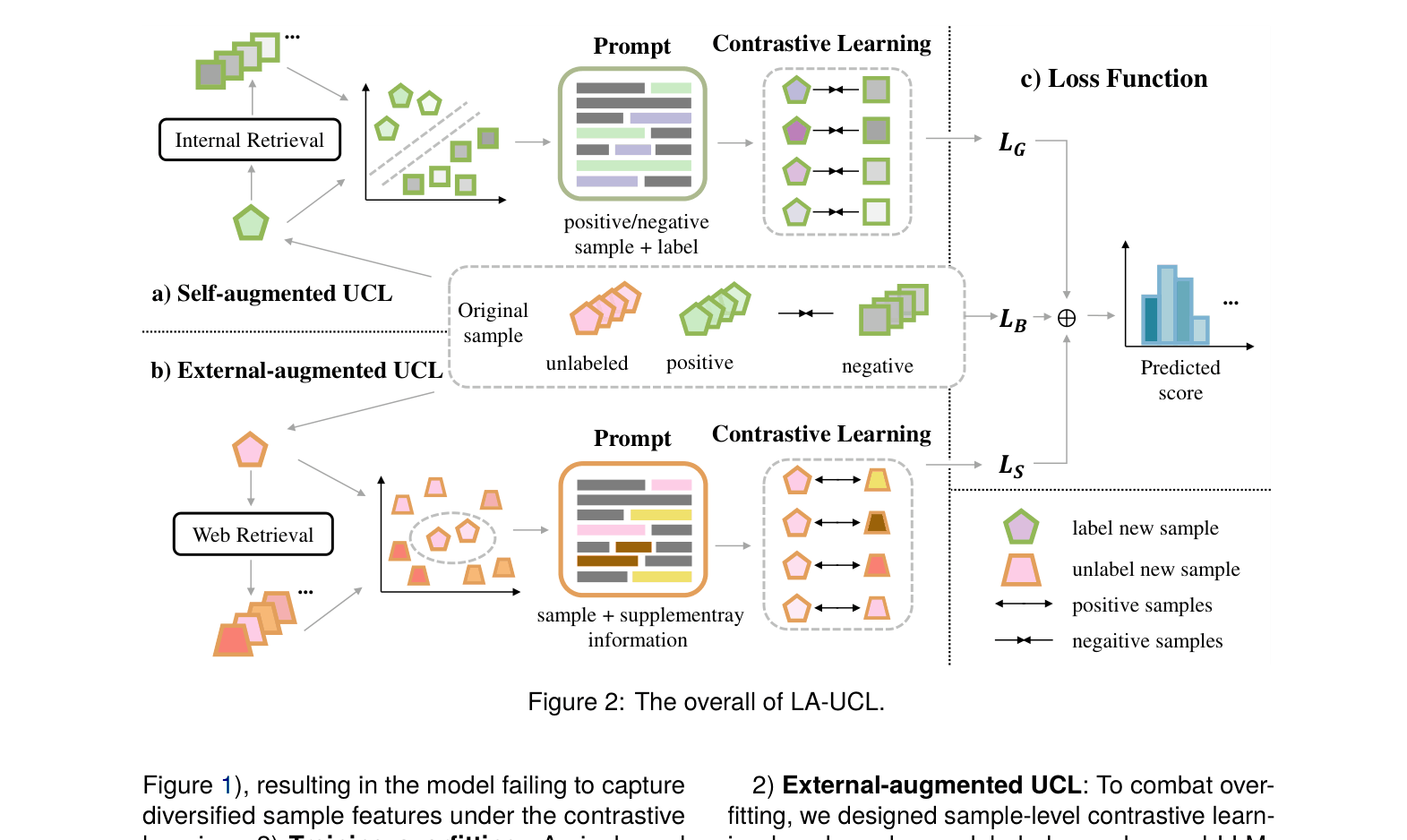
The overall LA-UCL framework, illustrating the two data augmentation strategies (Self-augmented and External-augmented) and the corresponding contrastive learning losses.
Evaluation Highlights
- Outperforms ContrastNet by +1.59% in 5-shot setting on HWU64 dataset
- Achieves +22.09% improvement over MLADA on HuffPost 1-shot classification
- Surpasses state-of-the-art ContrastNet by +3.54% on HuffPost 1-shot setting
Breakthrough Assessment
7/10
Solid combination of LLM generation and contrastive learning. The retrieval-guided prompting to fix specific augmentation weaknesses (discrimination vs. diversity) is clever, though the underlying components (CL + LLM aug) are established concepts.