📝 Paper Summary
Vision-Language Alignment
Hallucination Mitigation
Preference Optimization
SIMA enables Large Vision Language Models to self-improve alignment by generating their own responses and critiquing them using specific visual metrics, eliminating reliance on external models or human data.
Core Problem
Existing alignment methods for Large Vision Language Models (LVLMs) rely on external models or human-labeled data, which introduces distribution shifts, high costs, and potential hallucinations from the external supervisor.
Why it matters:
- External LVLMs used for supervision may have their own hallucinations that do not reflect the target model's behavior, leading to unstable optimization.
- Dependence on human-labeled data or proprietary APIs (like GPT-4V) is expensive and hinders scaling in resource-constrained environments.
Concrete Example:
A common method (POVID) uses an external model to deliberately inject object hallucinations into ground truth answers to create negative samples. However, these artificial hallucinations may not match the specific errors the target model actually makes, making the negative signal less effective for learning.
Key Novelty
Self-Improvement Modality Alignment (SIMA)
- Self-generates response pairs (using greedy vs. temperature sampling) from the model's own distribution, ensuring the negative samples reflect its actual error modes.
- Uses an in-context self-critic mechanism where the model acts as its own judge, guided by three specific visual accuracy metrics (objects, relationships, attributes) in the prompt.
- Performs Direct Preference Optimization (DPO) on these self-generated, self-ranked pairs without needing any external reward model or human feedback.
Architecture
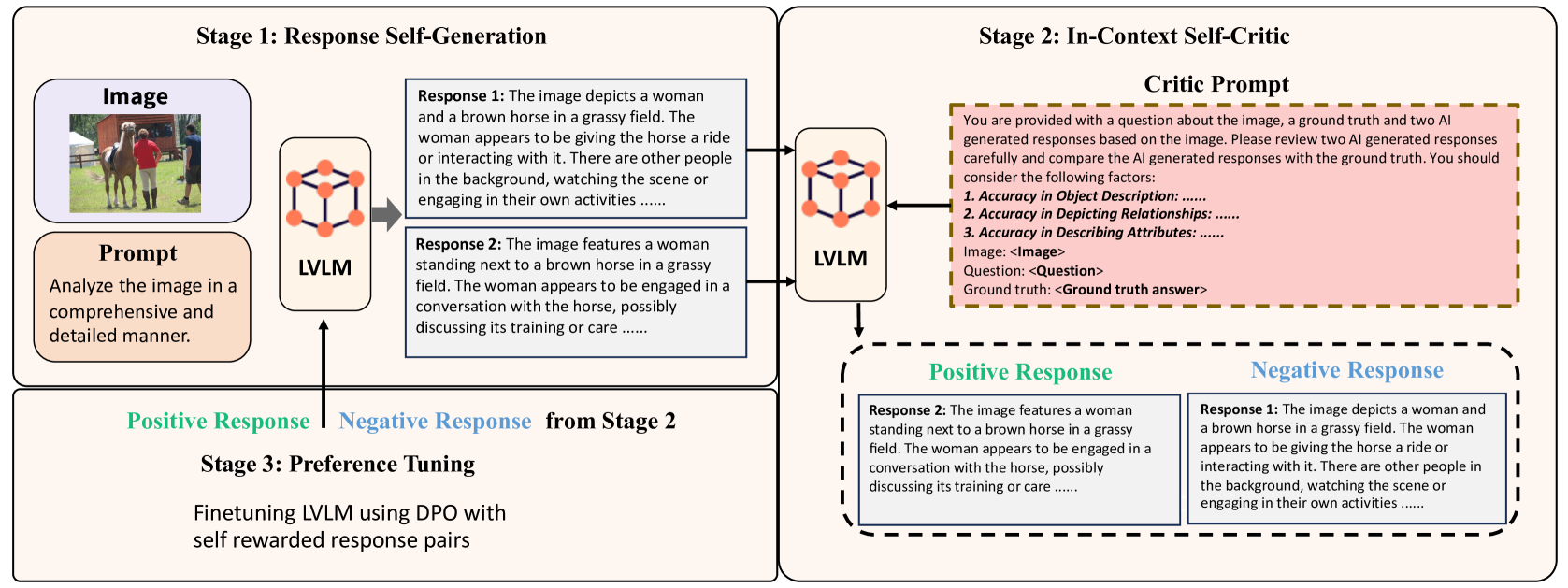
The 3-stage pipeline of SIMA: Response Self-generation, In-context Self-critic, and Preference Tuning.
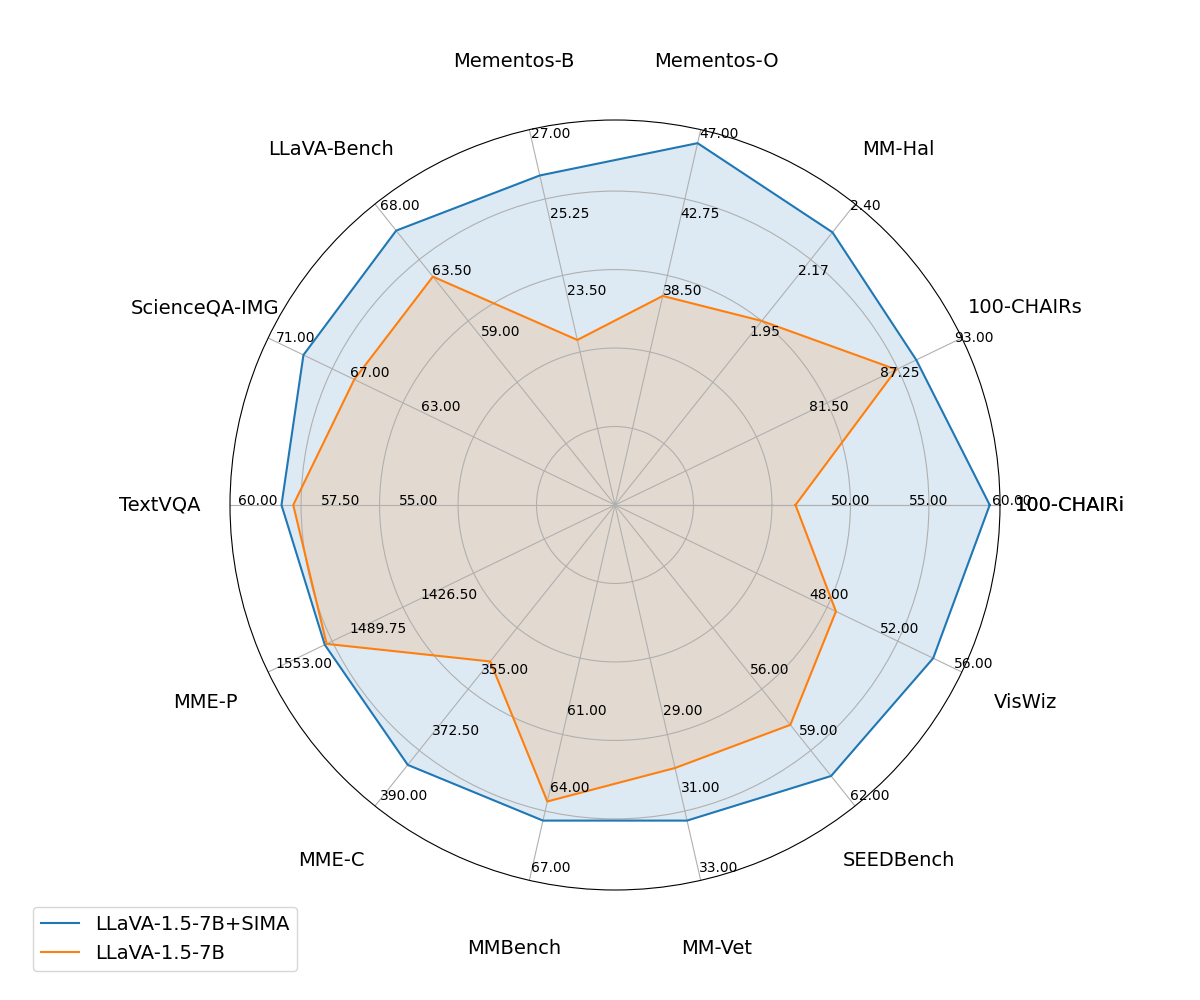
Evaluation Highlights
- Reduces object hallucination (CHAIR score) by 16.1% on LLaVA-1.5-7B compared to the base model.
- Improves performance on the MM-Hal benchmark by 12.7% for LLaVA-1.5-7B, outperforming external-feedback baselines like LLaVA-RLHF and POVID.
- Achieves a 13.1% improvement on Mementos-Behavior, demonstrating that reducing object hallucinations also helps correct behavioral misunderstandings in sequential image tasks.
Breakthrough Assessment
7/10
Strong methodological contribution by showing LVLMs can self-correct without external supervisors. The performance gains on hallucination benchmarks are significant, though it primarily refines existing architectures rather than proposing a new model class.