📝 Paper Summary
Reinforcement Learning from AI Feedback (RLAIF)
Preference Data Construction
UltraFeedback is a large-scale, fine-grained AI feedback dataset that enables open-source models to surpass commercial baselines via reward modeling and RLAIF, without relying on human annotation.
Core Problem
Acquiring high-quality human feedback for LLM alignment is slow, expensive, and limited in scale, preventing open-source models from matching proprietary models like ChatGPT.
Why it matters:
- Existing open-source preference datasets are either small (Wu et al., 2023) or domain-limited (Stiennon et al., 2020), hindering effective feedback learning
- Reliance on human annotators bottlenecks the scalability and diversity of alignment data needed for general-purpose chat models
- Prior AI feedback methods (Constitution AI) were often limited to specific domains or lacked diversity in instructions and model responses
Concrete Example:
In standard human feedback collection, annotators might inconsistently rate a safe but unhelpful response versus a helpful but unsafe one due to subjective bias. UltraFeedback solves this by decomposing ratings into four distinct aspects (Helpfulness, Honesty, Truthfulness, Instruction-following) and providing GPT-4 with explicit rubrics to score 4 different model outputs simultaneously.
Key Novelty
Scaled, Multi-Aspect AI Feedback
- Construct a massive dataset (250k sessions) by sampling 17 different LLMs (from LLaMA to GPT-4) to generate diverse responses to complex instructions
- Use GPT-4 as a judge with a 'Chain-of-Thought' critique method, evaluating responses on four separate axes (Instruction-following, Truthfulness, Honesty, Helpfulness) rather than a single vague preference score
Architecture
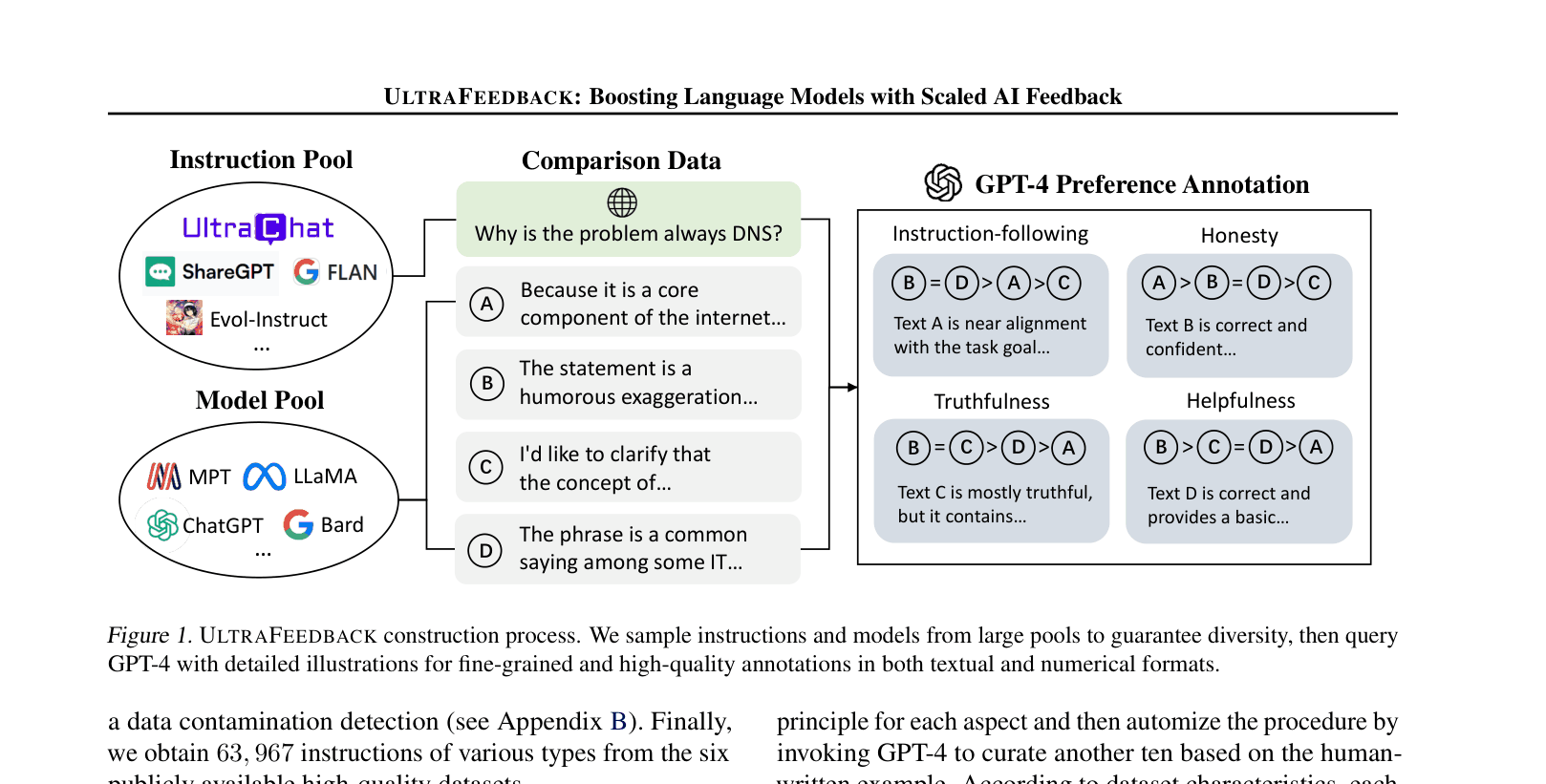
The data construction pipeline: Instruction Pool selection, Model Pool completion sampling, and GPT-4 Preference Annotation.
Evaluation Highlights
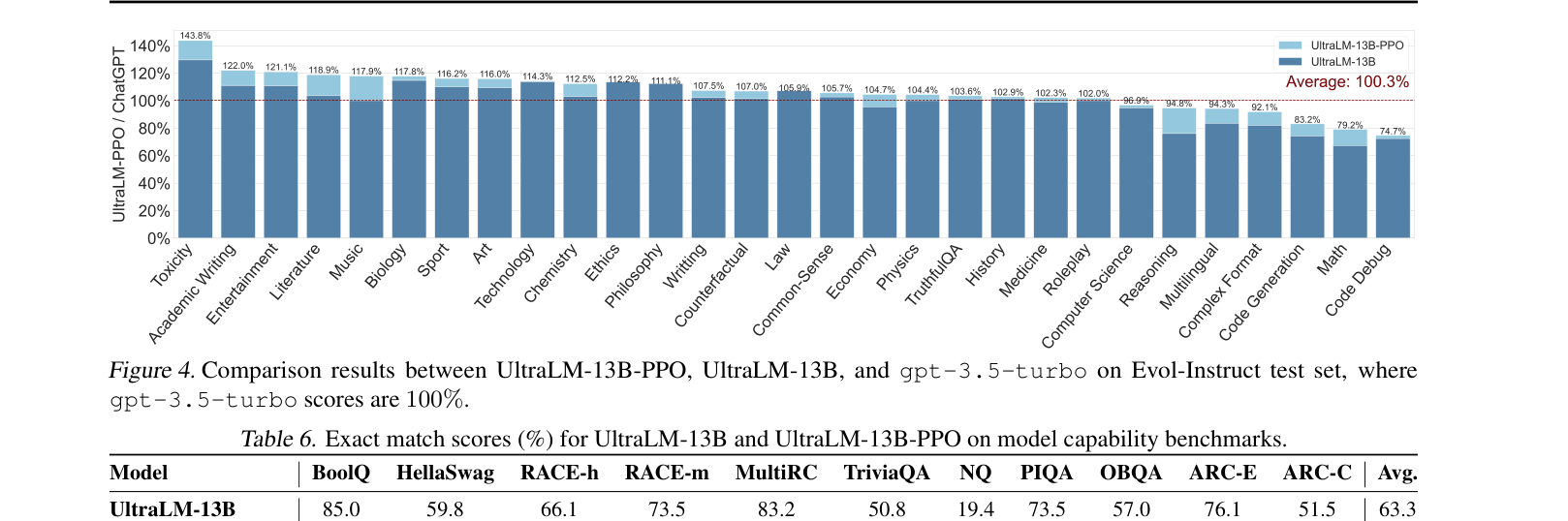
- UltraLM-13B-PPO achieves the highest average win rate against text-davinci-003/ChatGPT on AlpacaEval, Evol-Instruct, and UltraChat, outperforming LLaMA2-70B-Chat
- UltraRM (13B) achieves 71.0% average accuracy on four preference benchmarks, surpassing all open-source baselines including LLaMA-7B based models
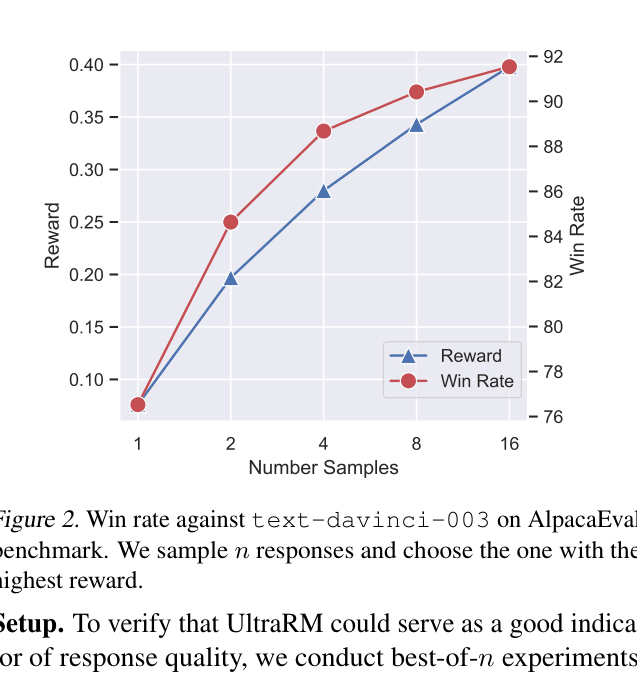
- Best-of-16 sampling with UltraRM boosts UltraLM-13B win rate from 76.53% to 91.54% on AlpacaEval
Breakthrough Assessment
9/10
Establishes a new standard for open-source alignment data. The dataset size (1M+ annotations) and the resulting model performance (beating LLaMA2-70B with a 13B model) demonstrate the viability of purely AI-driven alignment at scale.