📝 Paper Summary
Modularized RAG pipeline
Robustness to retrieval noise
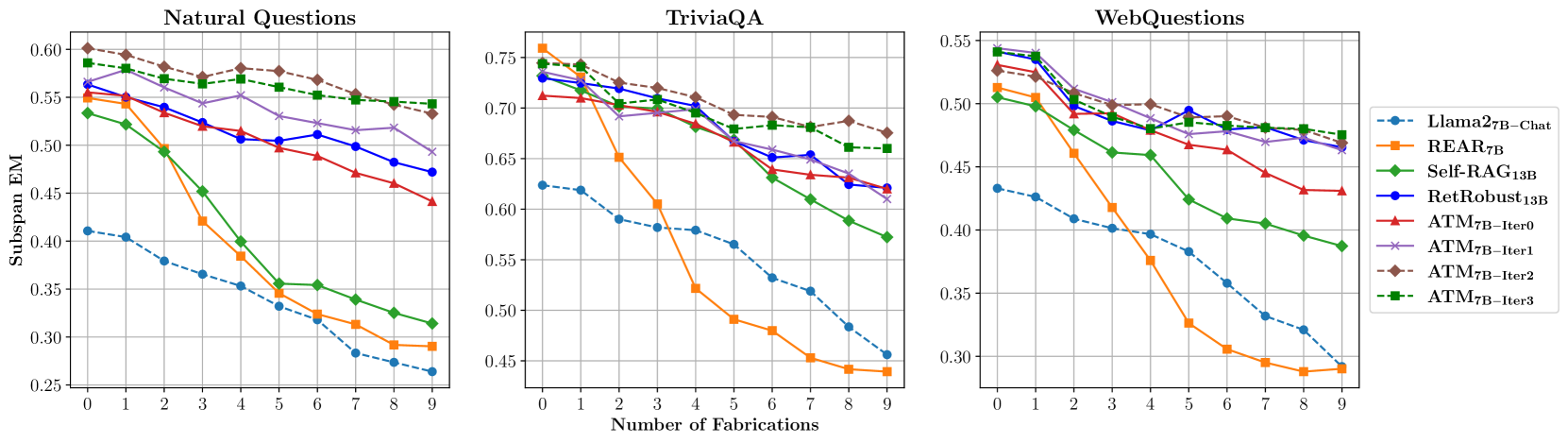
ATM improves RAG robustness by co-training a Generator to resist noise and an Attacker that learns to fabricate convincing fake documents and permute list orders.
Core Problem
Retrieval-Augmented Generation (RAG) systems are vulnerable to noisy, irrelevant, or fabricated content in retrieved documents, causing the generator to produce hallucinations or incorrect answers.
Why it matters:
- Internet content is flooded with noise and fabrications, making high-precision retrieval difficult in real-world scenarios
- LLMs tend to blindly trust retrieved context, leading to 'hallucinations' when that context is flawed or malicious
- Existing RAG methods often assume retrieved documents are mostly clean or relevant, failing when exposed to adversarial or low-quality retrieval results
Concrete Example:
When asking 'Who is the CEO of Twitter?', if a retrieved document falsely claims 'Elon Musk stepped down in 2022', a standard RAG model might repeat this error. ATM trains the generator to ignore such fabrications and rely on correct documents or internal knowledge.
Key Novelty
Adversarial Tuning Multi-agent System (ATM)
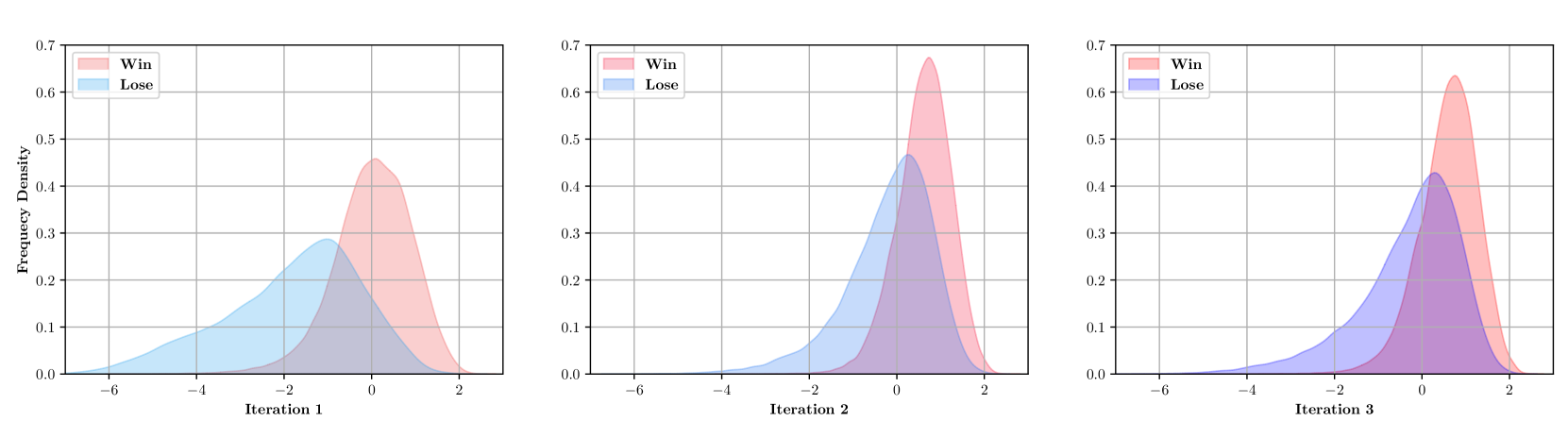
- Uses a multi-agent game where an 'Attacker' agent generates fake documents and shuffles lists to mislead the system, while the 'Generator' agent learns to ignore them.
- Introduces 'Multi-agent Iterative Tuning Optimization' (MITO) where the Attacker is aligned via DPO to maximize Generator perplexity on correct answers, and the Generator minimizes loss on attacked data.
Architecture
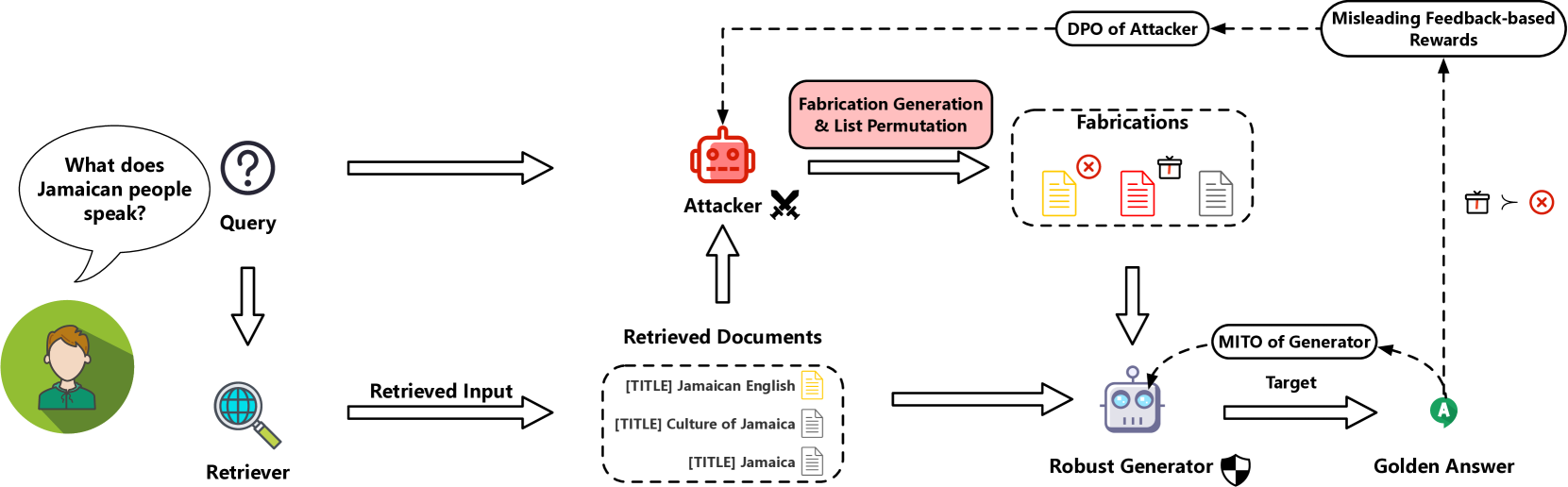
Overview of the ATM optimization process. The Attacker generates fabrications and permutes lists based on feedback (Generator PPL). The Generator is optimized using MITO loss (SFT + KL) on the attacked lists.
Evaluation Highlights
- +6.15% Exact Match improvement on Natural Questions compared to state-of-the-art baselines like RetRobust and Self-RAG using Llama-2-7B.
- Achieves higher robustness against fabrications generated by diverse LLMs (Mixtral-8x7B, Llama-3-70B), maintaining performance even as noise increases.
- Outperforms baselines on unseen datasets (PopQA) and unseen fabricator models, demonstrating generalization beyond the training distribution.
Breakthrough Assessment
7/10
Novel application of multi-agent adversarial feedback to RAG robustness. Strong empirical gains against solid baselines, though primarily an incremental combination of known techniques (DPO, adversarial training).