📝 Paper Summary
Agentic RAG pipeline
Reinforcement Learning for Agents
DynaSearcher enhances search agents by integrating dynamic knowledge graph retrieval to guide reasoning paths and using multi-reward reinforcement learning to balance accuracy, efficiency, and response quality.
Core Problem
Current search agents rely on unstructured text and coarse outcome-based rewards, leading to noisy intermediate queries, inefficient search trajectories, and hallucinations during complex reasoning.
Why it matters:
- Reliability on static parametric knowledge causes hallucinations in LLMs, while standard RAG struggles with complex multi-hop questions
- Existing prompt-based agents (like ReAct or CoT) are sensitive to prompt formulation and fail to fully exploit agentic potential
- Current RL-based search agents use coarse global rewards that fail to provide fine-grained guidance for intermediate steps, leading to redundant computations
Concrete Example:
In a multi-hop question about two entities, a standard search agent might retrieve irrelevant documents due to keyword matching noise, diverting the reasoning path. DynaSearcher uses a knowledge graph to explicitly model the relationship between the entities, ensuring the intermediate query targets the correct connecting fact.
Key Novelty
Dynamic Knowledge Graph Augmented Multi-Reward RL
- Integrates structured Knowledge Graphs (Wikidata) alongside document search to explicitly model entity relationships, guiding the agent away from noisy text and towards factually consistent queries
- Deploys a multi-reward RL framework (accuracy + information gain + penalty) that specifically rewards high-quality intermediate queries while penalizing redundant or excessive search steps
Architecture
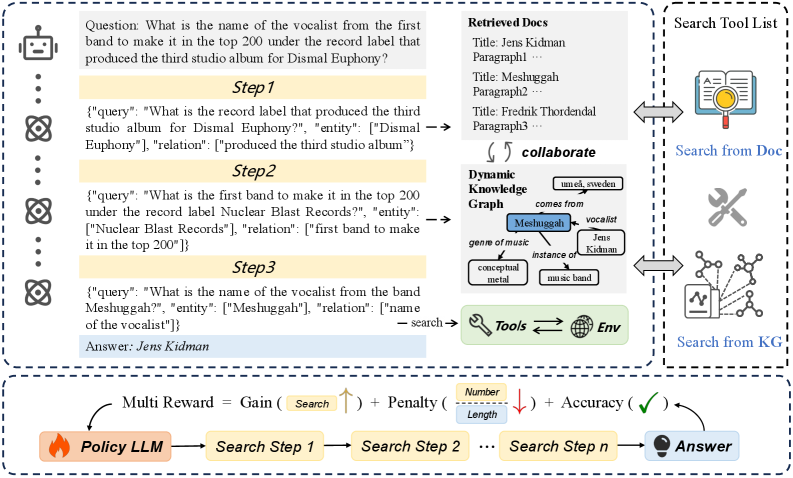
Overview of the DynaSearcher framework, detailing the iterative loop of reasoning, planning, and dual-retrieval (Document + Knowledge Graph).
Evaluation Highlights
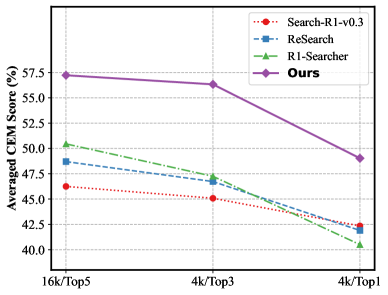
- +4.0 F1 improvement on HotpotQA (multi-hop) compared to Search-R1-v0.3 baseline using Qwen2.5-7B
- Outperforms GPT-4.1 on HotpotQA (66.1 F1 vs 60.6 F1) using a much smaller Qwen2.5-7B base model
- Achieves state-of-the-art results across six datasets (including 2Wiki, Musique, Bamboogle) compared to strong baselines like DeepSeek-R1 and ReSearch
Breakthrough Assessment
8/10
Significant performance jumps on complex reasoning tasks using small models (7B) by effectively combining structured knowledge (KG) with fine-grained RL incentives, outperforming much larger frontier models.