📝 Paper Summary
RAG analysis
Knowledge Fusion
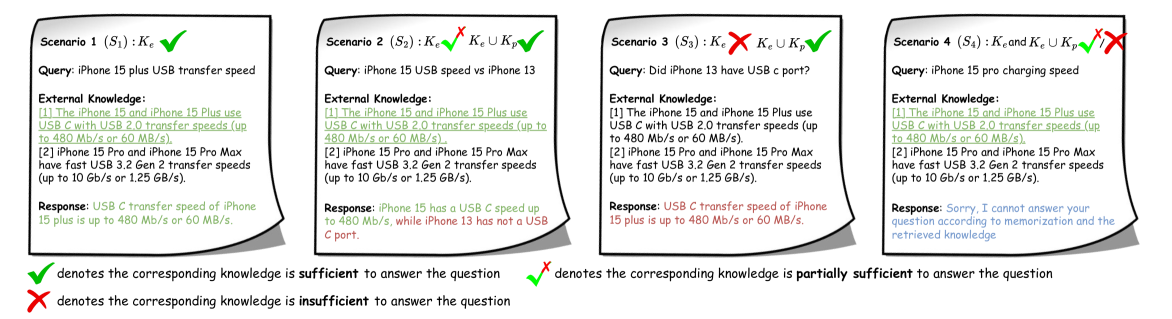
The paper constructs a controlled evaluation pipeline to analyze how LLMs fuse internal parametric memory with external retrieved evidence across four distinct scenarios of knowledge sufficiency and conflict.
Core Problem
Current RAG evaluations often assume external knowledge is perfect or irrelevant, neglecting complex scenarios where external evidence is partial, noisy, or complementary to the LLM's internal memory.
Why it matters:
- External retrieval in real-world applications is often incomplete or noisy, requiring models to intelligently fill gaps with internal knowledge
- Over-reliance on external knowledge (a common RAG behavior) can suppress valuable internal knowledge, leading to failures when retrieval is sub-optimal
- Existing studies struggle to fairly evaluate 'parametric knowledge' because it varies wildly between models and is hard to measure precisely
Concrete Example:
If a user asks about a phone's camera specs, and the retrieval provides the pixel count but misses the sensor type (which the model knows from training), a standard RAG model might ignore its internal knowledge and give an incomplete answer based only on the retrieved text.
Key Novelty
Systematic Knowledge Fusion Evaluation Pipeline
- Defines four explicit fusion scenarios (S1-S4) based on the sufficiency of external vs. internal knowledge (e.g., partial external info requires internal supplementation)
- Constructs a controlled dataset by injecting specific 'outdated' knowledge into models via fine-tuning (simulating parametric memory) and using 'latest' data as external evidence
- Isolates the variable of 'parametric knowledge' by training models on the specific facts needed for evaluation, ensuring a fair baseline for fusion capability
Architecture
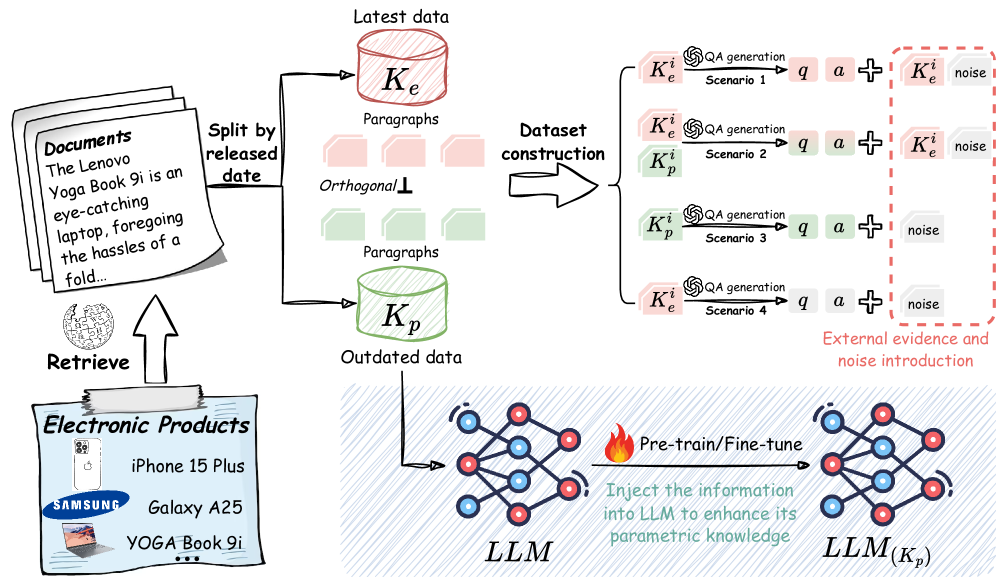
The systematic pipeline for data construction and knowledge infusion.
Evaluation Highlights
- Integrating external and parametric knowledge significantly boosts performance: Accuracy improves from ~37% (parametric only) to ~93% (fusion) in optimal scenarios (S1) for ChatGLM3-6B
- LLMs struggle with partial information (S2): Accuracy drops significantly (e.g., to ~45% for Qwen-7B) when external evidence is incomplete and requires internal supplementation compared to full evidence
- Knowledge retention heavily impacts fusion: Models with poor fine-tuning retention of parametric knowledge show drastic performance drops in fusion tasks, with ChatGLM3-6B showing higher retention and better fusion than Qwen-7B
Breakthrough Assessment
7/10
Provides a rigorous, much-needed framework for evaluating RAG beyond simple 'retrieval accuracy.' The methodology of injecting parametric knowledge to control variables is clever, though the scope is limited to specific domains.