📝 Paper Summary
Visual Instruction Tuning
Text-Rich Image Understanding
Optical Character Recognition (OCR)
TRINS is a large-scale instruction-tuning dataset for text-rich images created via semi-automatic annotation, paired with a new model architecture (LaRA) that explicitly incorporates OCR tokens.
Core Problem
Existing large multimodal models struggle to comprehend textual content embedded within images (like posters or book covers) due to a lack of high-quality text-rich training data and low-resolution visual encoders.
Why it matters:
- Current datasets like COCO and Conceptual Captions focus on natural images, leaving models unable to read or reason about text in real-world scenarios
- Low-resolution visual encoders (e.g., CLIP) often fail to resolve small text, creating a bottleneck for document understanding tasks
- Existing OCR-based VQA datasets lack the detailed instruction-following annotations needed to train general-purpose multimodal assistants
Concrete Example:
When asked to summarize a book cover, standard multimodal models might describe the visual layout but fail to read the title or author correctly, whereas models trained on TRINS can extract and reason about the text.
Key Novelty
Semi-automatic Text-Rich Dataset Construction & OCR-Augmented Architecture
- Creates a dataset (TRINS) by filtering LAION for text-rich images, using human annotators for detailed captions, and prompting GPT-4 with OCR/caption data to generate complex QA pairs
- Proposes LaRA (Language-vision Reading Assistant), which bypasses visual encoder resolution limits by explicitly feeding OCR-extracted text tokens directly into the LLM alongside visual features
Architecture
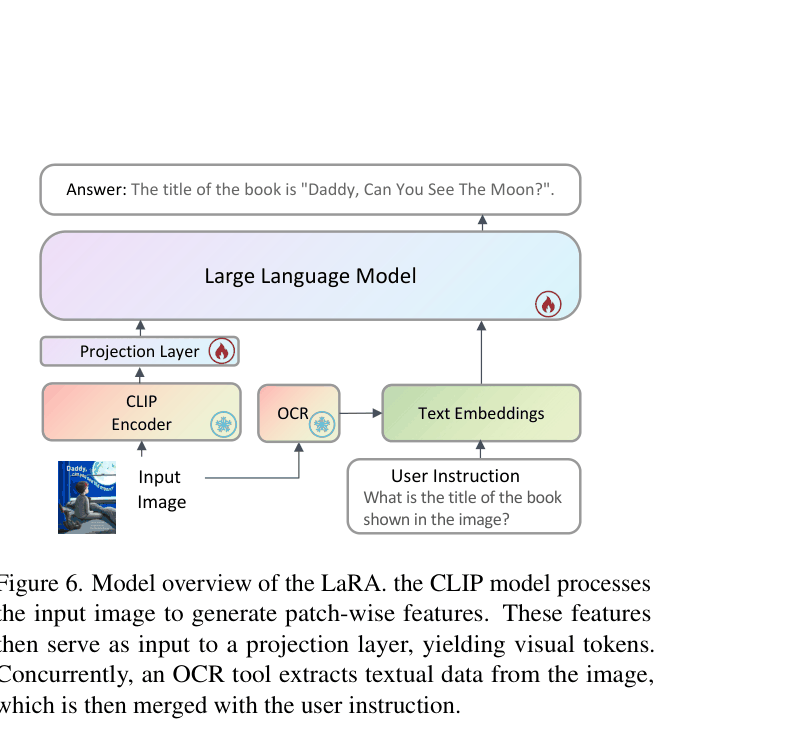
Overview of the LaRA model architecture.
Evaluation Highlights
- +202 point improvement on OCRBench score (548 vs 346) compared to the LLaVAR baseline
- Achieves 62.8% accuracy on TRINS-VQA Extract questions, outperforming LLaVA 1.5 (38.8%) by a significant margin
- Outperforms InstructBLIP and Qwen-VL on text-rich image captioning metrics (e.g., 186.6 CIDEr vs 23.5 and 79.4 respectively) on the TRINS-VQA Abstract benchmark
Breakthrough Assessment
8/10
Significant contribution to the specific sub-field of text-rich image understanding. The dataset construction pipeline is robust, and the simple OCR-injection architecture sets a strong baseline for reading-capable multimodal models.