📝 Paper Summary
Conversational personalization
Knowledge internalization
KGT personalizes LLMs by modifying an external knowledge graph based on user feedback during inference, maximizing the probability of retrieving and reasoning over personalized facts without updating model parameters.
Core Problem
Existing personalization methods like parameter-efficient fine-tuning or knowledge editing require computationally expensive back-propagation and lack interpretability, making real-time adaptation to extensive personalized knowledge difficult.
Why it matters:
- Back-propagation incurs high GPU memory and computational costs unacceptable for daily on-device LLM use
- Directly modifying model parameters can cause 'catastrophic forgetting' or corruption, adversely affecting responses to unrelated queries
- In-context learning becomes inefficient and unscalable as the context length increases with accumulated personalized knowledge
Concrete Example:
If a user tells an LLM 'My dog is vegetarian', parameter-based methods might overfit or damage general knowledge about dogs. KGT simply deletes the triple (Dog, Enjoy, Meat) and adds (Dog, Enjoy, Vegetable) to the user's graph, allowing the model to retrieve this specific fact for future planning without retraining.
Key Novelty
Optimization of Knowledge Graphs via Evidence Lower Bound (ELBO) Maximization
- Treats personalization as optimizing the structure of an external knowledge graph (KG) rather than the LLM's weights
- Uses a heuristic algorithm to iteratively add relevant personalized triples and remove conflicting ones until the model's reasoning probability for the correct answer is maximized
Architecture
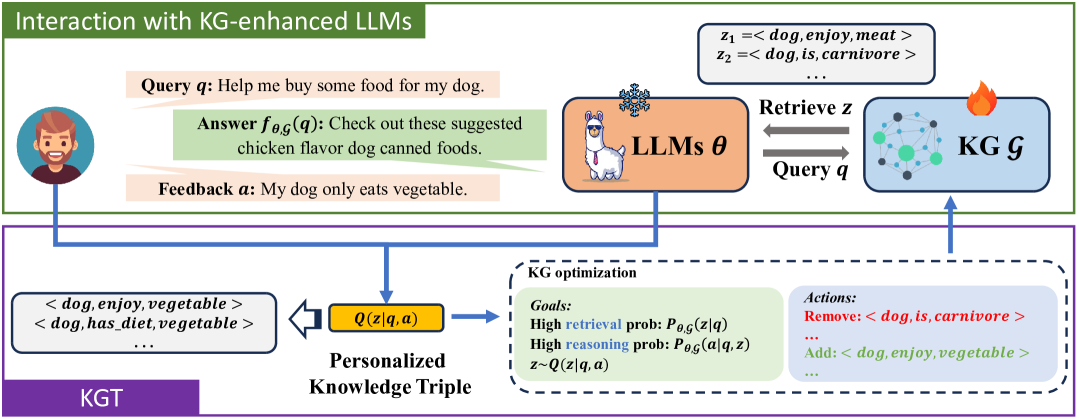
The KGT framework workflow showing the interaction between User, LLM, and Knowledge Graph.
Evaluation Highlights
- Reduces inference latency by up to 84% compared to parameter-based tuning methods like LoRA
- Cuts GPU memory costs by up to 77% compared to gradient-based approaches
- Outperforms GPT-2 and Llama-2 baselines in personalization accuracy while maintaining interpretability through explicit graph edits
Breakthrough Assessment
7/10
Offers a highly efficient, interpretable alternative to fine-tuning for personalization. While it relies on existing retrieval mechanisms, the formulation of graph editing as an ELBO optimization problem is a clever, practical shift.