📝 Paper Summary
Modularized RAG pipeline
Hallucination suppression
A training-free decoding method that weights retrieved documents by their entropy (uncertainty) and contrasts this against the model's internal parametric knowledge to prioritize factual external information.
Core Problem
RAG systems suffer from distractibility: irrelevant retrieved documents ('lost in the middle') confuse the model, and internal parametric knowledge often overrides correct external evidence during generation.
Why it matters:
- LLMs frequently halluncinate or produce outdated information despite having access to correct retrieved documents
- Current methods to fix this require expensive fine-tuning or training, which is impractical in resource-constrained environments
- Naive RAG concatenation fails when the correct document is buried in the middle of retrieved distractors
Concrete Example:
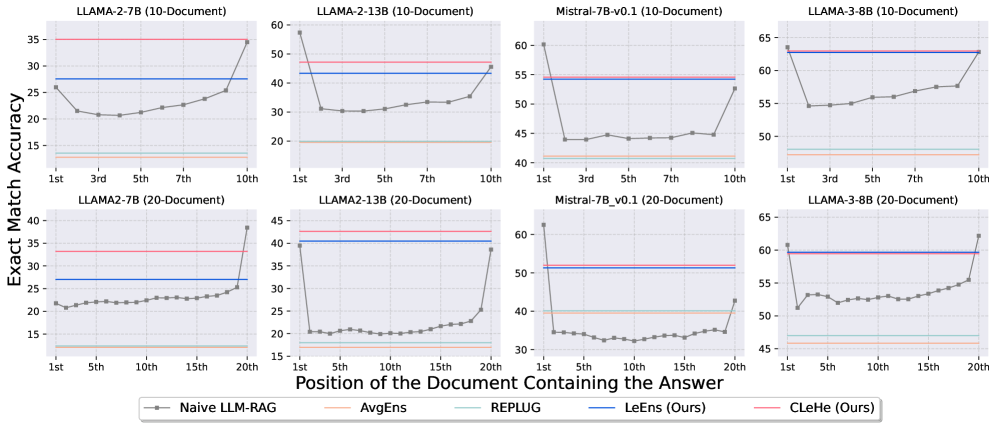
In a 'lost in the middle' scenario where the correct answer document is surrounded by distracting documents, a standard LLM often fails to generate the correct answer. The paper shows naive RAG performance drops significantly unless the oracle document is at the very start or end.
Key Novelty
Entropy-Based Decoding (CLeHe)
- Uses 'Low-entropy Ensemble' (LeEns) to weight retrieved documents: if a document makes the LLM less uncertain (lower entropy) about the next token, it gets a higher vote
- Applies 'Contrastive Decoding' by subtracting the logits of a high-entropy internal layer (representing ambiguous parametric knowledge) from the ensemble logits to suppress hallucinations
Architecture

The CLeHe pipeline: Parallel processing of retrieved documents, entropy-based weighting, and contrastive decoding against internal knowledge.
Evaluation Highlights
- Surpasses Naive RAG by significant margins across Llama-2 (7B/13B), Mistral-7B, and Llama-3-8B on NQ, TriviaQA, WebQ, and PopQA
- Achieves robust performance in 'lost in the middle' synthetic tests where naive concatenation fails completely when the oracle document is not at the edges
- Outperforms RePlug (a retriever-score-based ensemble baseline) in almost all settings, proving that model uncertainty is a better signal than retrieval scores
Breakthrough Assessment
7/10
Strong practical contribution for training-free RAG improvement. Effectively addresses both retrieval noise and parametric memory conflict without requiring any model updates, though the scope is limited to decoding time.