📝 Paper Summary
Iterative Retrieval-Augmented Generation (Iterative RAG)
LLM Serving Optimization
Speculative Decoding
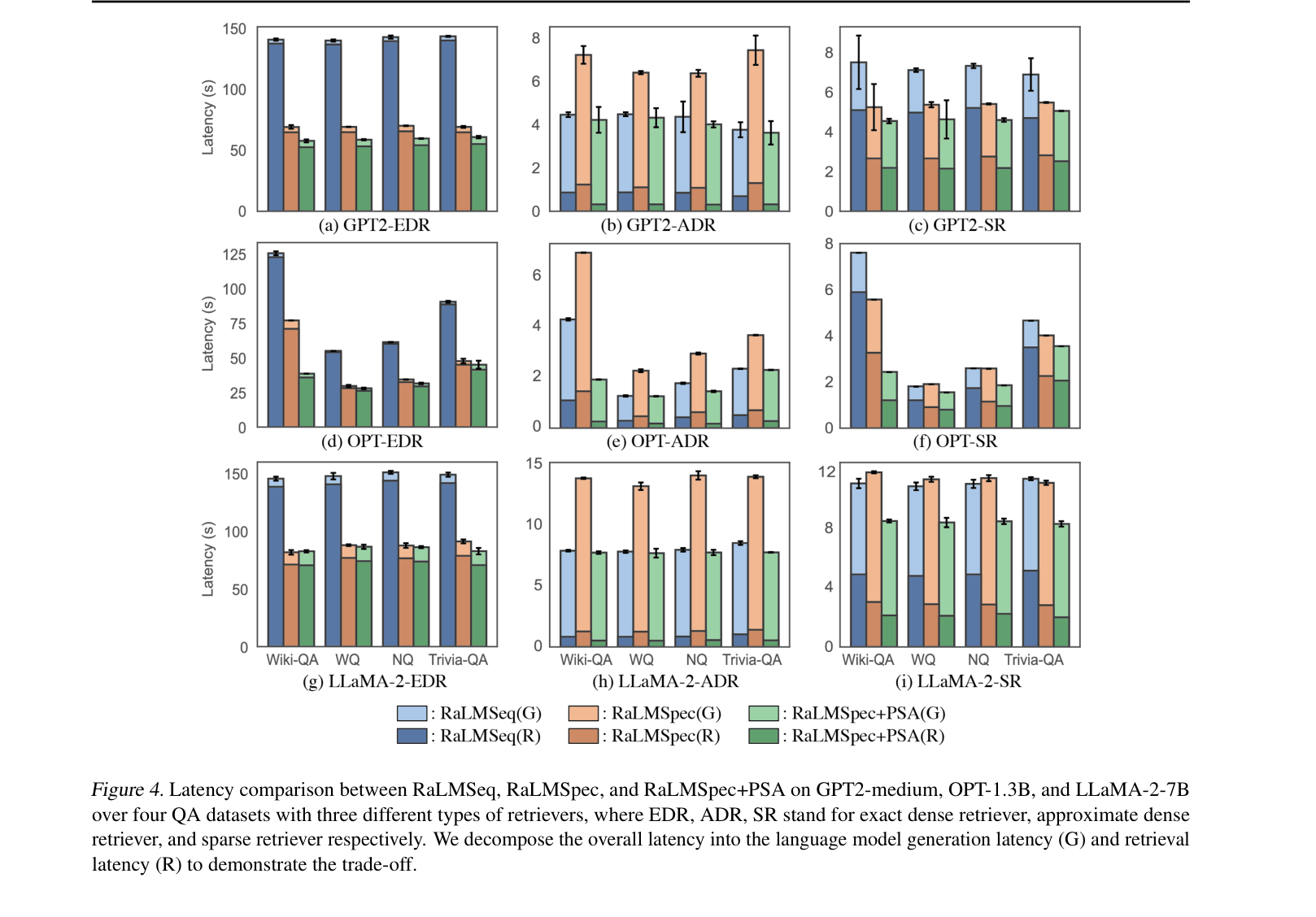
RaLMSpec accelerates iterative retrieval-augmented language models by speculatively retrieving from a local cache and verifying correctness via efficient batched queries to the external knowledge base.
Core Problem
Iterative RaLM approaches frequently query external knowledge bases during generation (e.g., every token or sentence), causing severe latency bottlenecks due to sequential retrieval overhead.
Why it matters:
- Iterative RAG achieves higher generation quality than one-shot RAG but is often practically unusable due to prohibitive latency (e.g., KNN-LM retrieves per token)
- Standard serving executes retrieval and generation sequentially; for exact dense retrievers, retrieval time often dominates end-to-end latency
- Existing optimizations like automaton-augmented retrieval may compromise generation quality; lossless acceleration is needed
Concrete Example:
In standard iterative RAG, generating a sentence might require 3 sequential retrieval steps (q0→DocA, q1→DocB, q2→DocA). This halts generation 3 times. RaLMSpec speculatively reuses DocA from a local cache for q2, allowing the model to proceed, and verifies all 3 queries in a single batched parallel step later.
Key Novelty
Speculative Retrieval with Batched Verification (RaLMSpec)
- Leverages 'temporal/spatial locality': consecutive retrieval steps often return the same or adjacent documents, allowing a small local cache to act as a high-speed speculative retriever
- Replaces sequential knowledge base queries with fast local cache lookups, running generation speculatively until a 'verification step' is triggered
- Performs 'batched verification': sends accumulated queries to the external database in one parallel batch, correcting the output only if the speculation (local cache result) mismatches the ground truth
Architecture
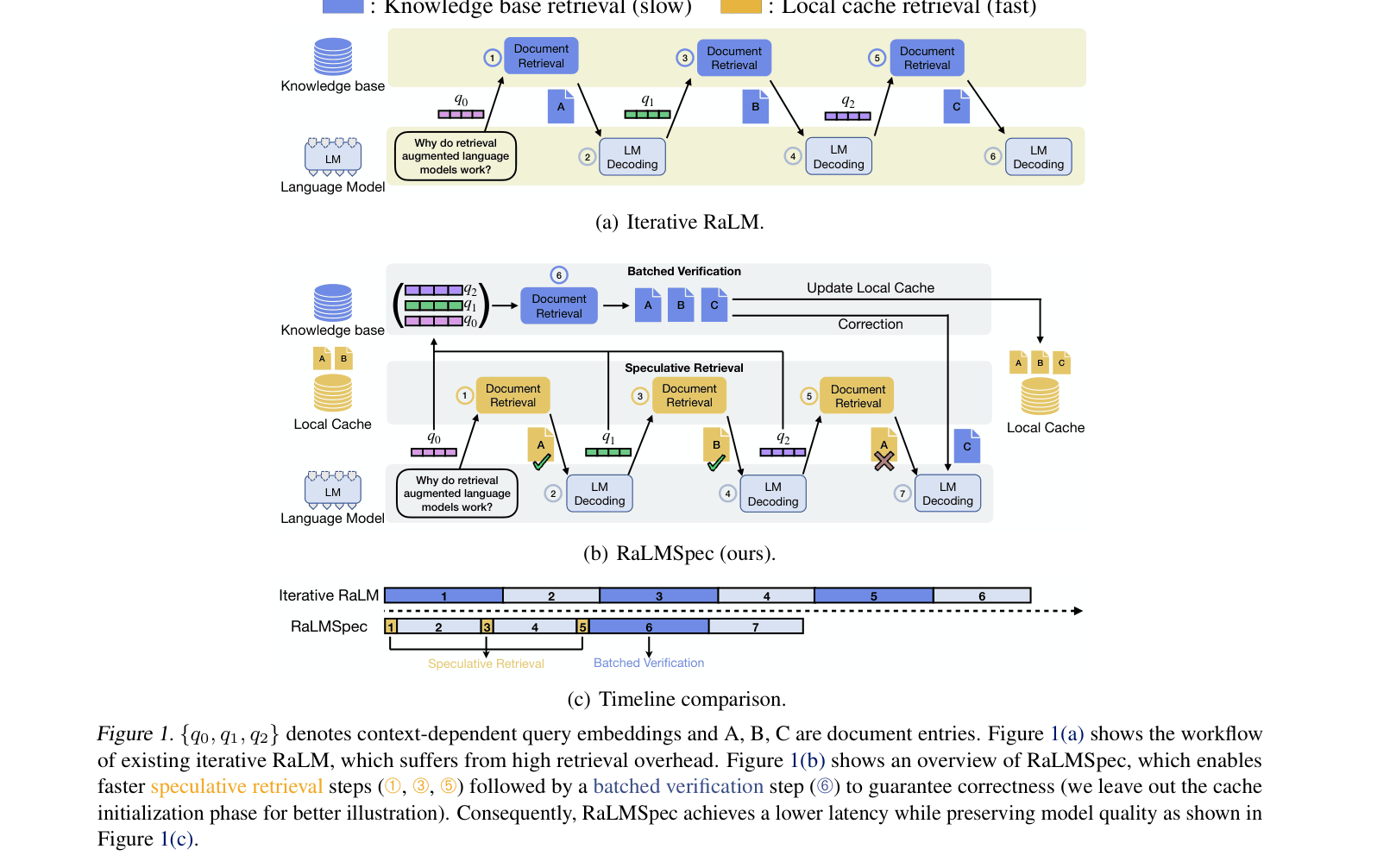
The speculative retrieval pipeline showing the interaction between the language model, local cache, and external knowledge base.
Evaluation Highlights
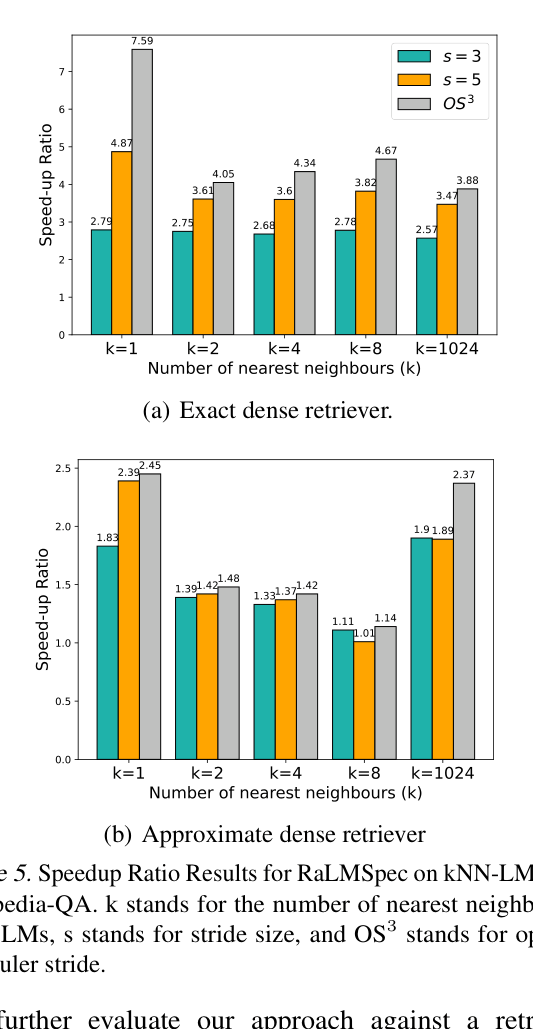
- Up to 2.39× speedup for document-level iterative RAG (GPT-2) using an Exact Dense Retriever (EDR) on Wiki-QA
- Up to 7.59× speedup for token-level iterative RAG (KNN-LM) using an Exact Dense Retriever
- Consistent speedups across 3 models (GPT-2, OPT, LLaMA-2) and 3 retriever types (Exact Dense, Approx Dense, Sparse), with provably identical model outputs
Breakthrough Assessment
7/10
Novel application of speculative execution to the *retrieval* component rather than just decoding. Provides significant, lossless speedups for a specific but high-cost class of models (iterative RAG).