📝 Paper Summary
Extreme Multi-label Text Classification (XMC)
Zero-shot Learning
LMTX trains a lightweight bi-encoder for extreme classification by using a large language model to filter and identify high-quality pseudo-positive labels from a shortlist, eliminating LLM inference costs.
Core Problem
Existing Extreme Zero-shot XMC (EZ-XMC) methods rely on noisy pseudo-labels (like document titles or random segments) that misalign with target tasks, while direct LLM inference is too computationally expensive for large-scale tagging.
Why it matters:
- Real-world systems (e.g., product tagging) face cold-start problems where new labels emerge dynamically without annotated data
- Current lightweight methods use signals (like random spans) that lack semantic alignment with categorization tasks
- Deploying massive LLMs for real-time inference on millions of labels is cost-prohibitive
Concrete Example:
In previous methods like RTS, a document is split into two random segments, treating one as the 'label' for the other. These segments may be semantically unrelated if far apart, creating noisy training signals. LMTX instead asks an LLM: 'Is tag X relevant to document Y?', filtering out bad matches.
Key Novelty
Large Language Model as Teacher for eXtreme classification (LMTX)
- Uses a curriculum-based iterative loop: a bi-encoder retrieves candidate labels, and an LLM acts as a 'teacher' to verify which candidates are actually relevant
- Filters noisy candidates into high-quality pseudo-positives using the LLM's zero-shot reasoning capabilities ('Yes/No' relevance check)
- Distills LLM knowledge into a lightweight bi-encoder, allowing the expensive teacher to be discarded during final inference
Architecture
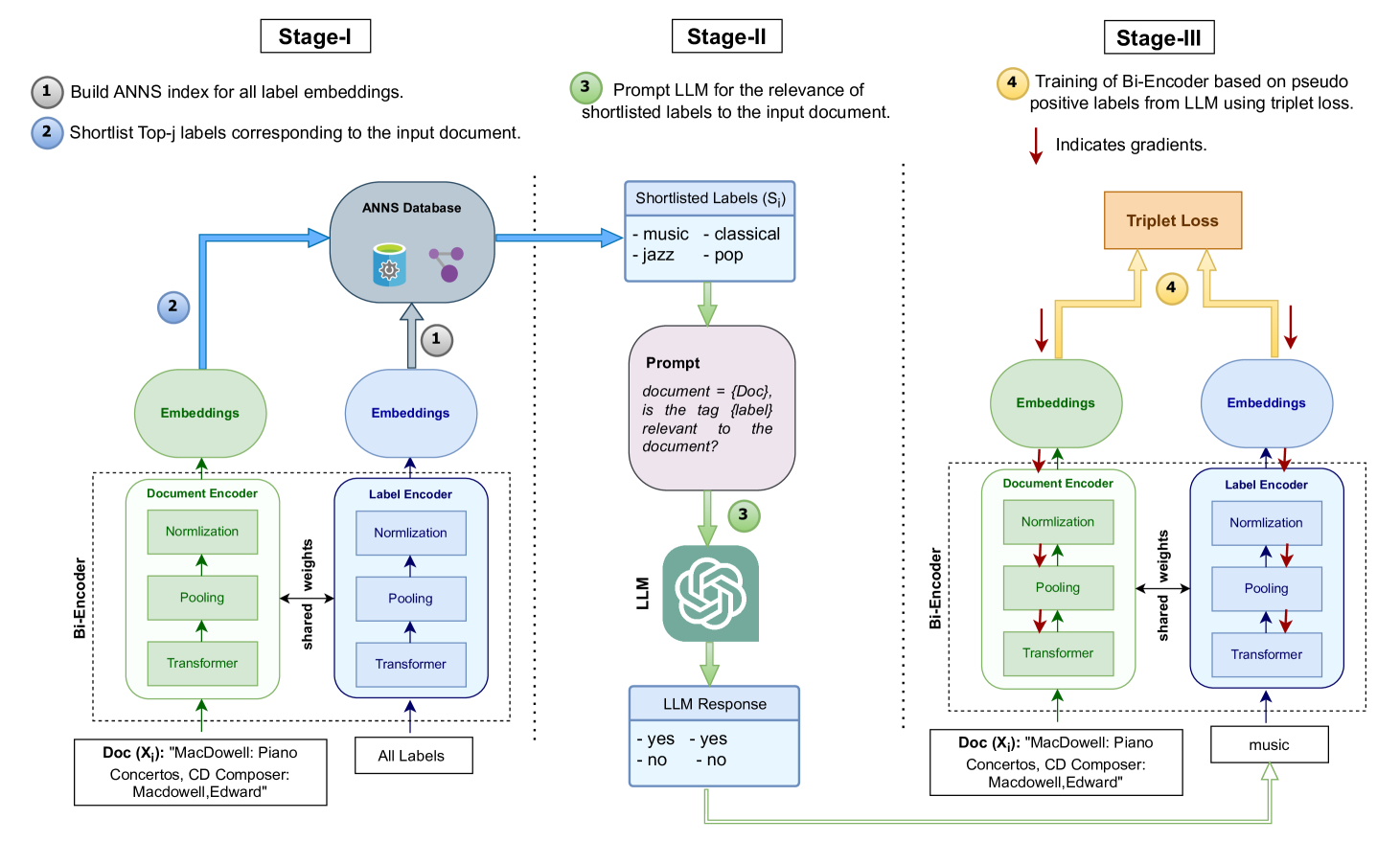
The iterative training framework of LMTX involving three stages: Shortlist Generation, LLM Teacher Filtering, and Bi-encoder Training.
Evaluation Highlights
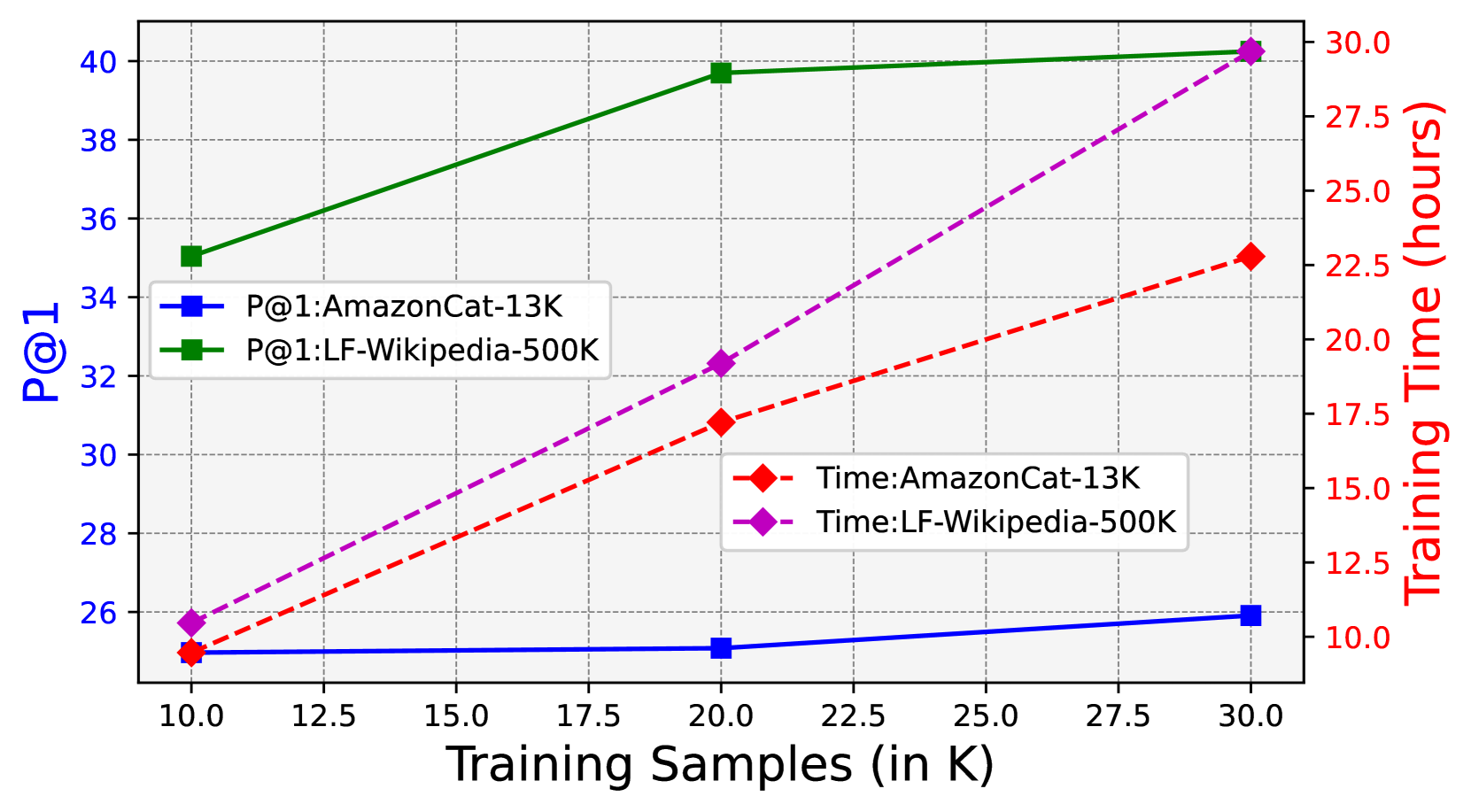
- +31% improvement in Precision@1 on LF-Wikipedia-500K compared to state-of-the-art non-LLM baselines
- +37% improvement in Precision@1 on AmazonCat-13K compared to state-of-the-art non-LLM baselines
- Significantly outperforms direct LLM inference (ICXML) on EURLex-4K (P@1 47.28 vs 19.14) while being orders of magnitude faster
Breakthrough Assessment
8/10
Establishes a new state-of-the-art in zero-shot extreme classification by effectively bridging the gap between high-quality LLM reasoning and the efficiency of bi-encoders, addressing a critical scalability bottleneck.