📝 Paper Summary
LLM Evaluation Frameworks
Prompt Engineering / Optimization
Integrating structured prompting (DSPy) into the HELM framework reveals that standard fixed-prompt benchmarks significantly underestimate LM performance and misrepresent model rankings compared to optimized prompt baselines.
Core Problem
Standard benchmarks like HELM typically use fixed, hand-crafted zero-shot prompts, which fail to generalize across different LMs and underestimate their true capabilities (performance ceiling).
Why it matters:
- Fixed prompts lead to unrepresentative performance estimates, obscuring true model strengths and weaknesses
- Inaccurate benchmarks cause leaderboard rankings to flip, misleading practitioners making deployment decisions
- Without approximating the performance ceiling, it is unclear if errors are due to model limitations or suboptimal prompting
Concrete Example:
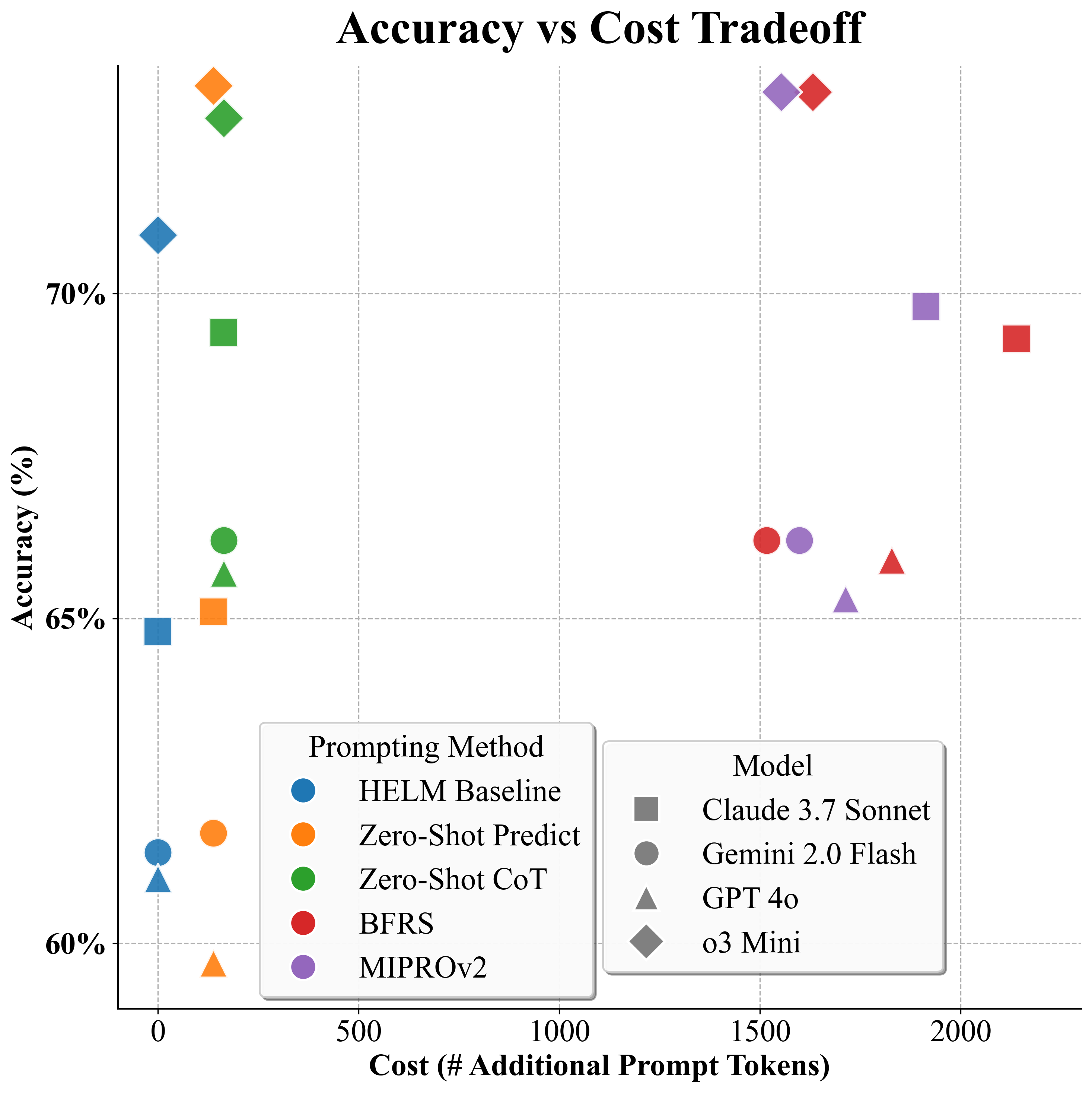
On the GSM8K math benchmark, the leaderboard ranking flips when moving from fixed prompts to optimized ones: GPT-4o overtakes Gemini 2.0 Flash (90.7% vs 84.2%) compared to the baseline where Gemini led (84.0% vs 81.1%).
Key Novelty
Reproducible DSPy+HELM Integration
- Systematically integrates DSPy's structured prompting and automatic optimizers (BFRS, MIPROv2) into the HELM evaluation suite to approximate performance ceilings
- demonstrates that introducing Chain-of-Thought (CoT) reasoning acts as a stabilizer, reducing the variance in model performance caused by prompt wording changes
- Provides a rigorous comparison of four frontier LMs across seven benchmarks using three distinct levels of prompt optimization (Zero-Shot CoT, Few-Shot Search, Bayesian Optimization)
Architecture
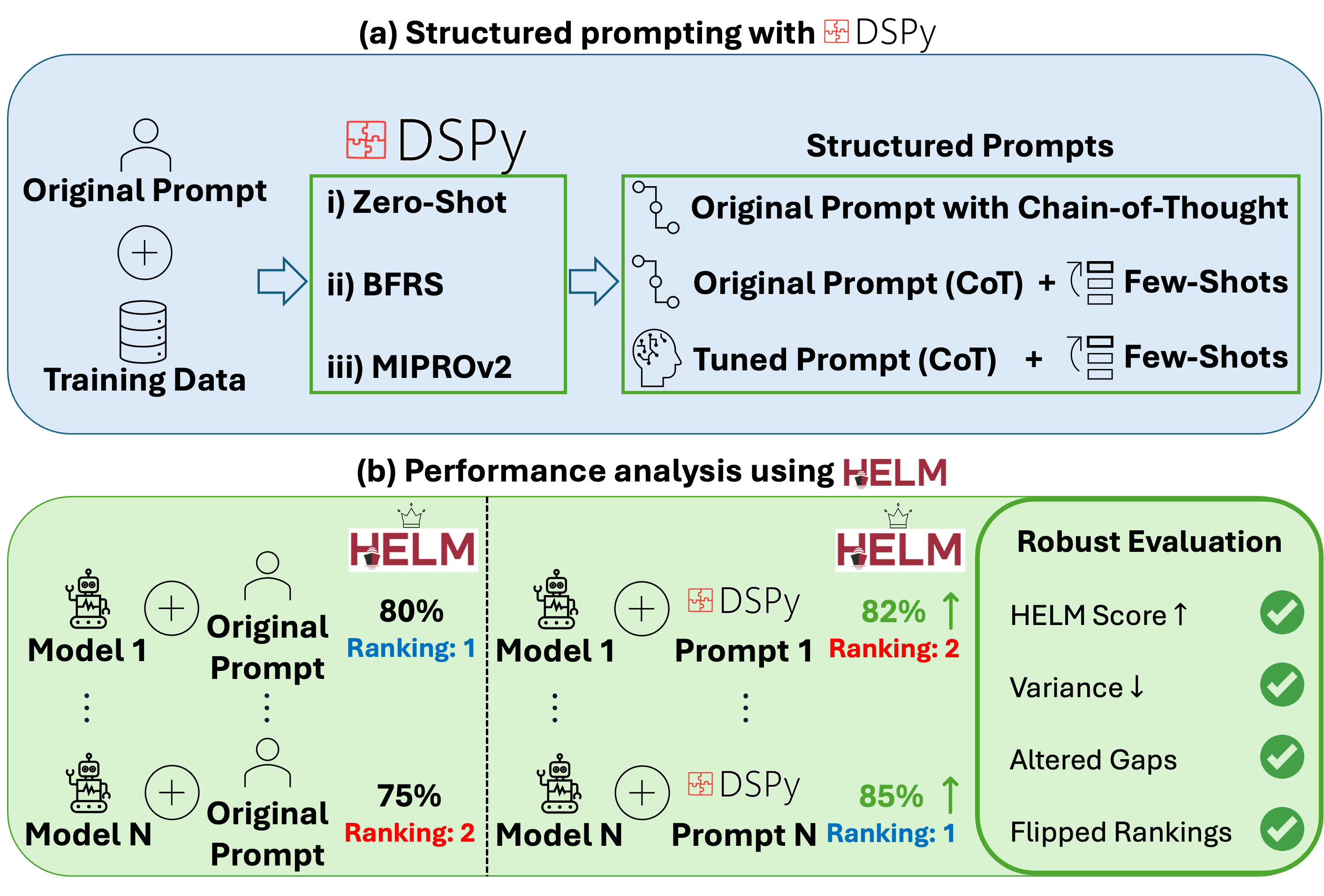
The DSPy+HELM framework integration workflow.
Evaluation Highlights
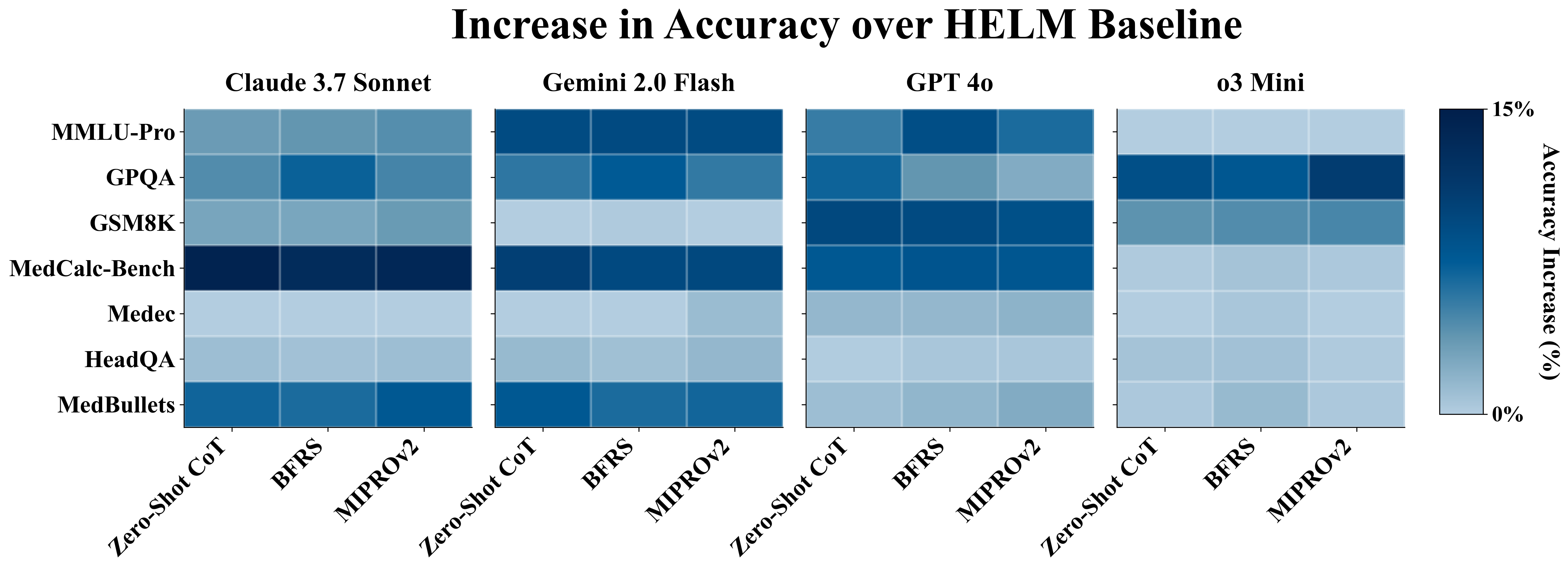
- Structured prompting improves LM performance by an average of +4% absolute accuracy across 7 benchmarks compared to HELM baselines
- Leaderboard rankings flip on 3 out of 7 benchmarks when using optimized prompts instead of fixed baselines
- Optimized prompting reduces performance variance across benchmarks for most models (e.g., Claude 3.7 Sonnet standard deviation drops 22.6% → 18.8%)
Breakthrough Assessment
8/10
Strong empirical evidence that static benchmarks are insufficient. The integration of DSPy into HELM offers a scalable path to fairer, 'ceiling-based' evaluation, challenging current leaderboard paradigms.