📊 Experiments & Results
Evaluation Setup
Evaluated on diverse vision-language benchmarks including captioning, VQA, document understanding, and video tasks.
Benchmarks:
- COCO Captions (Image Captioning)
- VQAv2 (Visual Question Answering)
- OKVQA (Knowledge-based VQA)
- TextVQA (OCR-based VQA)
- ChartQA (Chart Understanding)
- TallyQA (Counting VQA)
Metrics:
- CIDEr (Captioning)
- Accuracy (VQA)
- Top-1 Accuracy (ImageNet)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| VQAv2 (test-std) | Accuracy | 84.3 | 86.1 | +1.8 |
| OKVQA | Accuracy | 57.8 | 66.1 | +8.3 |
| TallyQA (complex) | Accuracy | 56.8 | 75.6 | +18.8 |
| TextVQA | Accuracy | 73.3 | 74.6 | +1.3 |
| AI2D | Accuracy | 42.1 | 81.2 | +39.1 |
| ChartQA | Accuracy | 58.6 | 70.9 | +12.3 |
| COCO Captions (Karpathy test) | CIDEr | 113.8 | 114.5 | +0.7 |
| MSR-VTT-QA | Accuracy | 48.0 | 47.1 | -0.9 |
| ActivityNet-QA | Accuracy | 52.5 | 54.9 | +2.4 |
| ImageNet | Top-1 Accuracy | 89.22 | 89.19 | -0.03 |
Experiment Figures
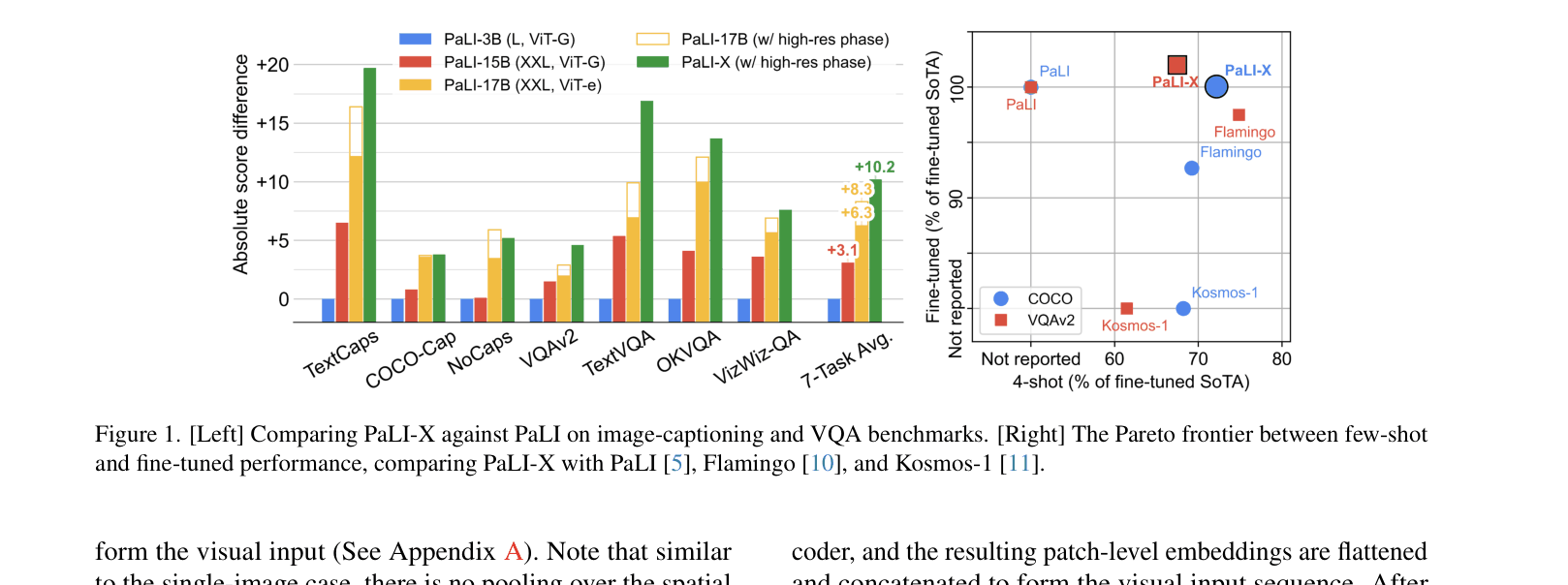
Comparison of PaLI-X vs PaLI on standard benchmarks (Left) and the Pareto frontier of Few-shot vs Fine-tuned performance (Right).

Qualitative examples of object detection capabilities demonstrating multilingual transfer.
Main Takeaways
- Scaling both vision and language components jointly is superior to scaling them unilaterally.
- Multitask fine-tuning yields performance on par with single-task fine-tuning, allowing a single model to handle diverse tasks effectively.
- OCR-specific pretraining (Pix2Struct, Split-OCR) significantly boosts performance on text-rich tasks like ChartQA and AI2D.
- Emergent capabilities such as complex counting and multilingual object detection appear at this scale without explicit targeted training.
- Tension exists between few-shot capability and fine-tuning: while PaLI-X excels at few-shot captioning, fine-tuning the language backbone slightly hurts few-shot VQA compared to frozen-backbone models.