📝 Paper Summary
Language Model Pre-training
Loss Functions
Class Imbalance in NLP
MiLe Loss dynamically scales training gradients based on the entropy of the predicted probability distribution to focus learning on infrequent, difficult-to-learn tokens rather than easy, frequent ones.
Core Problem
Language models are dominated by frequent, easy-to-learn tokens due to Zipfian distributions in training data, causing them to neglect infrequent, informative tokens.
Why it matters:
- Standard Cross-Entropy Loss treats all tokens equally, allowing the vast number of easy tokens to overwhelm the training signal
- Existing solutions like Focal Loss fail in language modeling because next-token prediction is often a multi-label problem (multiple valid next tokens), not a single-class problem
- Models trained on imbalanced data exhibit high perplexity on rare tokens, indicating poor understanding of the 'long tail' of language
Concrete Example:
Given 'I like playing ___', valid completions include 'basketball', 'football', and 'golf'. If 'basketball' is the target, it has low probability (e.g., 0.18) because probability mass is split among valid options. Focal Loss misinterprets this low probability as 'difficult' and upweights it excessively, even though the model isn't actually confused—it just sees multiple valid options.
Key Novelty
Entropy-based Dynamic Loss Scaling
- Use the information entropy of the model's predicted probability distribution to assess difficulty, rather than just the target token's probability
- High entropy implies the model is unsure (distribution is flat), indicating a truly difficult-to-learn token; low entropy implies the model is confident (distribution is peaked), indicating an easy token
- Scale the loss weight proportionally to this entropy, forcing the model to pay more attention to uncertain, difficult contexts
Architecture
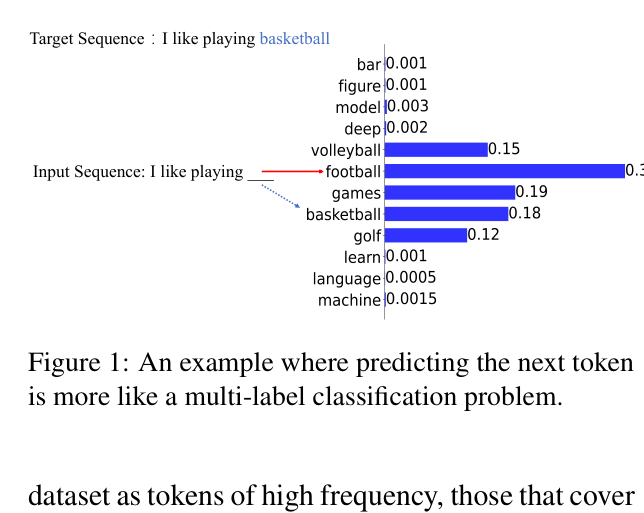
Conceptual illustration of the 'Next Token Prediction as Multi-Label Classification' problem.
Evaluation Highlights
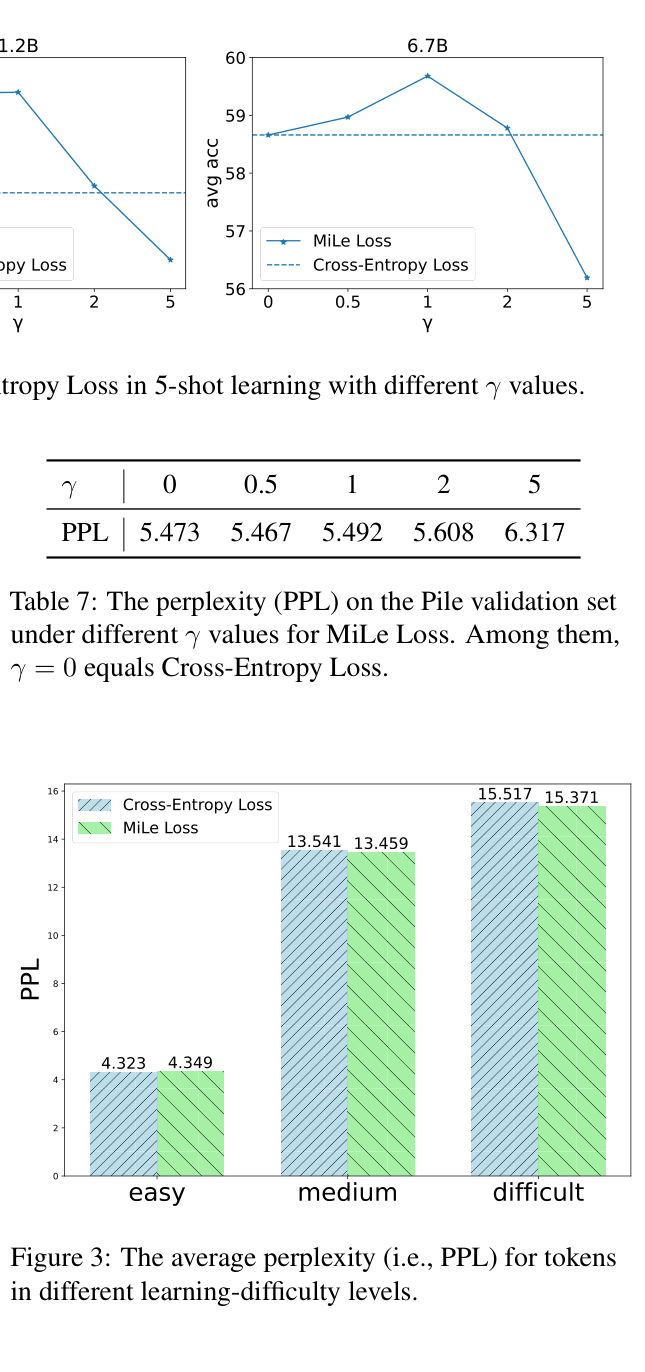
- Consistent gains across 8 common sense reasoning benchmarks: 6.7B model with MiLe Loss improves +1.02% average accuracy over Cross-Entropy baseline in 5-shot setting
- +4.17% improvement in Zero-shot Exact Match on TriviaQA (6.7B model) compared to Focal Loss
- Reduces perplexity specifically for 'medium' and 'difficult' frequency tokens (e.g., from 15.517 to 15.371 for difficult tokens) while maintaining performance on easy tokens
Breakthrough Assessment
6/10
A solid, mathematically grounded improvement over Cross-Entropy for LM pre-training. While the gains are consistent, they are relatively modest (1-2%). The entropy-based insight for multi-label ambiguity is clever.